周志华提出的gcForest能否取代深度神经网络?

摘要:
最近周志华教授从深度神经网络的深层含义说起,条分缕析地总结出神经网络取得成功的三大原因:
有逐层的处理
有特征的内部变化
有足够的模型复杂度
并得出结论:如果满足这三大条件,则并不一定只能用深度神经网络。
由于神经网络存在的一些缺陷,很多时候人们不得不考虑其他的模型。周志华介绍了他所领导的团队提出的 gcforest 方法,称该方法有良好的跨任务表现、自适应的模型复杂度等优势。
而对于 gcforest 研究的重要意义,正如周志华在分享中表示的那样,深度学习是一个黑屋子,以前大家都知道它里面有深度神经网络,现在我们把这个屋子打开了一扇门,把 gcforest 放进来,我想以后可能还有更多的东西,这是这个工作从学术科学发展上更重要的价值所在。
什么是gcFores模型:
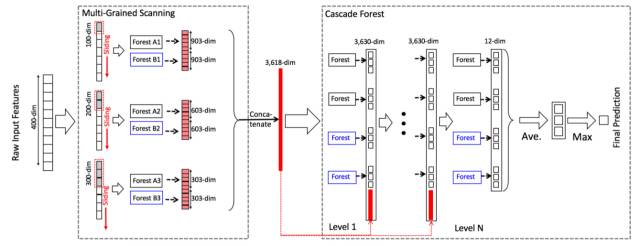
周教授在(《Deep Forest: Towards An Alternative to Deep Neural Networks》)中提出了一个多粒度的级联随机森林(gcForest)的模型,所谓多粒度,就是好比卷积神经网络中的多个不同大小的filter同时作用到输入数据上,即选取了不同规模的局部特征;而级联随机森林就是将多个随机森林排在一层,然后再传给下一层的随机森林。gcForest在小数据集的手写字识别、人脸识别、音乐分类等任务上取得了与深度神经网络相媲美甚至好很多的效果,尤其是对于非常小的数据集而言。首先请看以下实验结果:
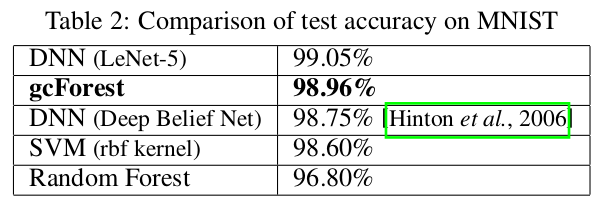
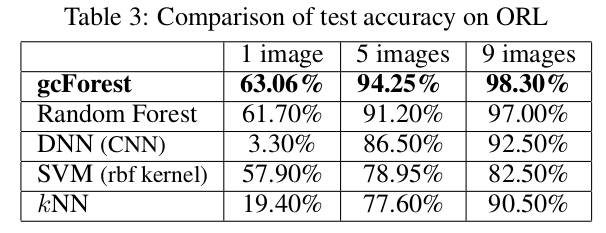
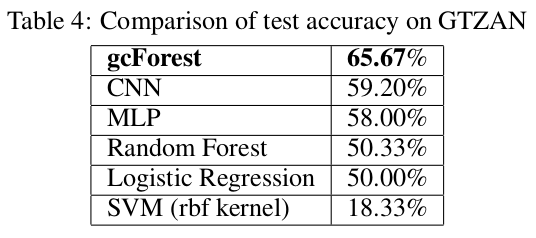
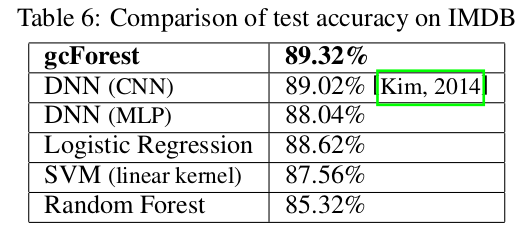
首先,这篇文章立意新颖,绕开了当前主流的神经网络模型,将随机森林的集成学习方法应用到一些小数据的分类任务上。但是从模型上看,并没有多大创新之处,毕竟随机森林、集成学习用于分类任务的成功案例在Kaggle上数不胜数。
这篇文章字里行间充满着对神经网络的尴尬和无奈,看下面这幅图大概就明白了,图中一堆问号代表着作者对当下神经网络的无奈,相信这也是我们大多人内心的真是想法,以前论文中都是直接给出最优的超参数,具体怎么来的实在让人费解。这篇文章中作者勇敢地指出来了,这也是作者为什么要提出这个gcForest模型的用意吧,希望以较小的计算资源和较少的调参时间来获得更好的效果,从而可以为深度学习开启另外一扇门。

作者还指出,gcForest建立好一个模型以后,可以直接应用到多个任务上,无需改变网络结构,而这一点让目前的神经网络望尘莫及,原因一个卷积神经网络在A图片数据集上训练好之后,很难直接应用于B图片数据集,性能会骤降。
文中还指出,在探讨了“多粒度”与“级联随机森林”哪个贡献比较大时,得出的结论是“多粒度”对模型性能的提升帮助比较大,表明在机器学习中特征选取是十分重要的,这一点对于深度学习也是同样重要。
如上图所示,就是gcForest的模型结构,看上去十分简单,只要理解了随机森林的算法,gcForest的工作原理也就明白了。
这篇文章是将深度随机森林应用与小规模数据集上的实验论文,对于更大的数据集上的实验效果以及严格的理论分析,作者以“计算资源有限、时间仓促”草草了之,再等等吧!
至于gcForest甚至是集成学习能否取代深度神经网络?仁者见仁智者见智,不过以目前深度神经网络的发展势头和应用效果来看,即使要追上也不是三两天就可以完成的。
作者用一堆问号勇敢地指出神经网络的尴尬与无奈,也许这才是这篇论文的成功之处吧!
来自:深度学习每日摘要,AI科级大本营
作者:张泽旺
-今晚直播预告-

点击“阅读原文”,查看详情





