周志华:满足这三大条件,可以考虑不用深度神经网络

来源: AI科技大本营
摘要:4 月 15 日举办的京东人工智能创新峰会上,刚刚上任京东人工智能南京分院学术总顾问的周志华教授做了《关于深度学习一点思考》的公开分享。
近年来,深度神经网络在语音、图像领域取得突出进展,以至于很多人将深度学习与深度神经网络等同视之。但周志华表示,总结 Kaggle 竞赛中的获奖结果可以发现,神经网络获胜的往往就是在图像、视频、声音这几类典型任务上,而在其它涉及到混合建模、离散建模、符号建模的任务上,相比其他模型就会差一些。
为什么会产生这样的结果?周志华从深度神经网络的深层含义说起,条分缕析地总结出神经网络取得成功的三大原因:
有逐层的处理
有特征的内部变化
有足够的模型复杂度
并得出结论:如果满足这三大条件,则并不一定只能用深度神经网络。
由于神经网络存在的一些缺陷,很多时候人们不得不考虑其他的模型。周志华介绍了他所领导的团队提出的 gcforest 方法,称该方法有良好的跨任务表现、自适应的模型复杂度等优势。
而对于 gcforest 研究的重要意义,正如周志华在分享中表示的那样,深度学习是一个黑屋子,以前大家都知道它里面有深度神经网络,现在我们把这个屋子打开了一扇门,把 gcforest 放进来,我想以后可能还有更多的东西,这是这个工作从学术科学发展上更重要的价值所在。
周志华教授是美国计算机学会 (ACM)、美国科学促进会 (AAAS)、国际人工智能学会 (AAAI) 、国际电气电子工程师学会 (IEEE) 、国际模式识别学会 (IAPR)、国际工程技术 (IET/IEE) 等学会的会士,实现了 AI 领域会士大满贯,也是唯一一位在中国大陆取得全部学位的 AAAI 会士,对于机器学习中的集成学习、多标记学习与半监督学习有着卓越的贡献。他还一手参与创建了南京大学人工智能学院并担任院长。
下面是演讲全文:
各位可能最近都听说我们南京大学成立了人工智能学院,这是中国 C9 高校的第一个人工智能学科。今天就跟大家谈一谈我们自己对于深度学习的一点点非常粗浅的看法,仅供大家批评讨论。
▌什么是深度学习?
我们都知道现在人工智能很热,掀起这股的热潮最重要的技术之一就是深度学习技术。今天当我们谈到深度学习的时候,其实已经可以看到在各种各样的应用,包括图像、视频、声音、自然语言处理等等。如果我们问一个问题,什么是深度学习?大多数人基本会认为,深度学习差不多就等于深度神经网络。

比如说这么一个计算模型,实际上半个多世纪以前我们就已经总结出来了。我们收到一些输入,这些输入通过一些连接放大,到了细胞之后,它的“加和”如果超过一个阈值,这个细胞就激活了。实际上说穿了就是这么一个非常简单的公式,所谓的神经网络就是很多这样的公式通过嵌套迭代得到的一个数学系统。
今天我们说深度神经网络的时候指的是什么?其实简单来说就是用的神经网络有很多层,很深很深。大概多少?看一个数据,2012 年深度学习刚刚受到大家的重视的时候,一个 ImageNet 竞赛的冠军用了 8 层,2015 年 152 层,2016 年 1207 多层,这是一个非常庞大的系统。
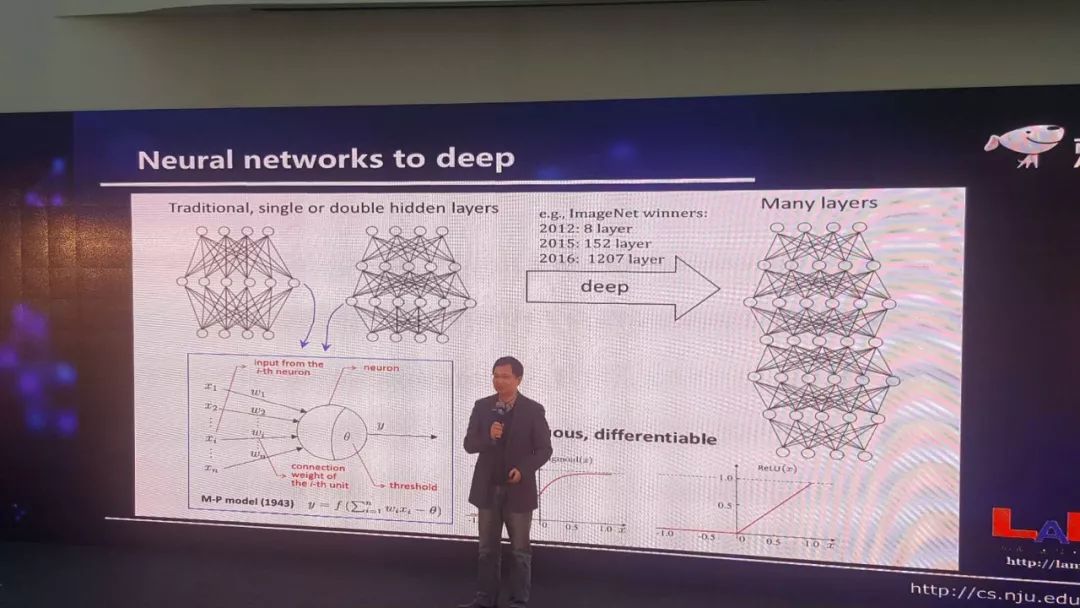
要把这个系统训练出来难度非常大,但有一个非常好的消息,真正的神经网络里面的计算单元,它最重要的激活函数是连续的,是可微的。以前在神经网络里面我们经常用 Sigmoid,它是连续可微的,现在在深度神经网络里,我们经常用 tanh 或者 tanh 的变体,它也是连续可微的。有了这么一个性质以后,我们会得到一个非常好的结果,这个结果就是现在我们可以很容易计算系统的梯度。因此就可以很容易用著名的 BP 算法(注:反向传播算法)来训练这系统。
关于深度神经网络为什么能深,其实这件事情到今天为止学术界都没有统一的看法。在这里面给大家讲一个我们前一段时间给出的论述,这个论述其实是从主要模型的复杂度的角度来讨论的。
▌深度学习成功的关键是什么?
对神经网络这样的模型来说有两条很明显的途径,一条是我们把模型变深,一条是我们把它变宽,但是如果从提升复杂度的角度,变深会更有效。当你变宽的时候你只不过增加了一些计算单元、增加了函数的个数,而在变深的时候不仅增加了个数,其实还增加了嵌入的层次,所以泛函的表达能力会更强。所以从这个角度来说,我们应该尝试变深。

大家可能就会问了,既然要变深,你们不早就知道这件事了吗?为什么现在才开始做呢?其实这就涉及到另外一个问题,我们在机器学习里面把学习能力变强了,这其实未必真的是一件好事。因为我们机器学习一直在斗争的一个问题,就是我们经常会碰到过拟合。
给定一个数据集,我们希望把数据集里的东西学出来,但是有时候可能把这个数据本身的一些特性学出来了,而这个特性却不是一般的规律。当把学出来的错误东西当成一般规律来用的时候,就会犯巨大的错误,这种现象就是过拟合。为什么会把数据本身的特性学出来?就是因为我们的模型学习能力太强了。

在一年多之前,我们把这个解释说出来的时候,其实国内外很多同行也很赞同这么一个解释,因为大家觉得这听起来蛮有道理的,其实我一直对这个不是特别满意,这是为什么?其实有一个潜在的问题我们一直没有回答。如果从复杂度解释的话,我们就没有办法说为什么扁平的或者宽的网络做不到深度神经网络的性能?因为事实上我们把网络变宽,虽然它的效率不是那么高,但是它同样也能起到增加复杂度的能力。
实际上我们在 1989 年的时候就已经有一个理论证明,说神经网络有万有逼近能力:只要你用一个隐层,就可以以任意精度逼近任意复杂度的定义在一个紧集上的连续函数。
其实不一定要非常深。这里面我要引用一个说法,神经网络有万有逼近能力,可能是有的人会认为这是导致神经网络为什么这么强大的一个主要原因,其实这是一个误解。
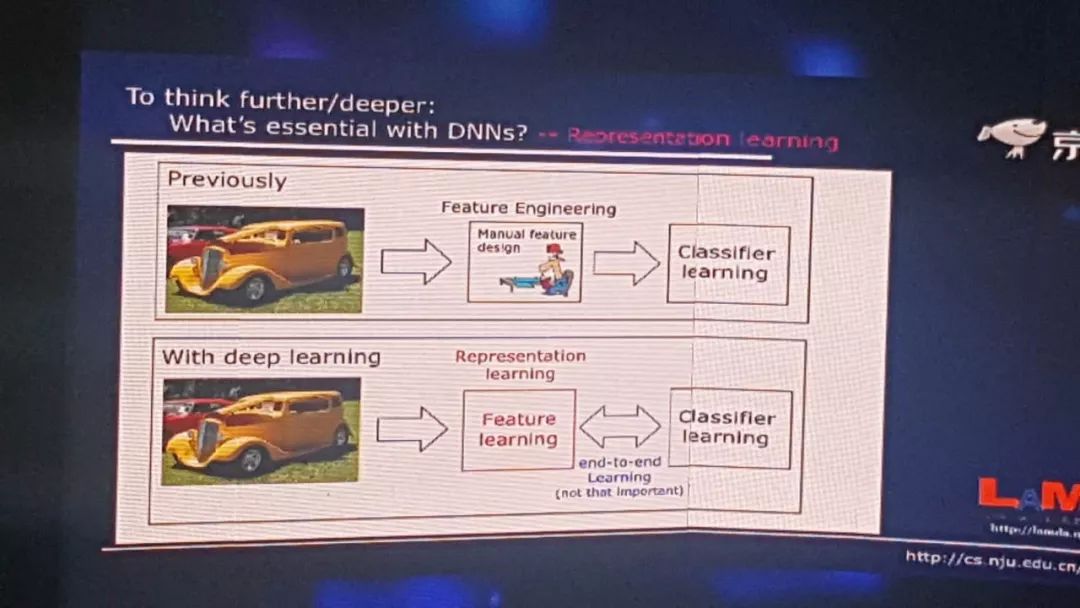
所以我们要问这么一个问题:深度神经网络里面最本质的东西到底是什么?今天我们的答案可能是要做表示学习的能力。以往我们用机器学习,首先拿到一个数据,比如这个数据对象是一个图像,我们就用很多特征把它描述出来,比如说颜色、纹理等等,这一些特征都是我们人类专家通过手工来设计的,表达出来之后我们再去进行学习。
而今天我们有了深度学习之后,现在不再需要手工设计特征,把数据从一端扔进去,模型从另外一端出来,中间所有的特征完全通过学习自己来解决,这是所谓的特征学习或者表示学习,这和以往的机器学习技术相比是一个很大的进步,我们不再需要完全依赖人类专家去设计特征了。
我们再问下一个问题,表示学习最关键的又是什么?对这件事情我们现在有这么一个答案,就是逐层的处理。现在我们就引用非常流行的《深度学习》一书里的一张图,当我们拿到一个图像的时候,如果我们把神经网络看作很多层的时候,首先在最底层我们看到是一些像素的东西,当我们一层一层往上的时候,慢慢的有边缘,再往上有轮廓等等,在真正的神经网络模型里不一定有这么清晰的分层,但总体上确实是在往上不断做对象的抽象。
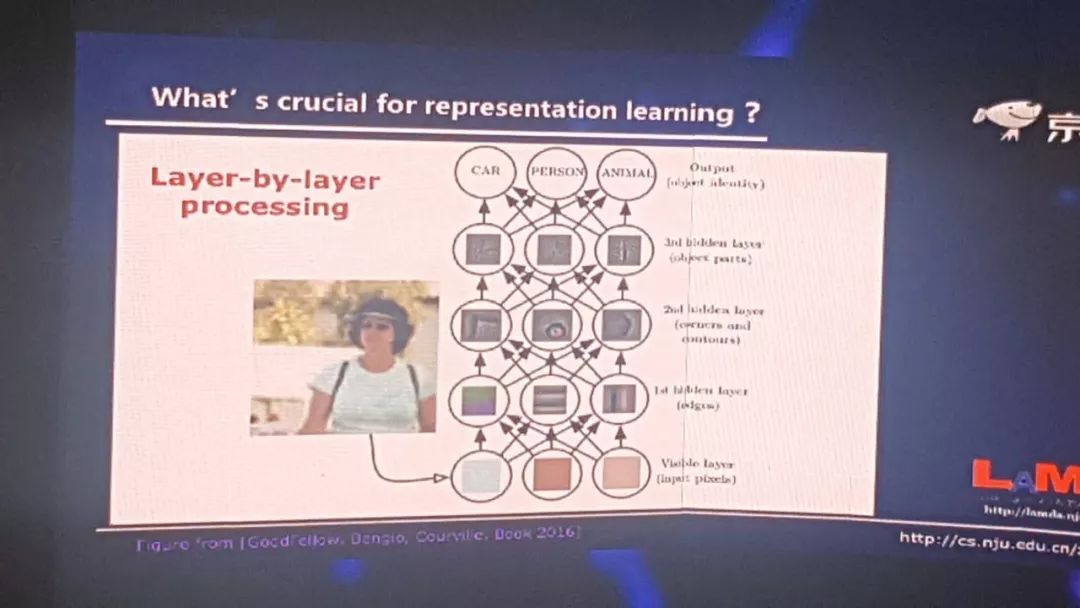
而这个特点,我们现在认为这好像是深度学习真正成功的关键因素之一,因为扁平神经网络能做很多深层神经网络所做的事,但是有一点它做不到:当它是扁平的时候,就没有进行一个深度加工,所以深度的逐层抽象可能很关键。那如果我们再看一看,大家可能就会问,其实逐层处理这件事,在机器学习里也不是一个新东西。
大家如果对高级一点的机器学习模型有所了解,你可能会问,现在很多 Boosting 模型也是一层一层往下走,为什么它没有取得深度学习的成功?我想问题其实差不多,首先复杂度还不够,第二,更关键的一点,它始终在原始空间里面做事情,所有的这些学习器都是在原始特征空间,中间没有进行任何的特征变换。
深度神经网络到底为什么成功?里面的关键原因是什么?我想首先我们需要两件事,第一是逐层地处理,第二我们要有一个内部的特征变换。而当我们考虑到这两件事情的时候,我们就会发现,其实深度模型是一个非常自然的选择。有了这样的模型,我们很容易可以做上面两件事。但是当我们选择用这么一个深度模型的时候,我们就会有很多问题,它容易 overfit,所以我们要用大数据,它很难训练,我们要有很多训练的 trick,这个系统的计算开销非常大,所以我们要有非常强有力的计算设备,比如 GPU 等等。
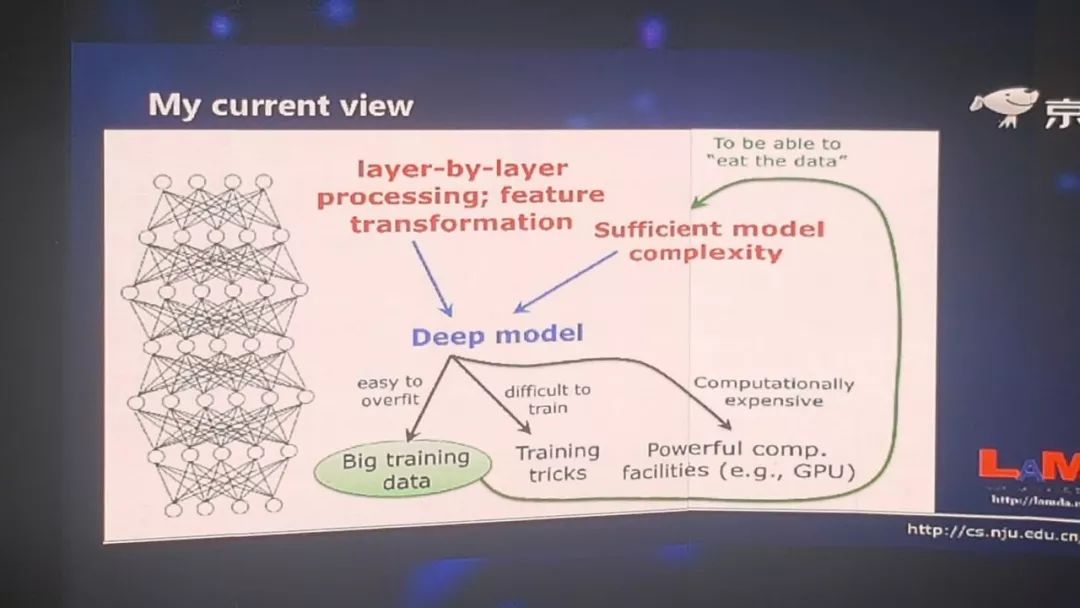
实际上所有这些东西是因为我们选择了深度模型之后产生的一个结果,他们不是我们用深度学习的原因。所以这和以往我们的思考不太一样,以往我们认为有了这些东西,导致我们用深度模型,现在我们觉得这个因果关系恰恰是反过来的——因为我们要用它,所以我们才会考虑上面的这些东西。

▌深度神经网络的缺陷
我们就要想一想,我们有没有必要考虑神经网络之外的模型?其实是有的。因为大家都知道神经网络有很多缺陷。
第一,凡是用过深度神经网络的人都知道,你要花大量的精力来调它的参数,因为这是一个巨大的系统。这里面会带来很多问题,首先当我们调参数的时候,这个经验其实是很难共享的。有的朋友可能说,我在第一个图像数据集之上调数据的经验,当我用第二个图像数据集的时候,这个经验肯定可以重用的。但是我们有没有想过,比如说我们在图像方面做了一个很大的神经网络,这时候如果要去做语音,其实在图像上面调参数的经验,在语音问题上可能基本上不太有借鉴作用,所以当我们跨任务的时候,经验可能就很难有成效。
而且还带来第二个问题,我们今天都非常关注结果的可重复性,不管是科学研究、技术发展,都希望这结果可重复,而在整个机器学习领域里面,深度学习的可重复性是最弱的。我们经常会碰到这样的情况,有一组研究人员发文章报告了一个结果,而这结果其他的研究人员很难重复。因为哪怕你用同样的数据、同样的方法,只要超参数的设计不一样,你的结果就不一样。
我们在用深度神经网络的时候,模型的复杂度必须事先指定,因为在训练模型之前,神经网络是什么样就必须定了,然后才能用 BP 算法等等去训练它。其实这就会带来很大的问题,因为在没有解决这个任务之前,我们怎么知道这个复杂度应该有多大呢?所以实际上大家做的通常都是设更大的复杂度。

如果我们看上面的获胜者,今天很多还不是神经网络,很多是像随机森林等这样的模型。如果我们真的仔细去关注,真的神经网络获胜的往往就是在图像、视频、声音这几类典型任务上,而在其它涉及到混合建模、离散建模、符号建模的任务上,其实神经网络的性能比其它模型还要差一些。
所以如果我们从一个学术的角度重新总结下这件事,我们就可以看到,今天我们谈到的深度模型基本上都是深度神经网络。如果用术语来说的话,它是多层可参数化的可微分的非线性模块所组成的模型,而这个模型可以用 BP 算法来训练。
那么这里面有两个问题:第一,我们现实世界遇到的各种各样的问题的性质,并不是绝对都是可微的,或者能够用可微的模型做最佳建模;第二,过去几十年里面,我们的机器学习界做了很多很多模型出来,这些都可以作为我们构建一个系统的基石,而中间有相当一部分模块是不可微的。

那么这些能不能用来构建深度模型?能不能通过构建深度模型之后得到更好的性能呢?能不能通过把它们变深之后,使得今天深度模型还打不过随机森林这一些模型的任务,能够得到更好的结果呢?
所以我们现在有一个很大的挑战,这不光是学术上也是技术上的挑战,就是我们能不能用不可微的模块来构建深度模型。

其实这个问题一旦得到回答,我们同时就可以得到好多其他问题的回答。比如说深度模型是不是就是深度神经网络?我们能不能用不可微的模型把它做深,这个时候我们不能用 BP 算法来训练,同时我们能不能让深度模型在更多的任务上获胜。这个问题其实我们提出来之后在国际上也有一些学者提出了一些相似看法。比如大家都知道深度学习非常著名的领军人物 Geoffrey Hinton 教授,他也提出来希望深度学习以后能不能摆脱 BP 算法来做,他提出这个想法比我们要更晚一些。所以我想这一些问题是站在很前沿的角度上做的探索。
那我们自己就受到这样的一个启发,我们要考虑这三件事,就是刚才跟大家分析得到的三个结论:第一要做逐层处理,第二是特征的内部变换,第三我们希望得到一个充分的模型复杂度。
▌深度森林
我自己领导的研究组最近在这一方面做了一些工作,我们最近提出了一个 深度森林的方法。

还有一个很重要的特性,它有自适应的模型复杂度,可以根据数据的大小自动来判定该模型长到什么程度。它的中间有很多好的性质,有很多朋友可能也会下载我们的开源代码拿去试,到时候我们会有更大规模分布式的版本等等,要做大的任务必须要有更大规模的实现,就不再是单机版能做的事。
但另一方面,我们要看到这实际上是在发展学科思路上一个全新的思路探索,所以今天虽然它已经能够解决一部分问题了,但是我们应该可以看到它再往下发展,前景可能是今天我们还不太能够完全预见到的,所以我这边简单回顾一下卷积神经网络,这么一个非常流行的技术,它其实也是经过了很长期的发展。
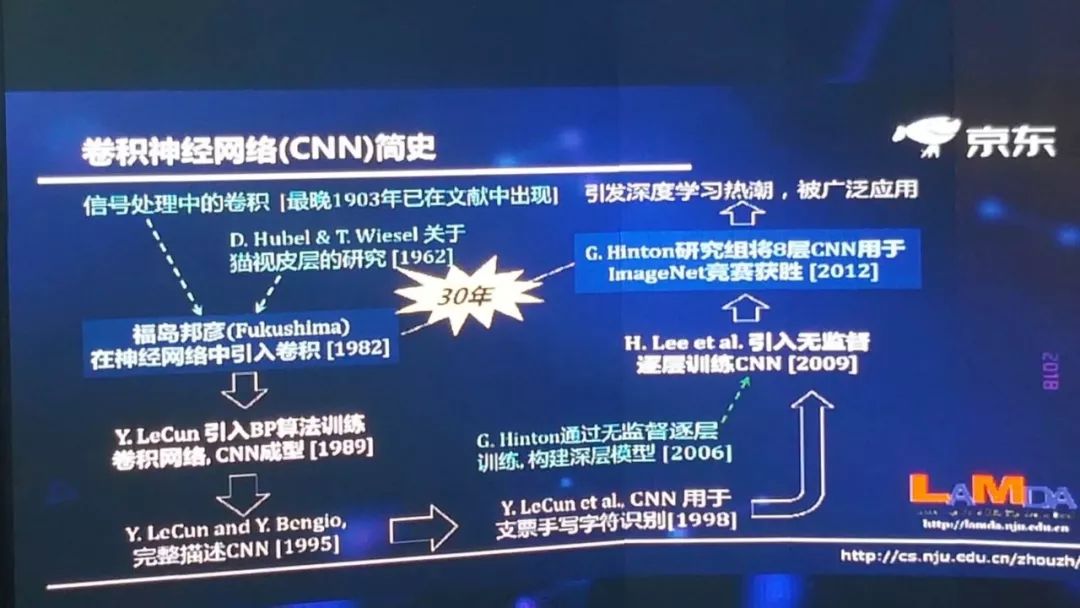
回顾这段历史,从卷积神经网络开始出现,到这个算法真正在工业界取得巨大成效,中间经过了 30 年的发展,我经常说我们其实没有什么真正的颠覆性技术,所有的技术都是一步步发展。今天我们有新的探索,新的探索能够解决一些问题,但我们应该往长远看,在经过很多年,很多人的进一步努力后,今天的探索应该是为未来技术打下一个更加重要的基础。
我们做的这一工作,我想它实际上是深度森林这一大类模型的开始,技术细节就不展开了,但是它全面的用到了集成学习里,据我所知多样性增强方面,所有的技术都用进去,所以如果大家感兴趣,这是我自己写的一本书。

我所做的工作的最重要的意义是什么呢?以前我们说深度学习是一个黑屋子,这个黑屋子里面有什么东西呢?大家都知道它有深度神经网络,现在我们把这个屋子打开了一扇门,把深度森林放进来,我想以后可能还有更多的东西。所以这是这个工作从学术科学发展上的意义上,有一个更重要的价值。
▌AI时代最重要的是人才
最后我想用两分钟的时间谈一谈,南京大学人工智能学院马上跟京东开展全面的、深入的在科学研究和人才培养方面的合作。
关于人工智能产业的发展,我们要问一个问题,我们到底需要什么?大家说需要设备吗?其实做人工智能的研究不需要特殊机密的设备,你只要花钱,这些设备都买得到,GPU 这些都不是什么高端的禁运的商品。第二是不是缺数据?也不是,现在我们的数据收集存储、传输、处理的能力大幅度的提升,到处都是数据,真正缺的是什么?
其实人工智能时代最缺的就是人才。因为对这个行业来说,你有多好的人,才有多好的人工智能。所以我们现在可以看到,其实全球都在争抢人工智能人才,不光是中国,美国也是这样。所以我们成立人工智能学院,其实就有这样的考虑。

信息化之后人类社会必然进入智能化,可以说这是一个不可逆转、不可改变的一个趋势。因为我们基于数据信息为人提供智能辅助,让人做事更容易,这是我们所有人的愿望。蒸汽机的革命是把我们从体力劳动里面解放出来,人工智能革命应该是把我们人类从一些反复性强的简单智力劳动中解放出来,而且人工智能这一个学科和其他短期的投资风口和短期热点不太一样,它经过 60 多年的发展,已经有了一个庞大的、真正的知识体系。

可能我们投资风口里面有一些词,今年还很热,明年就已经不见了,这些词如果我们追究一下,它里面科学含义到底是什么?可能没几个人说的清楚,而人工智能和这些东西完全不一样,是经过 60 多年发展出来的一个学科。
高水平的人工智能人才奇缺,这是一个世界性的问题,我们很多企业都是重金挖人,但实际上挖人不能带来增量,所以我们要从源头做起,为国家、社会、产业的发展培养高水平的人工智能人才。
未来智能实验室是人工智能学家与科学院相关机构联合成立的人工智能,互联网和脑科学交叉研究机构。
未来智能实验室的主要工作包括:建立AI智能系统智商评测体系,开展世界人工智能智商评测;开展互联网(城市)云脑研究计划,构建互联网(城市)云脑技术和企业图谱,为提升企业,行业与城市的智能水平服务。
如果您对实验室的研究感兴趣,欢迎加入未来智能实验室线上平台。扫描以下二维码或点击本文左下角“阅读原文”






