观点|元学习:实现通用人工智能的关键!
雷锋网按 :本文作者Flood Sung,本文原载于其知乎专栏——智能单元。雷锋网已获得原作者授权。
1 前言
Meta Learning(元学习)或者叫做 Learning to Learn(学会学习)已经成为继Reinforcement Learning(增强学习)之后又一个重要的研究分支(以后仅称为Meta Learning)。对于人工智能的理论研究,呈现出了
Artificial Intelligence --> Machine Learning --> Deep Learning --> Deep Reinforcement Learning --> Deep Meta Learning
这样的趋势。
之所以会这样发展完全取决于当前人工智能的发展。在Machine Learning时代,复杂一点的分类问题效果就不好了,Deep Learning深度学习的出现基本上解决了一对一映射的问题,比如说图像分类,一个输入对一个输出,因此出现了AlexNet这样的里程碑式的成果。但如果输出对下一个输入还有影响呢?也就是sequential decision making的问题,单一的深度学习就解决不了了,这个时候Reinforcement Learning增强学习就出来了,Deep Learning + Reinforcement Learning = Deep Reinforcement Learning深度增强学习。有了深度增强学习,序列决策初步取得成效,因此,出现了AlphaGo这样的里程碑式的成果。但是,新的问题又出来了,深度增强学习太依赖于巨量的训练,并且需要精确的Reward,对于现实世界的很多问题,比如机器人学习,没有好的reward,也没办法无限量训练,怎么办?这就需要能够快速学习。而人类之所以能够快速学习的关键是人类具备学会学习的能力,能够充分的利用以往的知识经验来指导新任务的学习,因此Meta Learning成为新的攻克的方向。
与此同时,星际2 DeepMind使用现有深度增强学习算法失效说明了目前的深度增强学习算法很难应对过于复杂的动作空间的情况,特别是需要真正意义的战略战术思考的问题。这引到了通用人工智能中极其核心的一个问题,就是要让人工智能自己学会思考,学会推理。AlphaGo在我看来在棋盘特征输入到神经网络的过程中完成了思考,但是围棋的动作空间毕竟非常有限,也就是几百个选择,这和星际2几乎无穷的选择对比就差太多了(按屏幕分辨率*鼠标加键盘的按键 = 1920*1080*10 约等于20,000,000种选择)。然而在如此巨量选择的情况下,人类依然没问题,关键是人类通过确定的战略战术大幅度降低了选择范围(比如当前目标就是造人,挖矿)因此如何使人工智能能够学会思考,构造战术非常关键。这个问题甚至比快速学习还要困难,但是Meta Learning因为具备学会学习的能力,或许也可以学会思考。因此,Meta Learning依然是学会思考这种高难度问题的潜在解决方法之一。
经过以上的分析,不过是为了得出下面的结论:
Meta Learning是实现通用人工智能的关键!
在本文之前,专栏已经发布了两篇和Meta Learning相关的文章:
学会学习Learning to Learn:让AI拥有核心价值观从而实现快速学习
机器人革命与学会学习Learning to Learn
之前采用Learning to Learn这个名称是希望让更多的知友明白这个概念,从本篇开始,我们会直接使用Meta Learning这个名称(其实只是因为这个名称看起来更专业更酷)
关于Meta Learning的概念本文就不介绍了,在上面列出的两篇Blog已有讲解。本文将和大家分享一下Meta Learning的一些最前沿的研究进展,可以说是百家争鸣的阶段。
2 Meta Learning百花齐放的研究思路
为什么说Meta Learning的研究是百家争鸣呢?因为每一家的研究思路都完全不同,真的是各种方法各种试,呈现出一种智慧大爆发的阶段。
关于Meta Learning的papers,我收集了一下:
songrotek/Meta-Learning-Papers
这里主要分析一下最近一两年来的发展情况,先作个分类,然后做一下简要的分析。
2.1 基于记忆Memory的方法
基本思路:既然要通过以往的经验来学习,那么是不是可以通过在神经网络上添加Memory来实现呢?
代表文章:
[1] Santoro, Adam, Bartunov, Sergey, Botvinick, Matthew, Wierstra, Daan, and Lillicrap, Timothy. Meta-learning with memory-augmented neural networks. In Proceedings of The 33rd International Conference on Machine Learning, pp. 1842–1850, 2016.
[2] Munkhdalai T, Yu H. Meta Networks. arXiv preprint arXiv:1703.00837, 2017.
以Meta-Learning with memory-augmented neural networks这篇文章为例,我们看一下他的网络结构:
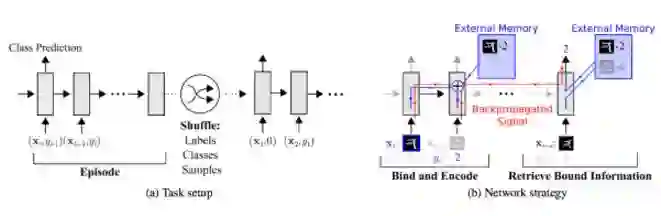
我们可以看到,网络的输入把上一次的y label也作为输入,并且添加了external memory存储上一次的x输入,这使得下一次输入后进行反向传播时,可以让y label和x建立联系,使得之后的x能够通过外部记忆获取相关图像进行比对来实现更好的预测。
2.2 基于预测梯度的方法
基本思路:既然Meta Learning的目的是实现快速学习,而快速学习的关键一点是神经网络的梯度下降要准,要快,那么是不是可以让神经网络利用以往的任务学习如何预测梯度,这样面对新的任务,只要梯度预测得准,那么学习得就会更快了?
代表文章:
[1] Andrychowicz, Marcin, Denil, Misha, Gomez, Sergio, Hoffman, Matthew W, Pfau, David, Schaul, Tom, and de Freitas, Nando. Learning to learn by gradient descent by gradient descent. In Advances in Neural Information Processing Systems, pp. 3981–3989, 2016
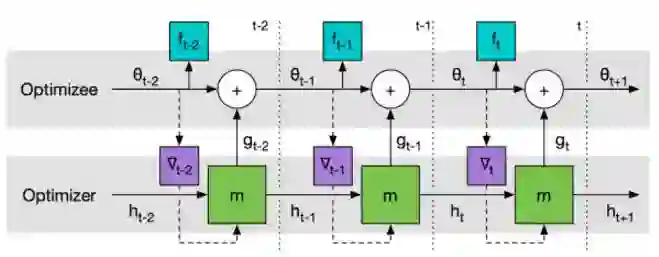
这篇文章的思路很清奇,训练一个通用的神经网络来预测梯度,用一次二次方程的回归问题来训练,然后这种方法得到的神经网络优化器比Adam,RMSProp还要好,这样显然就加快了训练。
2.3 利用Attention注意力机制的方法
基本思路:人的注意力是可以利用以往的经验来实现提升的,比如我们看一个性感图片,我们会很自然的把注意力集中在关键位置。那么,能不能利用以往的任务来训练一个Attention模型,从而面对新的任务,能够直接关注最重要的部分。
代表文章:
[1] Vinyals, Oriol, Blundell, Charles, Lillicrap, Tim, Wierstra, Daan, et al. Matching networks for one shot learning. In Advances in Neural Information Processing Systems, pp. 3630–3638, 2016.
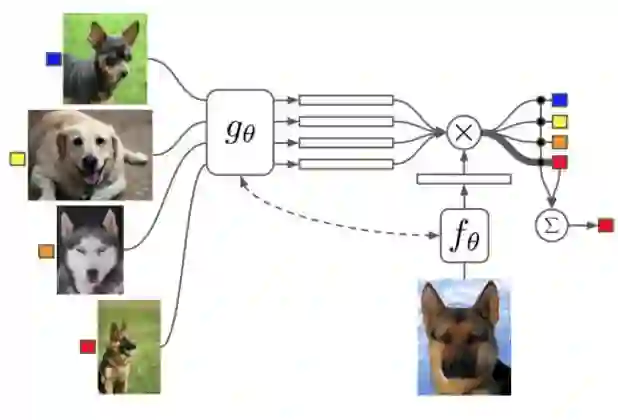
这篇文章构造一个attention机制,也就是最后的label判断是通过attention的叠加得到的:
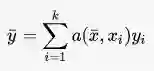
attention a则通过g和f得到。基本目的就是利用已有任务训练出一个好的attention model。
2.4 借鉴LSTM的方法
基本思路:LSTM内部的更新非常类似于梯度下降的更新,那么,能否利用LSTM的结构训练出一个神经网络的更新机制,输入当前网络参数,直接输出新的更新参数?这个想法非常巧妙。
代表文章:
[1] Ravi, Sachin and Larochelle, Hugo. Optimization as a model for few-shot learning. In International Conference on Learning Representations (ICLR), 2017.
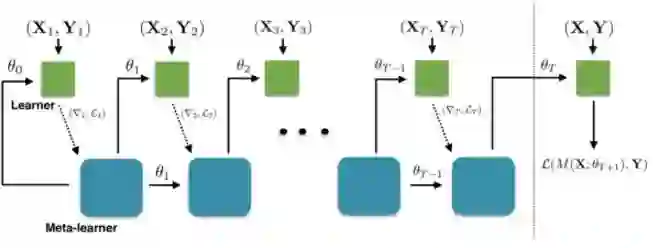
这篇文章的核心思想是下面这一段:

怎么把LSTM的更新和梯度下降联系起来才是更值得思考的问题吧。
2.5 面向RL的Meta Learning方法
基本思路:既然Meta Learning可以用在监督学习,那么增强学习上又可以怎么做呢?能否通过增加一些外部信息的输入比如reward,之前的action来实现?
代表文章:
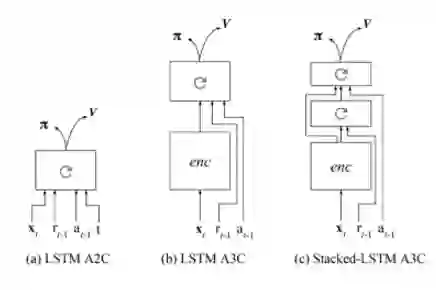
[1] Wang J X, Kurth-Nelson Z, Tirumala D, et al. Learning to reinforcement learn. arXiv preprint arXiv:1611.05763, 2016.
[2] Y. Duan, J. Schulman, X. Chen, P. Bartlett, I. Sutskever, and P. Abbeel. Rl2: Fast reinforcement learning via slow reinforcement learning. Technical report, UC Berkeley and OpenAI, 2016.
两篇文章思路一致,就是额外增加reward和之前action的输入,从而强制让神经网络学习一些任务级别的信息:
2.6 通过训练一个好的base model的方法,并且同时应用到监督学习和增强学习
基本思路:之前的方法都只能局限在或者监督学习或者增强学习上,能不能搞个更通用的呢?是不是相比finetune学习一个更好的base model就能work?
代表文章:
[1] Finn, C., Abbeel, P., & Levine, S. (2017). Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks. arXiv preprint arXiv:1703.03400.

这篇文章的基本思路是同时启动多个任务,然后获取不同任务学习的合成梯度方向来更新,从而学习一个共同的最佳base。
2.7 利用WaveNet的方法
基本思路:WaveNet的网络每次都利用了之前的数据,那么是否可以照搬WaveNet的方式来实现Meta Learning呢?就是充分利用以往的数据呀?
代表文章:
[1] Mishra N, Rohaninejad M, Chen X, et al. Meta-Learning with Temporal Convolutions. arXiv preprint arXiv:1707.03141, 2017.
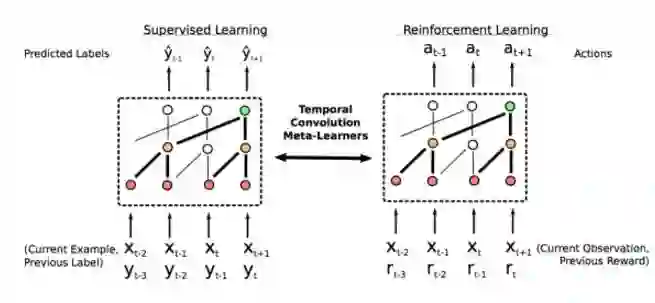
直接利用之前的历史数据,思路极其简单,效果极其之好,是目前omniglot,mini imagenet图像识别的state-of-the-art。
2.8 预测Loss的方法
基本思路:要让学习的速度更快,除了更好的梯度,如果有更好的loss,那么学习的速度也会更快,因此,是不是可以构造一个模型利用以往的任务来学习如何预测Loss呢?
代表文章:
[1] Flood Sung, Zhang L, Xiang T, Hospedales T, et al. Learning to Learn: Meta-Critic Networks for Sample Efficient Learning. arXiv preprint arXiv:1706.09529, 2017.
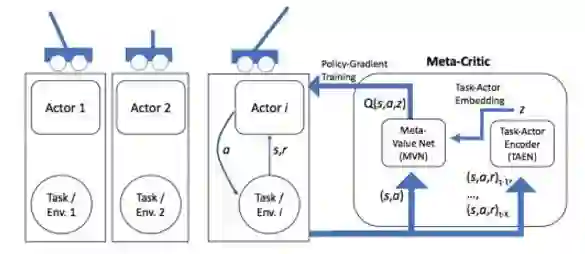
本文构造了一个Meta-Critic Network(包含Meta Value Network和Task-Actor Encoder)来学习预测Actor Network的Loss。对于Reinforcement Learning而言,这个Loss就是Q Value。
本文详细分析详见:学会学习Learning to Learn:让AI拥有核心价值观从而实现快速学习
本文 纽约大学的Kyunghyun Cho 做了评价:

也算是一种全新的思路。
3 小结
从上面的分析可以看出,Meta Learning方兴未艾,各种神奇的idea层出不穷,但是真正的杀手级算法还未出现,非常期待未来的发展!也希望更多的朋友们可以投入到Meta Learning这个研究方向上来。
————— 给爱学习的你的福利 —————
CCF-ADL81:从脑机接口到脑机融合
顶级学术阵容,50+学术大牛
入门类脑计算知识,了解类脑智能前沿资讯
课程链接:http://www.mooc.ai/course/114
或点击文末阅读原文

—————————————————




