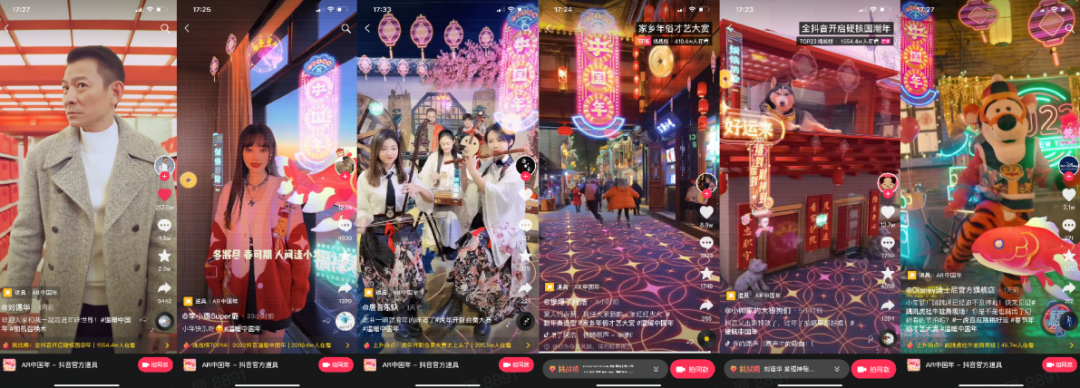
临近虎年春节,抖音上线了一系列 AR 相机特效。在抖音的镜头下,日常生活的景观呈现出各种奇妙的效果。其中,「AR 中国年」凭借将镜头扫描的画面场景转换成酷炫的赛博朋克新年风格最受欢迎,在广大网友的创意之下玩出了各色花样。
![]()
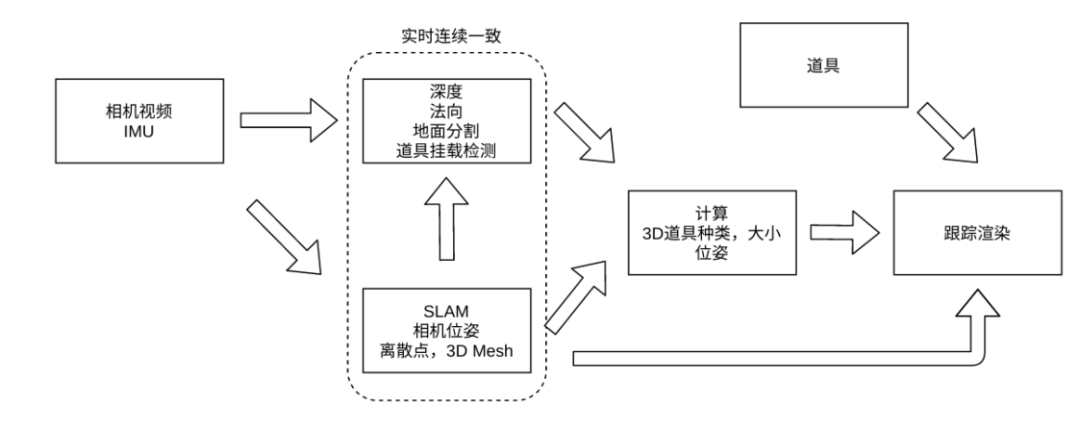
「AR 中国年」的效果源自于抖音产品团队对于未来赛博朋克中国城场景的设想。但要实现这样的效果,需要整合 AI 算法、图形渲染、特效设计等大量研发资源。为此,抖音技术团队专门研发了一套融合了深度学习、SLAM 与图形渲染技术的 AR 特效链路,整体的链路如下图所示。
![]()
系统首先通过对捕获的视频数据基于深度学习模型进行分析,获取实时的深度图、法向图与场景分割 Mask 等语义与几何信息,同时通过 SLAM 技术获取相机位姿等空间信息,并结合语义、几何与空间信息,对不同种类的道具进行放置与跟踪。通过 SLAM,还可以进行算法结果的多帧匹配,从而帮助提升语义几何分析的准确性和连续性,保证后续道具挂载的稳定性。在接下来的章节中,文章将会对部分关键算法环节展开剖析。
「AR 中国年」的一大亮点是能够在场景中较为自然地贴合道具素材。在 AR 场景中为了使素材的出现位置更加贴合场景,需要设计一套端上的自动道具挂载算法。为了使得挂载结果更加自然,算法还需要输出若干个符合透视的不规则四边形。
在算法设计之初,技术团队考虑了一套基于三维表面检测(3D Surface Detection)、二维形状检测(2D Shape Detection)与单帧 VP 检测(Vanishing Point Detection)结合的方案,并研发了一套基于线段和角点检测结合的 VP 检测系统。但由于该方案涉及的算法模块和策略较为复杂,移植到移动端并达到实时的性能具有较大的技术难度,技术团队便开始尝试使用较为轻量的 “目标检测 + 回归” 的方案,试图 “蒸馏” 学习出实时的道具挂载检测模型。
在「AR 中国年」特效中,为了营造出新年的气氛,需要同时挂载十几个不同的素材,而且素材出现的位置也并不是往往出现在平面上,例如 “灯笼” 就需要被挂载到屋檐或者天花板上。这就需要算法同时兼顾召回、透视以及场景分类。为此,技术团队设计了先通过检测模块进行召回,再通过回归模块进行筛选的二阶段算法。在检测阶段,检测模块去尽可能多的召回挂载区域,这些区域往往集中在建筑物、墙壁和物体上。在召回足够多的候选区域后,回归模块负责解决透视以及分类问题。为了降低坐标回归难度,需要加入一定的规则先验,将挂载框视作左上、左下、右上、右下四个点构成的凸四边形进行回归,最终模型的结果将经过排序、筛选、去重来保留高质量的挂载框。为了满足不同素材的特定要求,算法还会将挂载框进行分类来针对性的进行后处理,例如将比较长的区域进行切分来营造出比较工整的灯笼串效果。
值得一提的是,虽然由于性能原因,技术团队在算法方案上最终选择了 “目标检测 + 回归” 的方案,但基于 VP 检测的方案具备更真实的挂载效果,因此也被应用在了剪映玩法上,服务于基于服务端的编辑特效「国潮赛博 2022」。
![]()
![]()
在完成道具挂载检测后,在真实环境中插入虚拟物体还需要准确理解世界的三维法向信息。在相机坐标系下直接使用 SLAM 输出三维朝向会存在空缺以及由三维点朝向方向不准确的问题, 所以还需要一个面向移动端的轻量级法向估计解决方案。
为此,技术团队通过用带有激光雷达的 iPhone 离线采集了大量的环境数据(包含室内外不同光照条件下的数据,以及渲染生成等方式获取的场景法向数据),训练了鲁棒的端上法向估计模型。此外,团队还进一步利用了手机 IMU 的重力方向对法向的角度进行矫正,从而保证挂载物始终能够和重力方向吻合,更符合一般的建筑规律, 来规避深度学习网络在法向预测不够完全准确的情况。从下图的结果可以看到,在不同变换角度与光照环境条件下, 虚拟的贴图仍然可以很好的贴合图像法向,从而能支持各种虚拟挂载的真实特性。
![]()
![]()
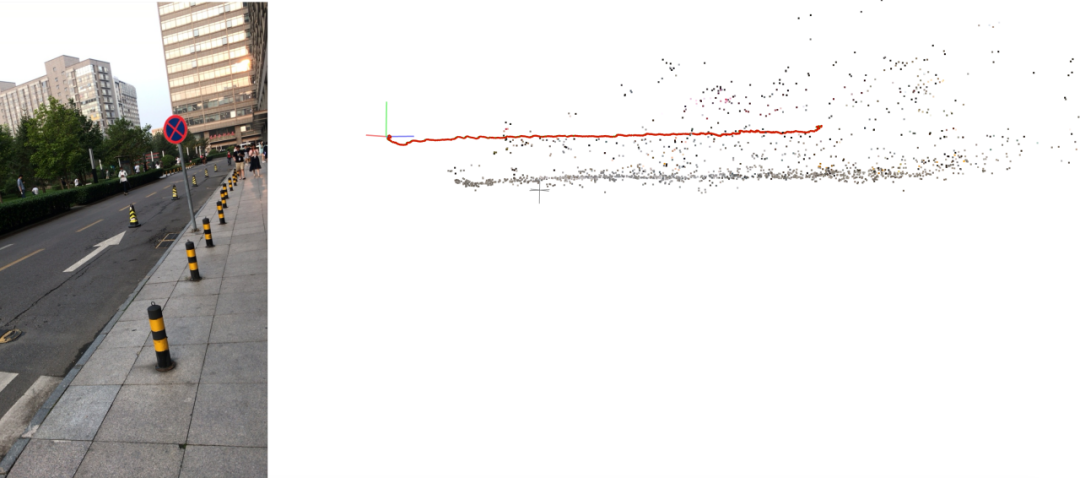
为了将道具能够持续跟踪在建筑上,技术团队构建了一套大场景下的视觉 SLAM 系统,在大部分抖音用户手机上均能进行实时鲁棒地跟踪。该 SLAM 系统具备如下几个特性:
• 用户无感的快速初始化 。传统的视觉 SLAM 算法依赖严格的初始化,需要用户进行充分的运动之后才能使用 AR 特效,这大大提升了使用 AR 特效的门槛。为了让广大抖音用户都能更容易地玩起 AR 特效,该方案基于轻量化的多层级初始化设计研发,融合了场景结构先验、多假设的滤波估计和小运动下的全局优化,实现了首帧即时的 AR 体验。
• 覆盖不同的移动端机型。由于抖音用户覆盖面非常大,尤其是安卓用户机型众多,对算法的鲁棒性提出了更高层面的要求。视觉 SLAM 系统以视觉为主,同时辅助利用了系统的传感器信息来对位姿进行约束。由于不同手机的传感器质量参差不齐,系统还结合离线标定和在线估计的策略,在离线标定通用参数的基础上又实时进行参数优化,低成本地覆盖更多的用户机型。
• 大场景实时跟踪。在大场景下,纯视觉的 SLAM 系统容易受到远点和动态物体的干扰,尤其在长时间直行的情况下相机的估计高度容易产生漂移。基于多帧几何分析与语义先验,系统对视觉特征进行了分类处理,同时将实时全局信息压缩后持续在系统中进行优化,减少了长时间运动下的漂移。
• 网格与平面估计。基于 SLAM 系统输出的稀疏点云,系统结合 2D 图像信息和 3D 平面估计信息,对点云进行单帧的实时网格化息。为了解决弱纹理和远景区域几何信息缺失的问题,系统还结合了上述的法向估计模型,保证了全区域的挂载可用性。
![]()
以 SLAM 初始化为例,在用户实际使用道具拍摄时,会经常发生由于相机仅有纯旋转或静止不动无法初始化 SLAM 系统或 SLAM 初始化成功但重建的网格质量仍无法满足特效需求的情况。为了解决这个问题,系统引入了深度估计模型,对静止的图像进行相对深度估计并重建出三角网络。待 SLAM 初始化成功后,再对三角网格进行过渡融合。通过这种方式,在 SLAM 无法初始化的情况下也可以输出三角网格,并结合道具挂载检测与法向估计进行素材挂载,在后续使用过程中也能过渡到真实深度场景。
由于「AR 中国年」整个流程涉及到多个算法模块,导致整体的算法包体积偏大,进而会影响特效下发到移动端的成功率。为此,技术团队还针对包体积进行了极致的性能优化。在深度模型训练流程中,遵循如下原则:首先通过 AutoML 算法,找到紧凑的模型结构;然后,再采用剪枝和非结构量化相结合的压缩算法,在训练中将网络中的不重要权值剪枝为零值,使其达到一定的稀疏比例,再将剩下非零的权值进行非结构量化;最后结合低比特结构化量化算法,在保证算法精度的前提下,极致压缩算法模型体积。基于上述方案,所有算法模块依赖的深度模型体积大小得到了有效控制,保证了最终特效下发的成功率。
在抖音中,大量创新性的热门特效均出自于字节跳动 - 智能创作团队。智能创作团队是字节跳动音视频创新技术和业务中台,覆盖了计算机视觉、图形学、语音、拍摄编辑、特效、客户端、服务端工程等技术领域,在部门内部实现了前沿算法 - 工程系统 - 产品全链路的闭环,旨在以多种形式向公司内部各业务线以及外部合作客户提供业界最前沿的内容理解、内容创作、互动体验与消费的能力和行业解决方案。
目前,智能创作团队已通过字节跳动旗下的火山引擎向企业开放技术能力和服务。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com