
麻省理工学院(MIT)的研究人员发现,如果某一类型的机器学习模型使用一个不平衡的数据集进行训练,那么它学习到的偏差在事后是不可能修复的。他们开发了一种技术,无论训练数据集多么不平衡,都可以直接将公平性引入模型,从而提高模型在下游任务上的性能。

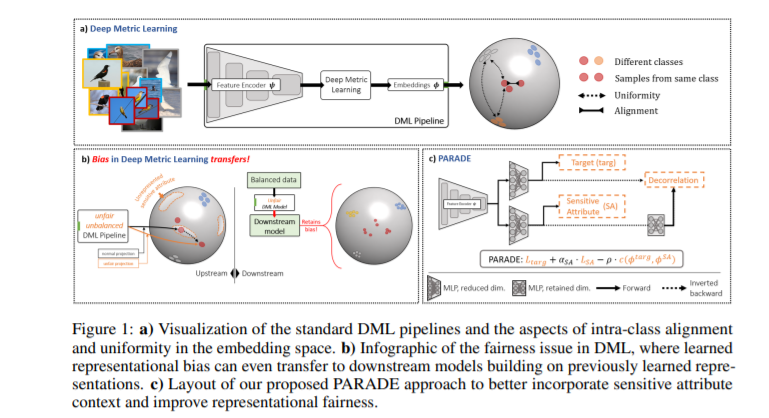
深度度量学习(DML)通过强调表示的相似结构,可以在较少的监督下进行学习。在诸如零样本检索等设置中,已经有很多工作在提高DML的泛化,但对其公平性的影响知之甚少。在这篇论文中,我们首次评估了在不平衡数据上训练的最先进的DML方法,并表明当用于下游任务时,这些表征对少数子群体的表现有负面影响。在本文中,我们首先通过分析表示空间的三个性质——类间对齐、类内对齐和均匀性,定义了DML中的公平性,并提出了非平衡DML基准中的公平性——finDML来描述表示公平性。利用finDML,我们发现DML表示中的偏差传播到常见的下游分类任务。令人惊讶的是,即使下游任务中的训练数据被重新平衡,这种偏差也会传播。为了解决这个问题,我们提出了部分属性去相关(Partial Attribute De-correlation, PARADE)来将敏感属性的特征表示去相关,并在嵌入空间和下游度量中减少子组之间的性能差距。
成为VIP会员查看完整内容
相关内容

专知会员服务
38+阅读 · 2020年5月30日
Arxiv
0+阅读 · 2022年4月20日
Arxiv
0+阅读 · 2022年4月20日
Arxiv
15+阅读 · 2020年3月31日
A Survey of Reinforcement Learning Techniques: Strategies, Recent Development, and Future Directions
Arxiv
80+阅读 · 2020年1月19日
相关主题


相关VIP内容
专知会员服务
38+阅读 · 2020年5月30日
相关资讯
相关论文
Arxiv
0+阅读 · 2022年4月20日
Arxiv
0+阅读 · 2022年4月20日
Arxiv
15+阅读 · 2020年3月31日
A Survey of Reinforcement Learning Techniques: Strategies, Recent Development, and Future Directions
Arxiv
80+阅读 · 2020年1月19日