【推荐系统】推荐系统研究中常用的评价指标
点击上方,选择星标或置顶,每天给你送干货
阅读大概需要13分钟
跟随小博主,每天进步一丢丢


“ 本文主要介绍了推荐系统中常用的评价指标,包括评分预测指标,集合推荐指标,排名推荐指标以及多样性和稳定性等。”
本文来源:苏一 https://zhuanlan.zhihu.com/p/67287992
整理了一下过去大半年中所看推荐系统相关文献中出现过的评价指标,如果大家发现有本文遗漏的评价指标欢迎在评论区中指出,我再补充进来。
目录
一、概述
二、常用的评估指标
三、其他的评估指标
一、概述
自推荐系统研究开始以来,对预测和推荐结果的评估一直都是十分重要的环节,一个推荐算法的优劣直接体现在其在这些评估指标上的表现。一般来说,按照推荐任务的不同,最常用的推荐质量度量方法可以划分为三类:(1)对预测的评分进行评估,适用于评分预测任务。(2)对预测的item集合进行评估,适用于Top- N推荐任务。(3)按排名列表对推荐效果加权进行评估,既可以适用于评分预测任务也可以用于Top-N推荐任务。。
这三类度量方法对应的具体评价指标分别为:
(a)评分预测指标:如准确度指标:平均绝对误差(MAE)、均方误差根(RMSE)、标准化平均误差(NMAE);以及覆盖率(Coverage)
(b)集合推荐指标:如精密度(Precision)、召回(Recall)、 ROC和AUC
(c)排名推荐指标:如half-life和discounted cumulative gain等
本文余下的部分将针对这些指标进行详细介绍
二、常用的评估指标
「1、quality of the predictions」
为了衡量RS结果的准确性,通常使用一些最常见的预测误差指标的计算,其中平均绝对误差(Mean Absolute Error,MAE)及其相关指标:均方误差(Mean Squared Error,MSE)、均方根误差(Root Mean Squared Error,RMSE)和标准平均绝对误差(Normalized Mean Absolute Error,NMAE)是其中最具有代表性的指标。
符号定义
U代表测试集中user集合,I代表测试集中item集合, 代表u对i的评分,●代表空缺的评分( =●代表u没有对i评过分), 代表预测的u对i的评分,
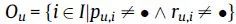
代表测试集中既有用户u评分记录,又有模型产生的预测评分的item集合,
「1.1平均绝对误差(Mean Absolute Error,MAE)」
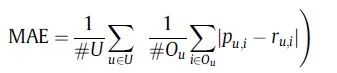
单个用户u的 「标准平均绝对误差(NMAE)」 为
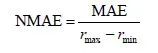
,其中 和 分别为用户u评分区间的最大值和最小值。
「1.2均方根误差(Root Mean Squared Error,RMSE)」
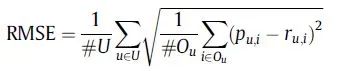
将上式的根号去掉即是 「均方误差(Mean Squared Error,MSE)」
「1.3覆盖率(Coverage)」
覆盖率最简单的定义是,推荐系统能够推荐出来的物品占总物品的比例。覆盖率越高表明模型能够针对更多的item产生推荐,从而促进长尾效应的挖掘。我们将 定义为u的近邻集合,那么我们可以将覆盖率定义如下:
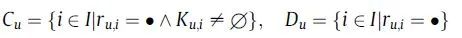
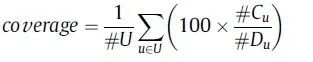
除此之外,信息熵和基尼系数也可以用来度量覆盖率。
「2、quality of the set of recommendations」
由于数据稀疏和冷启动问题的存在,有时直接预测用户对item的评分是困难的,为此有学者提出了Top- N推荐方法,即不预测用户对item的评分,而是根据user-item的隐式交互(例如点击、收藏)来生成一组用户最有可能喜欢的items集合推荐给用户。
在本小节,我们将对Top-N推荐中最广泛使用的推荐质量度量指标展开介绍。它们分别是:(1)Precision,表示推荐项目总数中相关推荐项目的比例;
(2)召回,表示相关推荐项目数量中相关推荐项目的比例;
(3)f1,表示精确性和召回的结合。
(4)ROC与AUC
符号定义
R(u)代表根据用户在训练集上的行为给用户做出的推荐列表,T(u)代表用户在测试集上的行为列表。
「2.1Precision」
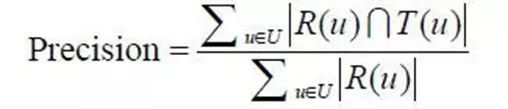
「2.2Recall」
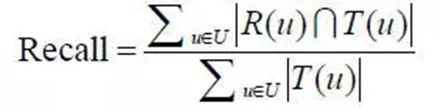
「2.3F1」
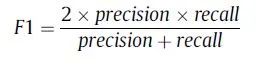
「2.4 Receiver Operating Characteristic(ROC)与AUC(Area under curve)」
AUC指标表示ROC(receiver operator curve)曲线下的面积,它衡量一个推荐系统能够在多大程度上将用户喜欢的商品与不喜欢的商品区分出来。
由于ROC曲线绘制步骤比较繁琐,可以用以下方法来近似计算系统的AUC:每次随机从相关商品集,即用户喜欢的商品集中选取一个商品α ,与随机选择的不相关商品 β 进行比较,如果商品α 的预测评分值大于商品β 的评分,那么就加一分,如果两个评分值相等就加0.5分。这样独立地比较n 次,如果有n′ 次商品α 的预测评分值大于商品β 的评分,有n′′次两评分值相等,那么AUC就可以近似写作:
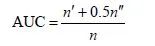
显然,如果所有预测评分都是随机产生的,那么AUC=0.5。因此AUC大于0.5的程度衡量了算法在多大程度上比随机推荐的方法精确。AUC指标仅用一个数值就表征了推荐算法的整体表现,而且它涵盖了所有不同推荐列表长度的表现。但是AUC指标没有考虑具体排序位置的影响,导致在ROC曲线面积相同的情况下很难比较算法好坏,所以它的适用范围也受到了一些限制。
「2.5 Hit Rate (HR)」

HR是目前TOP-N推荐研究中十分流行的评价指标,其公式如上所示,其中#users是用户总数,而#hits是测试集中的item出现在Top- N推荐列表中的用户数量。
「2.6 Average Reciprocal Hit Rank (ARHR)」
ARHR也是目前Top-N推荐中十分流行的指标,它是一种加权版本的HR,它衡量一个item被推荐的强度,公式如下:
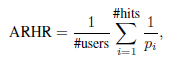
其中权重 是推荐列表中位置的倒数。
「3、quality of the list of recommendations」
当推荐项目的数量很大时,用户会更加重视推荐列表中排在前面的item。这些item中发生的错误比列表中排在后面的item中的错误更严重。按排名列表对推荐效果进行加权评估的方法考虑了这种情况。在最常用的排名度量指标中,有以下标准信息检索度量:
(a)半衰期(half-life),假设当用户远离顶部的推荐时,他们的兴趣指数下降;
(b)贴现累积增益(discounted cumulative gain),其中衰减函数是对数函数。
(c)排序偏差准确率(rank-biased precision,RBP),以等比数列衰减
「3.1HL」
半衰期效用指标(half-life utility)是在用户浏览商品的概率与该商品在推荐列表中的具体排序值呈指数递减的假设下提出的,它度量的是推荐系统对一个用户的实用性也即是用户真实评分和系统默认评分值的差别。用户 u 的期望效用定义为:
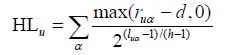
式中, 表示用户u对商品α 的实际评分;而 为商品α 在用户u的推荐列表中的排名;d 为默认评分(如说平均评分值);h 为系统的半衰期,也即是有50%的概率用户会浏览的推荐列表的位置。显然,当用户喜欢的商品都被放在推荐列表的前面时,该用户的半衰期效用指标达到最大值。
「3.2discounted cumulative gain」
折扣累计收益(discounted cumulative gain, DCG)的主要思想是用户喜欢的商品被排在推荐列表前面比排在后面会更大程度上增加用户体验,定义为:
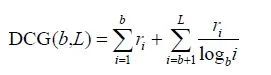
式中, 表示排在第i 位的商品是否是用户喜欢的;ri = 1表示用户喜欢该商品;ri =0 表示用户不喜欢该商品;b是自由参数一般设为2;L为推荐列表长度。
由于在用户与用户之间,DCGs没有直接的可比性,所以我们要对它们进行归一化处理。最糟糕的情况是,当使用非负相关评分时DCG为0。为了得到最好的,我们把测试集中所有的条目置放在理想的次序下,采取的是前K项并计算它们的DCG。然后将原DCG除以理想状态下的DCG就可以得到「归一化折扣累计收益(Normalized Discounted Cumulative Gain,NDCG)」 ,它是一个0到1之间的数。
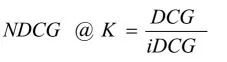
「3.3排序偏差准确率(rank-biased precision,RBP)」
与 DCG 指标不同,排序偏差准确率(rank-biased precision,RBP)假设用户往往先浏览排在推荐列表首位的商品然后依次以固定的概率p浏览下一个,以1−p的概率不再看此推荐列表。RBP定义为:
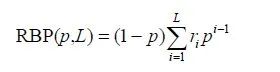
RBP和DCG指标的唯一不同点在于RBP把推荐列表中商品的浏览概率按等比数列递减,而DCG则是按照log调和级数形式。
「3.4 Mean Reciprocal Rank (MRR)」
MRR是把正确的item在推荐列表中的排序取倒数作为它的准确度,再对所有的问题取平均。相对简单,举个例子:有3个query如下图所示:

(黑体为返回结果中最匹配的一项),那么MRR值为:(1/3 + 1/2 + 1)/3 = 11/18=0.61
「3.5 Mean Average Precision (MAP)」
平均准确率MAP,假使当我们使用google搜索某个关键词,返回了10个结果。当然最好的情况是这10个结果都是我们想要的相关信息。但是假如只有部分是相关的,比如5个,那么这5个结果如果被显示的比较靠前也是一个相对不错的结果。但是如果这个5个相关信息从第6个返回结果才开始出现,那么这种情况便是比较差的。这便是AP所反映的指标,与recall的概念有些类似,不过AP是“顺序敏感的recall。
对于用户u ,给他推荐一些物品,那么u 的平均准确率为:
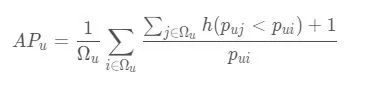
其中,Ωu表示ground-truth的结果, 表示i物品在推荐列表中的位置, $\displaystyle p_{uj}<p_{ui}$ 表示物品j排在i前面。<="" p="">
MAP表示所有用户u的AP取均值
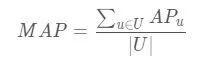
三、其他的评估指标
大多数文章讨论了试图提高评分预测任务的推荐结果(RMSE、MAE等)准确性的方法,在Top- N推荐的精确性、召回、ROC等方面尝试改进也是很常见的。但是,为了获得更高的用户满意度,还应考虑其他目标,例如主题多样性、新颖性和推荐的公平性等等。
目前,该领域对生成具有多样性和创新性建议的算法越来越感兴趣,即使以牺牲准确性和精度为代价。为了评估这些方面,学界提出了各种衡量建议新颖性和多样性的指标。
-
「多样性和新颖性」
假设
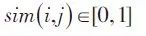
为物品i,j之间的相似性,那么用户u的推荐列表R(u)的多样性可以定义为:
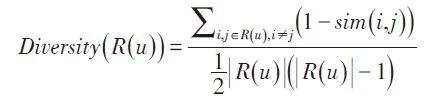
除了多样性以外,新颖性也是影响用户体验的重要指标之一。它指的是向用户推荐非热门非流行商品的能力。推荐流行的商品纵然可可能在一定程度上提高了推荐准确率但是却使得用户体验的满意度降低了。度量推荐新颖性最简单的方法是利用推荐商品的相似度。推荐列表中商品与用户已知商品的相似度越小,对于用户来说,其新颖性就越高。由此得到推荐新颖性指标:
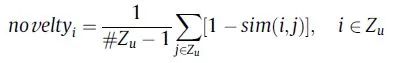
式中Zu表示推荐给用户u的n个item集合
「2.稳定性」
预测和推荐的稳定性会影响用户对RS的信任,如果一个推荐系统提供的预测在短时间内没有发生强烈变化,则它是稳定的。Adomavicius和Zhang提出了稳定性的质量度量指标:Mean Absolute Shift(平均绝对位移,MAS)。
假设我们现有一系列已知的用户评分数据集合R1,我们根据R1对一组用户未评分的item集合进行预测,得到一组预测评分数据集合P1。经过一段时间的交互后,用户对一些未评分的item有了评分,此时我们再对P1中的item评分进行预测,得到新的预测评分数据集合P2,则MAS可表示为: