推荐系统产品与算法概述 | 深度

作者丨gongyouliu
转载自大数据与人工智能(ID:gh_b8b5b02c348b)
作者在《推荐系统的工程实现》(点击蓝字可回顾)这篇文章的第五部分“推荐系统范式”中讲到工业级推荐系统有非个性化范式、完全个性化范式、群组个性化范式、标的物关联标的物范式、笛卡尔积范式等 5种 常用的推荐范式。本文会按照这5大范式来讲解常用的推荐算法,但不会深入讲解算法的实现原理,只是概述算法的实现思路,后面的系列文章我会对常用的重点算法进行细致深入剖析。
本文会从推荐算法与产品介绍、推荐召回算法概述、排序算法概述、推荐算法落地需要关注的几个问题等4部分来讲解。完全个性化范式和标的物关联标的物范式是最常用的推荐范式,在互联网产品中有大量真实场景应用,也是本文重点讲解的。
读者读完本文后,你会知道每类范式常用的算法有哪些、实现的思路是什么、以及常用的应用场景。本文也可以作为读者落地推荐算法到真实推荐场景的参考指南。
一、推荐算法与产品介绍
工业级推荐系统的推荐业务流程一般分为召回和排序两个阶段,召回就是将用户可能会感兴趣的标的物通过算法从全量标的物库中取出来,一般会采用多个算法来召回,比如热门召回、协同过滤召回、标签召回等,排序阶段将召回阶段的标的物列表根据用户可能的点击概率大小排序(即所谓的ctr预估)。在实际业务中,在排序后还会增加一层调控逻辑,根据业务规则及运营策略对排序后的列表进一步增补微调,满足特定的运营需求。
下面图1是电视猫(一款基于OTT端[智能电视或者智能盒子]的视频播放软件)的推荐系统的业务流程,包含召回、排序和业务调控三大算法和策略模块,可以作为大家设计推荐系统算法模块的参考。本文只讲解召回、排序两个阶段涉及到的算法,业务调控跟具体业务及公司运营策略强相关,本文不做过多描述。
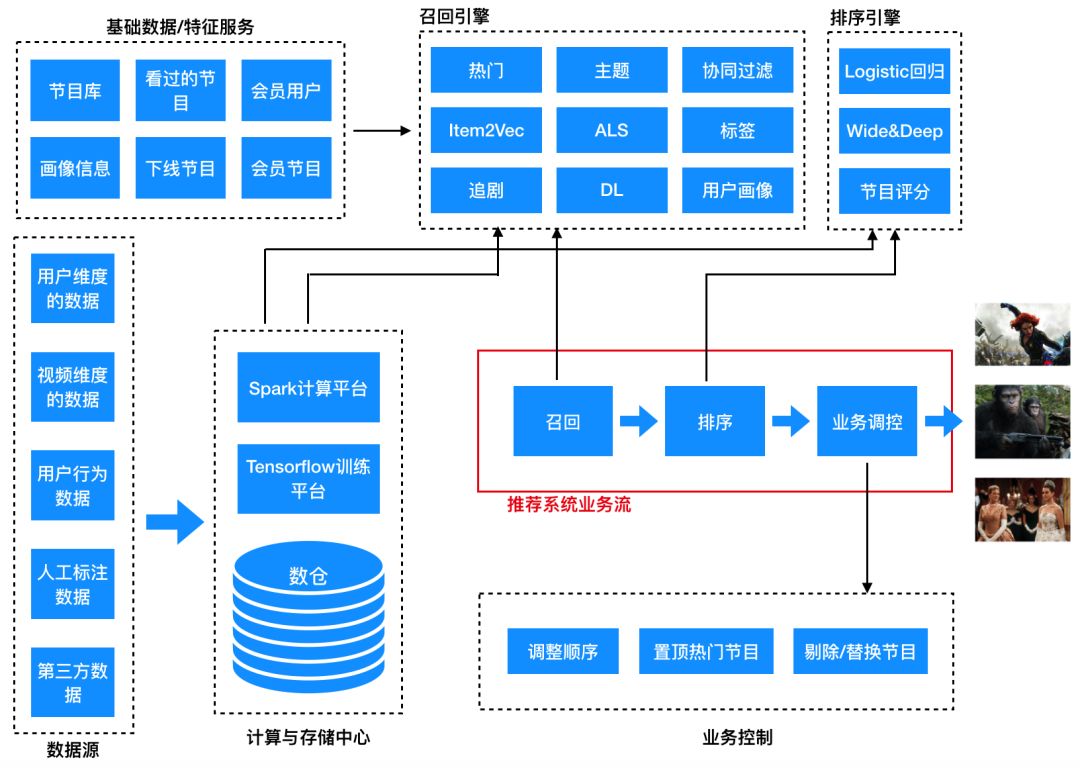
推荐算法是一种机器学习算法,所以算法模型的质量强依赖于用于算法训练的数据集,这里我们简单提下推荐系统可以利用的数据有哪些(参考下面图2及上面图1的数据源)。一般推荐系统依赖三大类数据:标的物metadata数据(标的物相关的描述信息)、用户画像数据(用户相关数据,如年龄、地域、性别、收入等)、用户行为数据(用户对标的物的操作行为,如播放、点击、购买、收藏等)。这三类数据是主要可用的模型数据。另外人工标注数据、第三方数据等也可以用来补充完善上述三类数据。
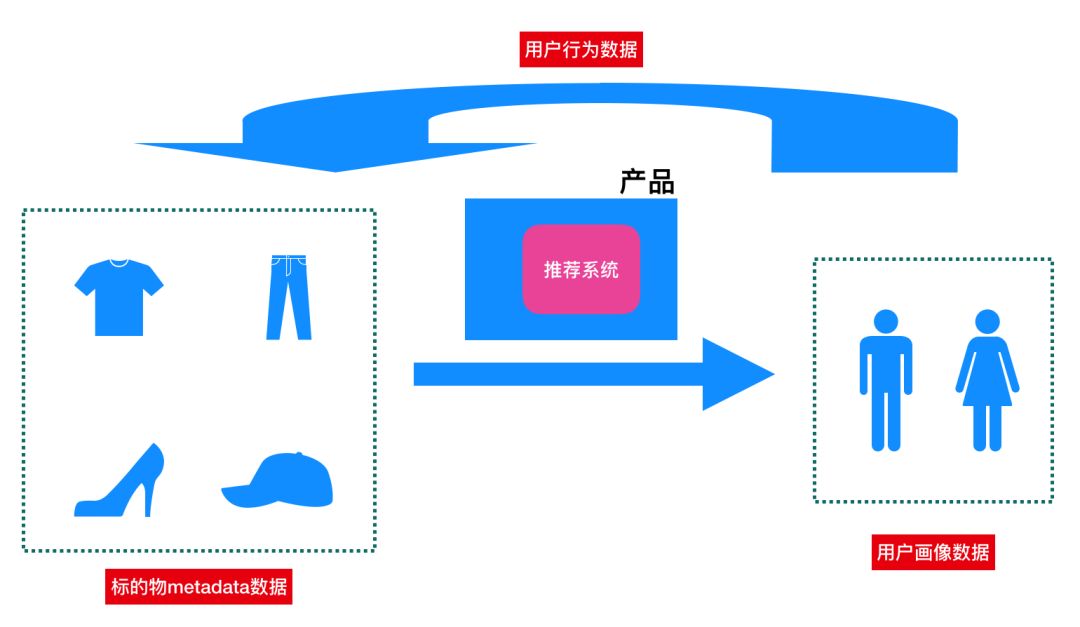
相信大家对推荐流程及算法依赖的数据有了初步了解,下面我们来根据不同的推荐范式重点讲解对应的推荐产品及可行的推荐算法,方便大家将不同的推荐算法对应到不同的推荐产品中。
上面我们提到的5类推荐范式,可以从三个维度来理解:
一个是用户维度,
一个是标的物维度,
一个是用户与标的物笛卡尔积维度。
从用户维度来看就是为用户推荐可能感兴趣的标的物,从标的物维度来看,就是用户在访问标的物详情页(或者退出标的物详情页)时,关联一组标的物作为推荐。第三个维度是将用户维度和标的物维度结合起来,不同的用户访问同样的标的物详情页看到的内容也不一样。
1. 基于用户维度的推荐
基于用户维度的推荐可以根据个性化的粒度分为非个性化、群组个性化、完全个性化。这三种粒度对应我们前面提到的非个性化范式、群组个性化范式、完全个性化范式。
非个性化是每个用户看到的推荐内容都完全一样,传统门户网站的编辑对内容的编排就是非个性化的方式,每个用户看到的内容都是一样的。对于各类网站或者APP的排行榜的推荐形态也是非个性化的。下面图3是网易云音乐的排行榜推荐,根据各个维度计算各类榜单。
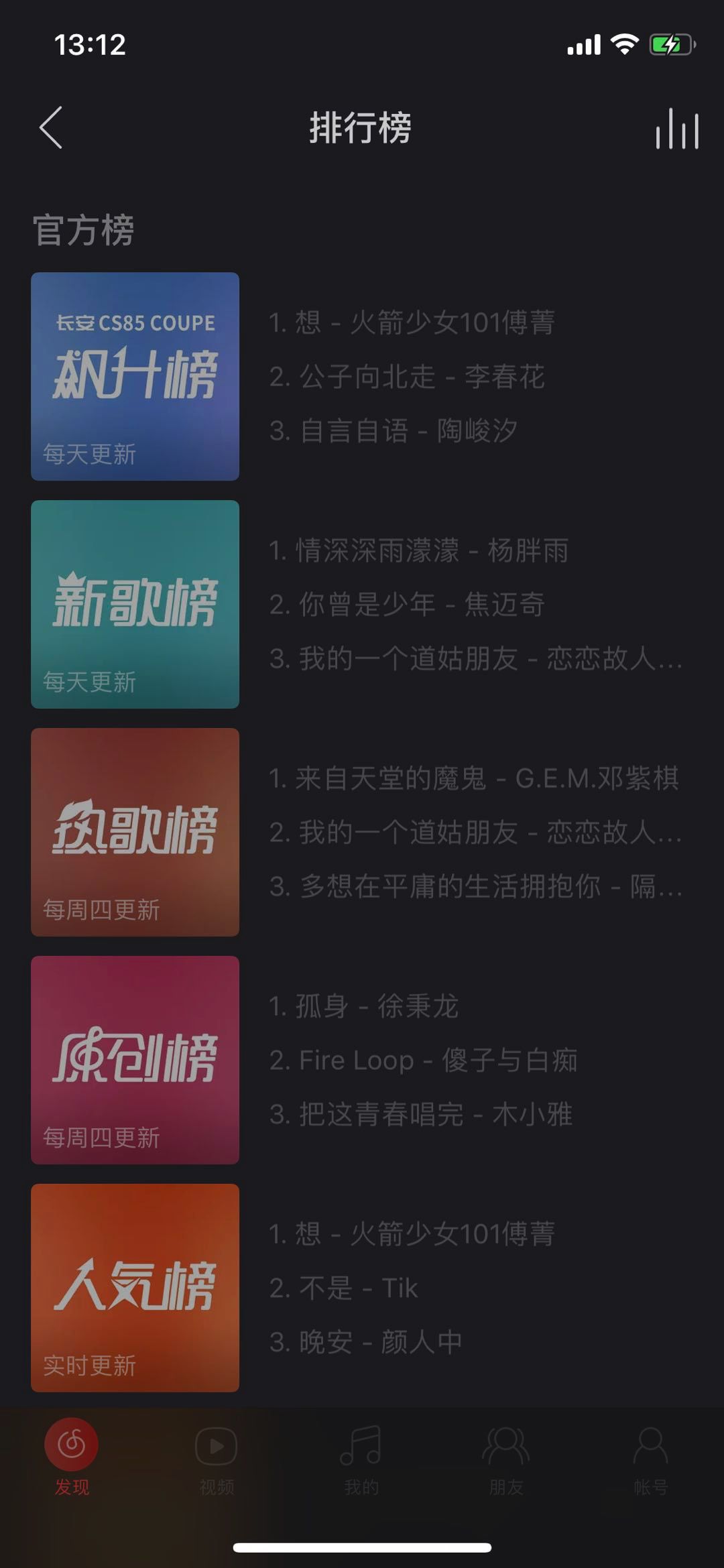
图3 网易云音乐排行榜
群组个性化就是将相同特征的用户聚合成一组,同一组用户在某些特征上具备相似性,我们为这一组用户推荐完全一样的内容。
精细化运营一般会采用该方式,通过用户画像系统圈一批人,并对这批人做统一的运营。比如视频行业的会员精细化运营,当会员快到期时,可以借助精准运营留住用户,具体可以将快到期的会员用户圈出来,针对这批用户做会员打折活动,促进用户产生新的购买。
图4是电视猫电视剧频道”战争风云“tab的基于群组的个性化重排序。我们将用户根据兴趣分组(聚类),同一组内的用户看到的内容是一样的顺序,但是不同组的用户的排序是不一样的。但是不管哪个用户其实看到的内容集合(战争风云tab的全部内容)是相同的,只不过根据用户的兴趣做了排序,把用户更喜欢的内容排在了前面。

对于天猫这类购物网站来说,对未登录用户或是冷启动的用户,可以采用基于人群属性来做推荐。通过将用户按照性别、年龄段、收货城市等粗粒度的属性划分为若干人群,然后基于每个人群的行为数据挑选出该人群点击率最高的TopK个商品作为该人群感兴趣的商品推荐给他们。该方法也是一种群组个性化推荐策略。
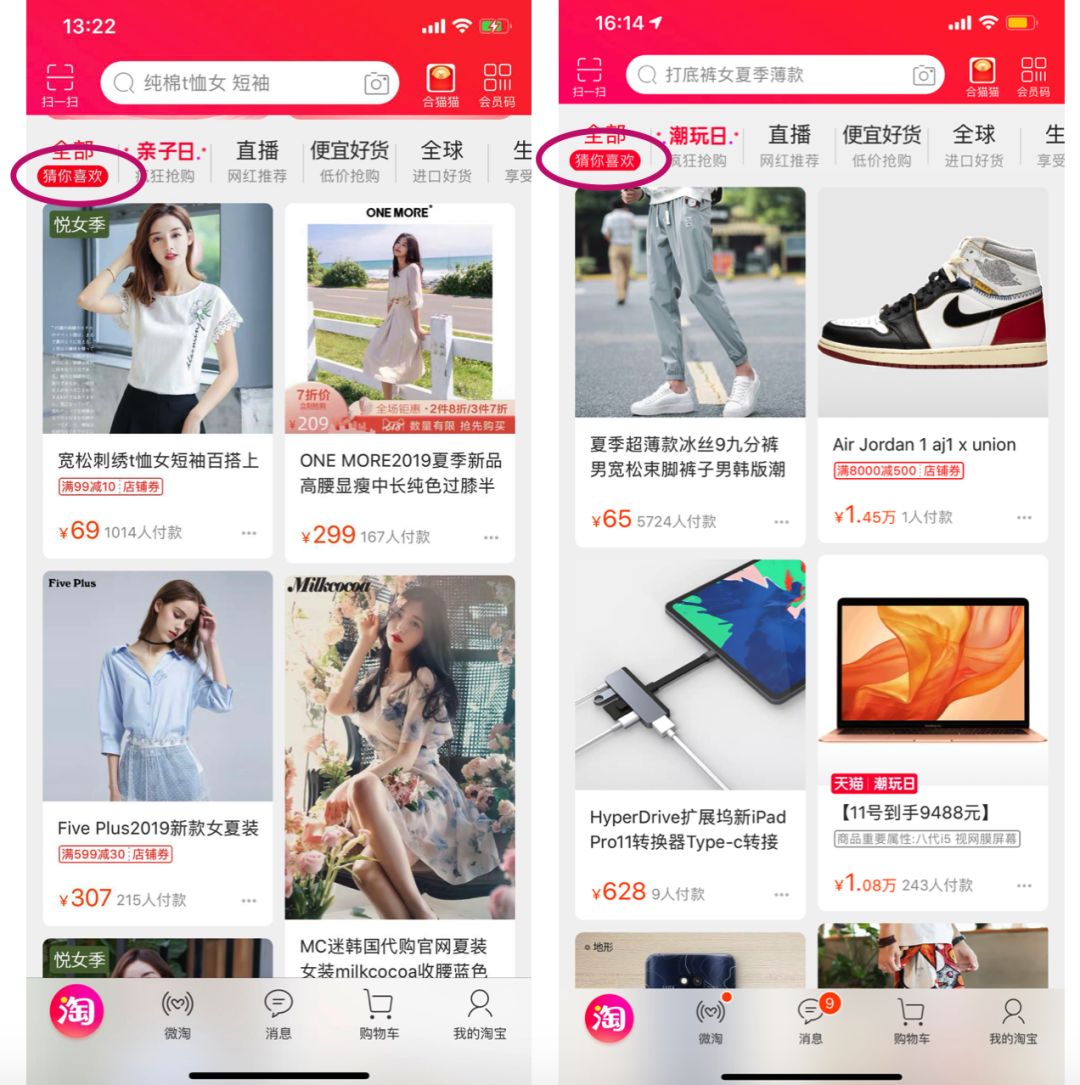
完全个性化就是为每个用户推荐的内容都不一样,是根据用户的行为及兴趣来为用户做推荐,是最常用的一种推荐形式。大多数时候我们所说的推荐就是指这种形式的推荐。图5是淘宝首页的猜你喜欢推荐,这个推荐就是完全个性化的,每个人推荐的都不一样。
完全个性化也可以基于用户的好友关系来做推荐。下面图6是微信最近上线的好物推荐,是基于社交关系的个性化推荐,将你的好友买过的商品推荐给你。
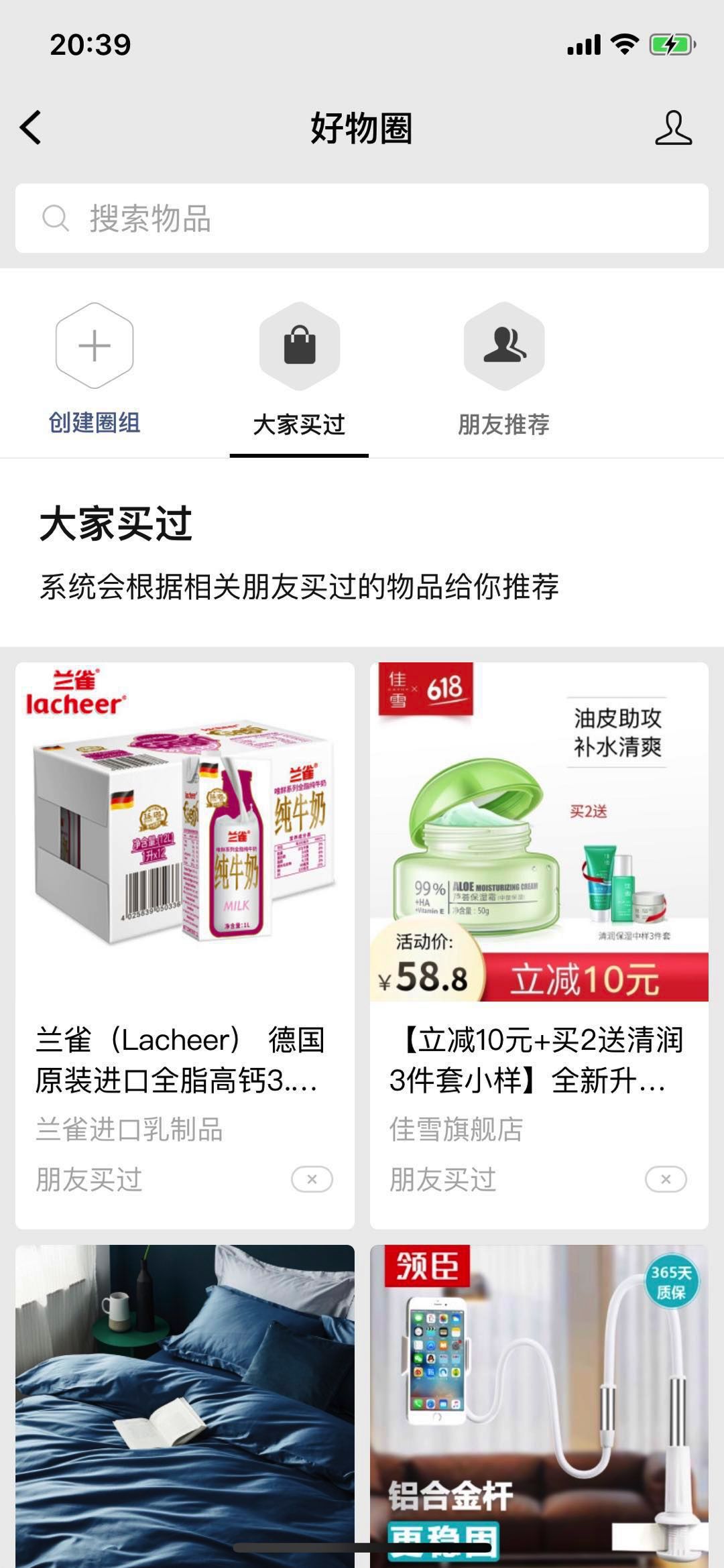
图6 微信基于社交关系的个性化好物推荐
从另外一个角度看,完全个性化推荐可以分为只基于用户个人行为的推荐和基于群组行为的推荐。基于个人行为的推荐,在构建推荐算法时只依赖个人的行为,不需要其他用户的行为,常见的基于内容推荐就是这类推荐。基于群组行为的推荐,除了利用自己的行为外,还依赖其他用户的行为构建算法模型,这类推荐可以认为是全体用户的“协同进化“,像协同过滤、基于模型的推荐等都是这类推荐形式。
2. 基于标的物维度的推荐
基于标的物维度的推荐是用户在访问标的物详情页时,或者访问后退出时,关联一批相似或者相关的标的物列表,对应我们上面提到的标的物关联标的物范式。图7是电视猫APP节目详情页的相似影片,就是常见的一类标的物关联标的物的推荐模式。
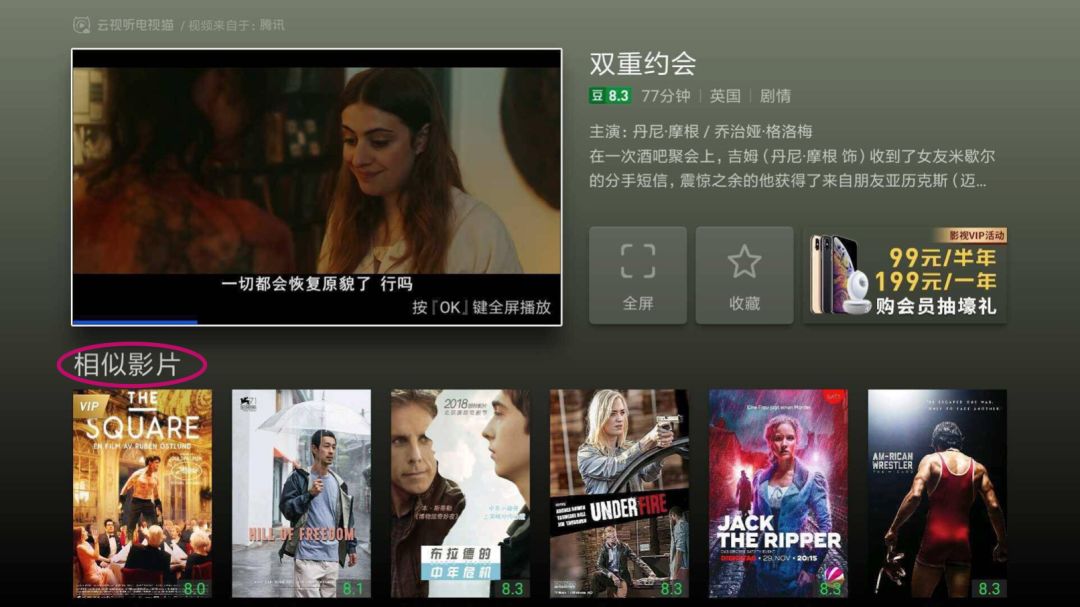
图7 电视猫电影详情页的相似影片
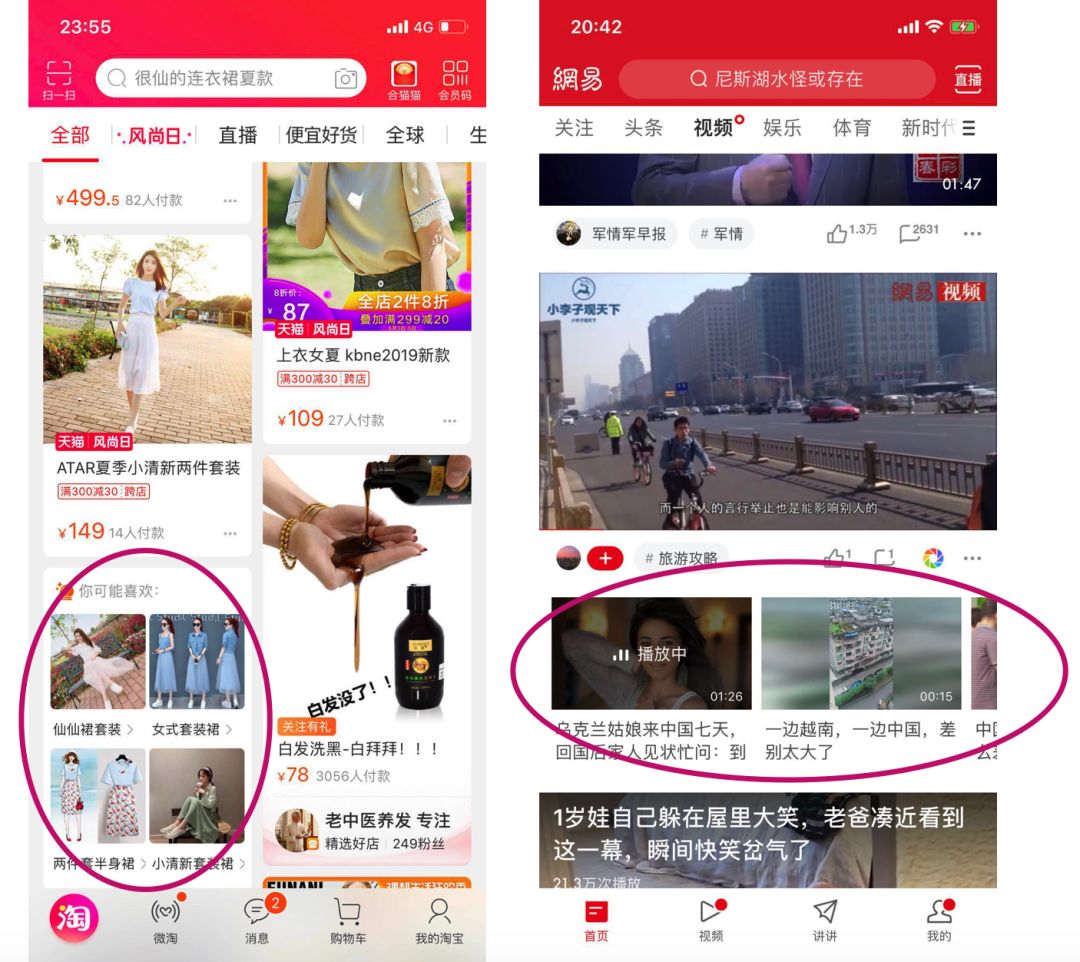
除了视频网站外,电商、短视频等APP都大量使用基于标的物维度的推荐。下面图8分别是淘宝APP和网易新闻APP上的标的物关联标的物推荐。淘宝APP上当你点击某个衣服详情页后从该详情页退出,就会在该衣服图片下面用小图展示4个相关的衣服(下面左图红色圈圈部分),网易新闻视频模块当你点击播放一个视频超过几秒后就会在该视频下面展示一行相关视频(见下面右图红色圈圈部分),如果你一直播放,当该视频播完后会播放后面的相似视频,最终形成连播推荐的效果。这两款APP的相似推荐都是非常好的推荐形态,交互非常自然流畅,毫无违和感。
3. 基于用户和标的物交叉维度的推荐
这类推荐,不同用户对同一个标的物的关联推荐是不一样的,对应我们上面提到的笛卡尔积范式。拿上面的图3来举例,如果该推荐是用户与标的物笛卡尔积式的推荐的话,不同用户看到双重约会这个电影,下面的相似影片是不一样的,推荐会整合用户的兴趣特征,过滤掉用户已经看过的电影等等。对于搜索来说,不同的人搜索同一个关键词得到的搜索结果及排序是不同的,搜索结果及排序整合了个人的历史行为特征及兴趣。
这类推荐由于每个用户在每个标的物上的推荐列表都不一样,我们没法事先将所有的组合算出并存下来(否则存储量是用户数 × 标的物数,对于互联网公司,这个数量是巨大的),我们必须在用户请求的过程中快速地为用户计算个性化的推荐列表,这对整个推荐系统的架构有更高的要求,所以在实际场景中用得比较少。
上面我们介绍了工业界常用的推荐范式及对应的产品形态,在下面一节我们对每种推荐范式涉及到的召回算法做一个综述,希望读者对这些算法有初步了解,知道在哪类产品形态上使用哪类算法。
二、推荐召回算法概述
在本节我们会根据推荐召回算法的5种范式来讲解每种范式常用的算法策略,让大家对各种算法有一个整体的了解。
1. 非个性化范式
非个性化范式就是所有用户推荐一样的标的物列表,一般各种榜单就是这类推荐,如最新榜、最热榜等等。这类排行榜就是基于某个规则来对标的物降序排列,将排序后的标的物取topN推荐给用户。比如最新榜可以根据标的物上线的时间顺序来倒序排列,取前面的topN推荐给用户。最热榜可以根据用户播放量(点击量)降序排列。
这里面可能需要考虑标的物的多品类特性,甚至还会考虑地域、时间、价格等各个维度。在具体实施时会比较复杂,需要根据具体的产品及业务场景来设计。
非个性化范式可以基于简单的计数统计来生成推荐,基本不会用到很复杂的机器学习算法。当然,用来取topN的排行榜计算公式可能会整合各类用户行为数据,公式会比较复杂(如豆瓣评分公式就比较复杂)。
非个性化范式的排行榜等算法,实现起来很简单,可解释性也很强。虽然每个用户推荐的内容都一样,但是(从生物进化上)人都是有从众心理的,大家都喜欢的东西,我们也喜欢的概率还是很大的,所以这类推荐效果还是非常不错的。这类算法也可以作为冷启动或者默认的推荐算法。
2. 完全个性化范式
完全个性化范式是最常用的推荐模式,可用的推荐方法非常多。下面对常用的算法及最新的算法进展进行简单梳理。
(1)基于内容的个性化推荐算法
这类推荐算法只依赖于用户自己的历史行为而不必知道其他用户的行为。该算法的核心思想是:标的物是有描述属性的,用户对标的物的操作行为为用户打上了相关属性的烙印,这些属性就是用户的兴趣标签,那么我们就可以基于用户的兴趣来为用户生成推荐列表。拿视频推荐来举例,如果用户过去看了科幻和恐怖两类电影,那么恐怖、科幻就是用户的偏好标签了,这时我们就可以给用户推荐科幻、恐怖类的其他电影。具体来说,我们有如下两类方法来为用户做推荐。
a 基于用户特征表示的推荐
标的物是具备很多文本特征的,比如标签、描述信息、metadata信息等。我们可以将这些文本信息采用TF-IDF或者LDA等算法转化为特征向量,如果是用标签来描述标的物,那么我们可以构建一个以标签为特征的特征向量。
有了特征向量,就可以将用户所有操作过的标的物的特征向量的(时间加权)平均作为用户的特征向量,利用用户特征向量与标的物特征向量的乘积就可以计算用户与标的物的相似度,从而计算出用户的推荐列表。
b 基于倒排索引查询的推荐
如果我们基于标签来表示标的物属性,那么基于用户的历史行为,可以构建用户的兴趣画像,该画像即是用户对各个标签的偏好,并且有相应的偏好权重。
构建完用户画像后,我们可以构建出标签与标的物的倒排索引查询表(熟悉搜索的同学应该不难理解)。基于该反向索引表及用户的兴趣画像,我们就可以为用户做个性化推荐了。该类算法其实就是基于标签的召回算法。
具体推荐过程是这样的(见下面图9):从用户画像中获取用户的兴趣标签,基于用户的兴趣标签从倒排索引表中获取该标签对应的节目,这样就可以从用户关联到节目了。其中用户的每个兴趣标签及标签关联到的标的物都是有权重的。
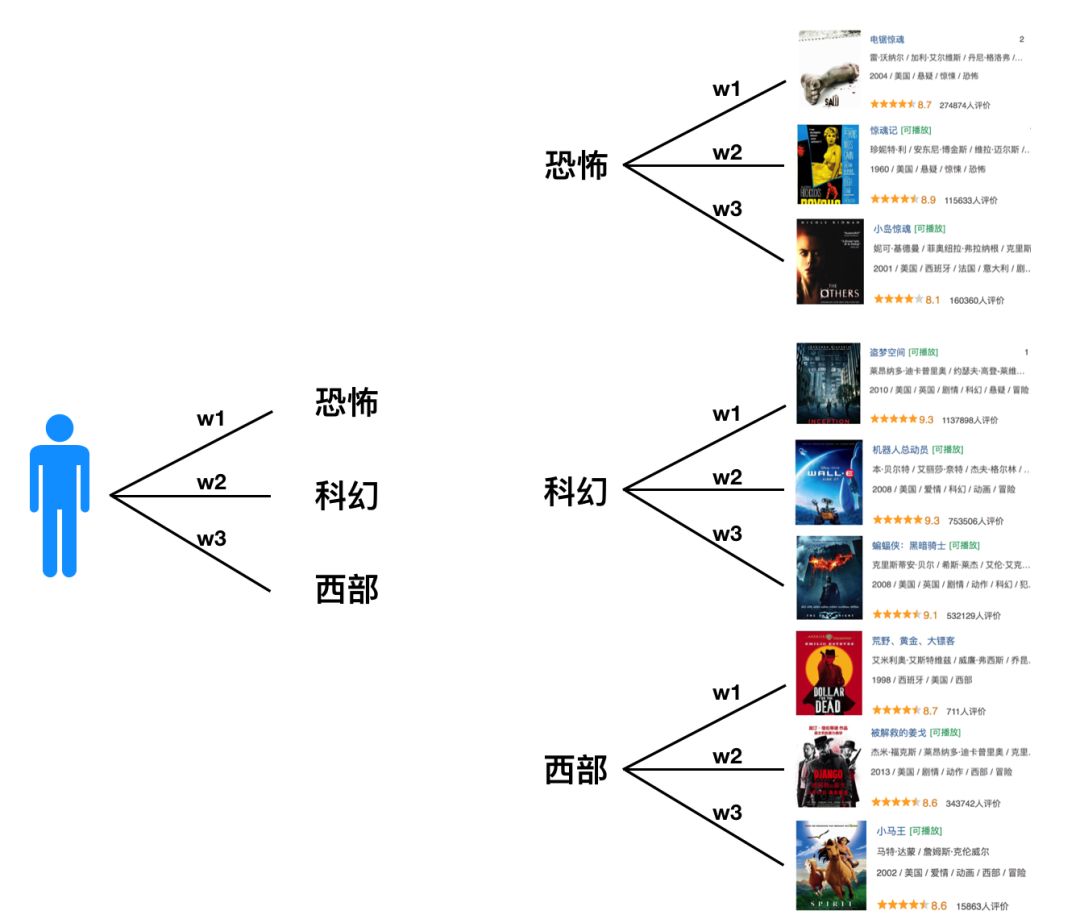
图9 基于倒排索引的电影推荐
该类推荐算法是非常自然直观的,可解释性强。同时可以较好地解决冷启动,只要用户有一次行为,就可以基于该行为做推荐。但是,该类算法往往新颖性不足,给用户的推荐往往局限在一个狭小的范围中,如果用户不主动拓展自己的兴趣空间,该方法很难为用户推荐新颖的内容。
(2)基于协同过滤的推荐算法
基于协同过滤的推荐算法,核心思想是很朴素的”物以类聚、人以群分“的思想。所谓物以类聚,就是计算出每个标的物最相似的标的物列表,我们就可以为用户推荐用户喜欢的标的物相似的标的物,这就是基于物品的协同过滤。所谓人以群分,就是我们可以将与该用户相似的用户喜欢过的标的物(而该用户未曾操作过)的标的物推荐给该用户,这就是基于用户的协同过滤。具体思想可以参考图10。
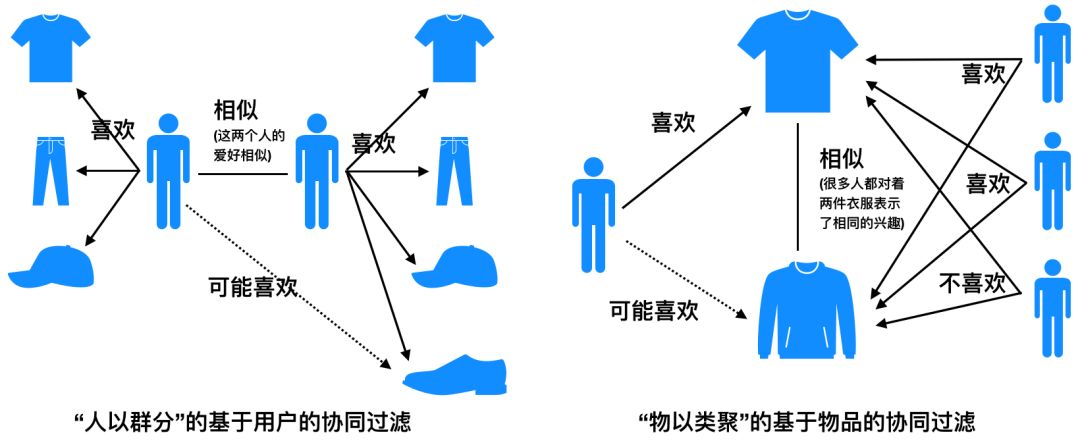
协同过滤的核心是怎么计算标的物之间的相似度以及用户之间的相似度。我们可以采用非常朴素的思想来计算相似度。
我们将用户对标的物的评分(或者隐式反馈,如点击等)构建如下矩阵(见图11),矩阵的某个元素代表某个用户对某个标的物的评分(如果是隐式反馈,值为1),如果某个用户对某个标的物未产生行为,值为0。其中行向量代表某个用户对所有标的物的评分向量,列向量代表所有用户对某个标的物的评分向量。有了行向量和列向量,我们就可以计算用户与用户之间、标的物与标的物之间的相似度了。具体来说,行向量之间的相似度就是用户之间的相似度,列向量之间的相似度就是标的物之间的相似度。相似度的计算可以采用cos余弦相似度算法。

图11:用户对标的物的操作行为矩阵
在互联网产品中一般会采用基于物品的协同过滤,因为对于互联网产品来说,用户相对于标的物变化更大,用户是增长较快的,标的物增长相对较慢,利用基于物品的协同过滤算法效果更稳定。
协同过滤算法思路非常直观易懂,计算也相对简单,易于分布式实现,也不依赖于用户及标的物的其他信息,效果也非常好,也能够为用户推荐新颖性内容,所以在工业界得到非常广泛的应用。
(3)基于模型的推荐算法
基于模型的推荐算法种类非常多,最常用的有矩阵分解算法、分解机算法等。目前深度学习算法、强化学习算法、迁移学习算法也在推荐系统中得到大规模采用。
基于模型的推荐算法基于用户历史行为数据、标的物metadata、用户画像数据等构建一个机器学习模型,利用数据训练模型,求解模型参数。最终利用该模型来预测用户对未知标的物的偏好。下面图12就是基于模型的推荐系统模型训练与预测的流程。
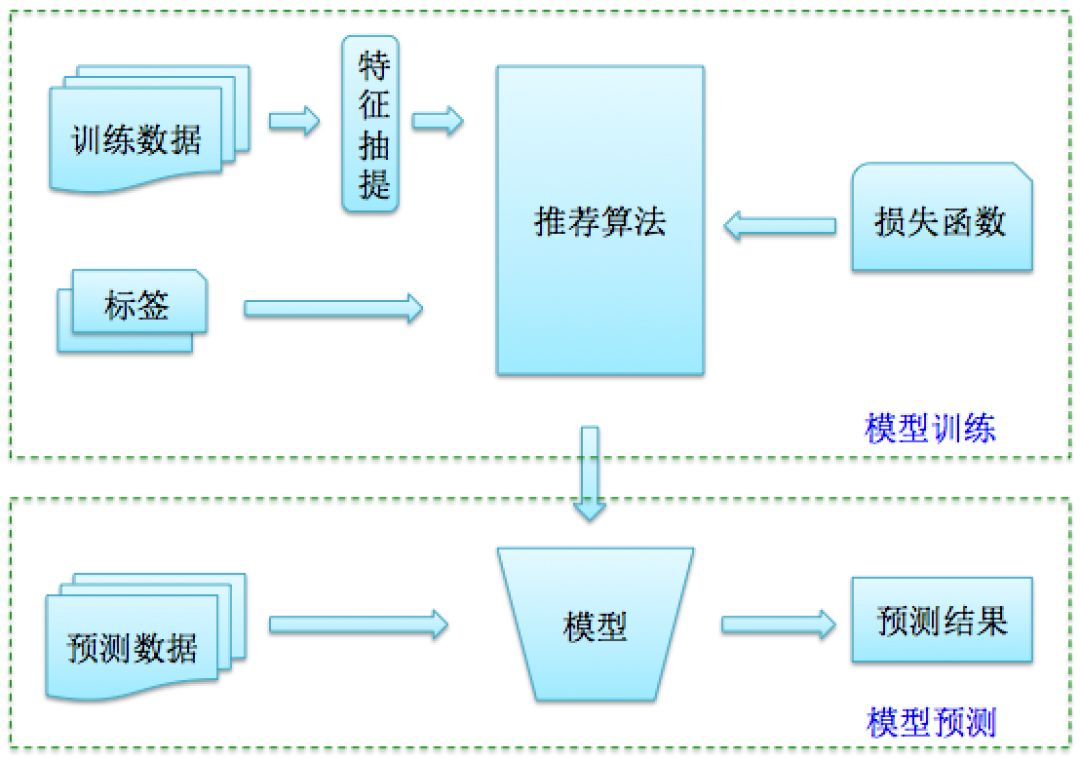
基于模型的推荐算法有三类预测方式,一类是预测标的物的评分,基于评分的大小表示对标的物的偏好程度。第二类是采用概率的思路,预测用户对标的物的喜好概率,利用概率值的大小来预测用户对标的物的喜好程度。另外一类是采用分类的思路,将每个标的物看成一类,通过预测用户下一个(几个)标的物所属的类别来做推荐。矩阵分解算法就是预测用户对标的物的评分,logistic回归算法就是概率预测方法,而youtube发表的深度学习推荐就是基于分类思路的算法(参见参考文献10)。
矩阵分解算法是将用户评分矩阵M分解为两个矩阵U、V的乘积。U代表的用户特征矩阵,V代表标的物特征矩阵。某个用户对某个标的物的评分,就可以采用矩阵U对应的行(该用户的特征向量)与矩阵V对应的列(该标的物的特征向量)的乘积。分解机算法是矩阵分解算法的推广,这里不做介绍。
随着最近几年深度学习在图像识别、语音识别领域的大获成功。有很多研究者及工业实践者将深度学习用于推荐系统,也取得了非常好的成绩,如youtube、Netflix、阿里、京东、网易、携程等,都将深度学习部署到了实际推荐业务中,并取得了非常好的转化效果(参考后面的参考文献中对应的论文)。
强化学习及迁移学习等新的方法也开始在推荐业务中崭露头角,有兴趣的读者可以阅读文末对应的参考文献。
3. 群组个性化范式
群组个性化范式需要先将用户分组,分组的原则是非常重要的。一般有如下两类分组方案。
(1)基于用户画像圈人的推荐
先基于用户的人口统计学数据或者用户行为数据构建用户画像。用户画像一般用于做精准的运营,通过显示特征将一批人圈起来,对这批人做针对性的运营。在前面也做了介绍,这里不再说明。
(2)采用聚类算法的推荐
聚类是非常直观的一种思路,将行为偏好相似的用户聚成一类,他们有相似的兴趣。常用的聚类策略有如下两类。
a 将用户嵌入一个高维向量空间,基于用户的向量表示做聚类
将用户相关特征嵌入向量空间的方式有很多,下面都是非常主流的做法。
采用基于内容推荐的思路,可以构建用户的特征向量(TF-IDF,LDA,标签等,前面已经介绍过)。有了用户的特征向量就可以聚类,该类所有用户特征向量的加权平均就是该组用户的特征向量,再利用群组特征向量与标的物特征向量的内积来计算群组与标的物的相似度,从而为该群组做个性化推荐。
采用基于用户的协同过滤的思路,可以构建用户和标的物的行为矩阵,矩阵的元素就是用户对标的物的评分,利用该矩阵的行向量就构建了一个衡量用户特征的向量,基于该特征向量可以对用户聚类。先对该组用户所有的特征向量求均值,可以取k个最大的特征,其他特征忽略不计(设置为0),最终得到该组用户的特征。最后就可以根据基于用户协同过滤的思路来为该组用户计算推荐列表了。
利用矩阵分解可以得到每个用户的特征向量,我们可以用该组用户特征向量的均值来作为该用户组的特征向量。再利用用户组的特征向量与标的物特征向量的内积来计算群组对该标的物的偏好,所有偏好计算出来后,通过降序排列就可以为该组用户推荐topN的标的物列表了。前面我们提到的电视猫的重排序算法就是基于该思路实现的。
还可以基于词嵌入的方式,将每个用户对标的物的所有操作(购买、观看等)看成一个文档集合,标的物的sid就是一个单词,采用类似word2vec的方式可以获得标的物的向量表示(见参考文献9),那么用户的向量表示就是用户操作过的所有标的物的向量表示的均值(可以采用时间加权,对最早操作的标的物给予最低的权重),这样就获得了每个用户的特征向量了。该组所有用户的平均特征向量就是该组的特征向量。这时可以采用类似上面矩阵分解的方式计算该组特征向量与标的物特征向量的内积为该组用户做个性化推荐。
除了上面几种计算群组推荐的方法外,还有一种基于计数统计的更直观的推荐方法。当我们对用户进行聚类后,我们可以对这一组用户操作过的标的物采用计数的方式统计每个标的物被操作的次数,将同一标的物的操作次数累加,最后按照标的物计数大小按照降序排列。 将标的物列表topn推荐给该组,这个topN列表就是绝大多数人喜欢的标的物。
b 基于图的聚类
我们可以构建用户关系图,顶点是用户,边是用户之间的关系,我们可以采用图的分割技术,将图分割成若干个联通子图,这些子图即是用户的聚类。还有一种方法是将图嵌入到高维向量空间中,这样就可以采用kmeans聚类方法做聚类了。有了用户的聚类就可以采用上面基于计数统计的直观方法做推荐了,或者采用更复杂的方案做推荐。
那怎么构建用户关系图呢?一般有两种方法。如果是社交类产品,可以基于社交关系来构建用户关系图,用户之间的边,代表好友关系。如果是非社交类产品,如果两个用户对同一标的物都有操作行为,那么这两个用户之间可以构建一条边。
群组个性化推荐的优势是每组给出一样的推荐,可以减少推荐的计算和存储。但该方案有一个最大的问题,同一组推荐一样的标的物列表,很可能对某个用户来说,推荐的标的物他已经看过,但是其他用户没有看过,所以无法过滤掉该标的物,针对某些用户推荐体验不够好。另外,同一组用户在兴趣特征上多少是有差别的,无法精细地照顾到每个用户的兴趣点。
群组个性化推荐的思路和优点也可以用于完全个性化范式的推荐。可以将用户先分组,每一个分组看成一个等价类(熟悉数学的同学应该很容易理解,不熟悉的同学可以理解为一个兴趣小组),同一组的用户当成一个用户,这样就可以利用完全个性化范式中的算法思路来做推荐。Google在07年发表的一篇论文(参考文献17)就是采用该思路的协同过滤实现。将用户分组可以减少计算量,支持大规模并行计算。
4. 标的物关联标的物范式
标的物关联标的物就是为每个标的物推荐一组标的物。该推荐范式的核心是怎么从一个标的物关联到一组标的物。这种关联关系可以是相似的,也可以是基于其他维度的关联。常用的推荐策略是相似推荐。下面给出4种常用的生成关联推荐的策略。
(1)基于内容的推荐
这类方法一般可以利用已知的数据和信息利用向量来描述标的物,如果每个标的物都被向量化了,那么我们就可以利用向量之间的相似度来计算标的物之间的相似度。
如果标的物是新闻等文本信息,可以采用TF-IDF将标的物映射为词向量,我们可以通过词向量的相似度来计算标的物之间的相似度。
即使不是文本,只要标的物具备metadata等文本信息,也可以采用该方法。很多互联网产品是具备用户评论功能的,这些评论文本就可以看成是标的物的描述信息。
LDA模型也非常适合文本类的推荐,通过LDA模型将文章(文档)表示为主题及相关词的概率,我们可以通过如下方式计算两个文档的相似度:先计算两个文档某个主题的相似度,将所有主题的相似度加权平均就可以得到两篇文档的相似度,而主题的相似度可以采用主题的词向量的余弦内积来表示。
(2)基于用户行为的推荐
在一个成熟的推荐产品中,会包含很多用户的行为,如用户的收藏、点赞、购买、播放、浏览、搜索等,这些行为代表了用户对标的物的某种偏好。我们可以基于该用户行为来进行关联推荐。具体的策略有如下4类。
a 比如常用的矩阵分解算法,可以将用户的行为矩阵分解为用户特征矩阵和物品特征矩阵,物品特征矩阵可以看成是衡量物品的一个向量,利用该向量我们就可以计算两个标的物之间的相似度了。
b 采用嵌入的思路做推荐。用户的所有行为可以看成是一个文档,每个标的物可以看成是一个词,我们可以采用类似word2vec的思路,最终训练出每个词(即标的物)的向量表示,利用该向量表示可以计算标的物之间的相似度。
c 我们可以将用户对标的物的所有操作行为投射到一个二维表(或者矩阵)上,行是用户,列是标的物,表中的元素就是用户对该标的物的操作(评分或者点击等隐式行为),通过这种方式我们就构建了一个二维表。这个二维表的列向量就可以用来表示标的物。这样我们就可以采用向量相似来计算标的物之间的相似度了。
d 采用购物篮的思路做推荐,这种思路非常适合图书、电商等的推荐。 经常一起购买(或者浏览)的标的物形成一个列表(一个购物篮),将过去一段时间所有的购物篮收集起来。 任何一个标的物,我们可以找到跟它出现在同一个购物篮的标的物及次数,统计完该次数后,我们就可以按照该次数降序排列,那么这个列表就可以当做标的物的关联推荐了。该推荐思路非常直观易懂,可解释性强。下面图13就是亚马逊网站上采用该思路的两类关联推荐。
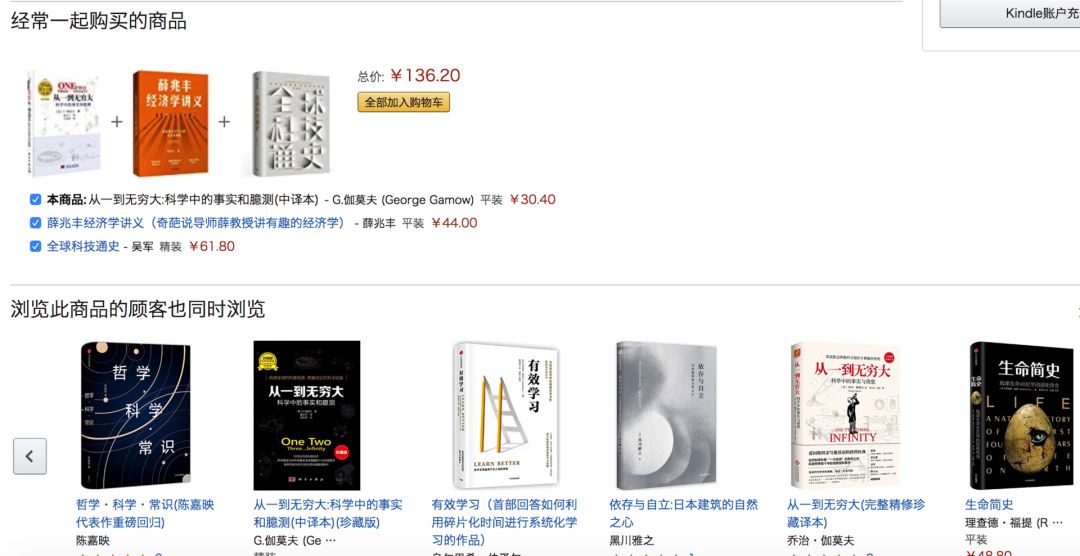
(3) 基于标签推荐
如果标的物是包含标签的,比如视频推荐。我们就可以利用标签来构建向量,每个标签代表一个维度。总标签的个数就是向量的维度,这样每个标的物就可以利用标签的向量来表示了。一般标的物的标签个数远远小于总标签的个数,所以这个向量是稀疏向量。这样我们就可以基于稀疏向量的表示来计算标的物之间的相似度了。
(4)基于标的物聚类的推荐
我们可以将标的物按照某个维度聚类,同一类具备某些相似性,那么我们在推荐时,就可以将同一类的其他标的物作为关联推荐。我们需要解决的问题是,某些类可能数量很小,不够做推荐,这时可以采用一些策略来补充(如补充热门推荐等)不足的数量。
5. 笛卡尔积范式
笛卡尔积范式的推荐算法一般可以先采用标的物关联标的物范式计算出待推荐的标的物列表。再根据用户的兴趣来对该推荐列表做重排(调整标的物列表的顺序)、增补(增加用户的个性化兴趣)、删除(比如过滤掉用户看过的)等。由于笛卡尔积范式的推荐算法在真实业务场景中使用不多,这里不再详细讲解。
到目前为止,我们讲完了常用的召回策略。召回除了根据上面的一些算法策略外,还跟具体业务及产品形态有关,可以基于更多的其他维度(如时间、地点、用户属性、收入、职业等)来做召回。
智能电视上的推荐,早上、白天、晚上推荐的不一样,节假日和平常推荐的也不一样。上班族早上需要上班,时间不充足,可能推荐短视频或者新闻更加合适,白天一般是老人在家,可以推荐戏曲、抗战类节目等,晚上主人回家又会推荐不一样的内容。
基于地点的召回,要求在不同的地方推荐不一样的标的物,典型的应用有美团外卖,你在不同的地方,给你推荐的是你所在地附近几公里范围内的餐厅。
三、排序算法概述
推荐系统排序模块将召回模块产生的标的物列表(一般几百个标的物),通过排序算法做重排,更好的反应用户的点击偏好,通过排序优化用户的点击行为,将用户更可能点击的标的物(一般几十个)取出来推荐给用户,最终提升用户体验。
排序模块会用到很多特征,基于这些特征构建排序模型,排序特征在排序的效果中起到非常关键的作用,常用的特征可以抽象为如下5大类:
用户侧的特征,如用户的性别、年龄、地域、购买力、家庭结构等。
商品侧的特征,如商品描述信息、价格、标签等。
上下文及场景特征,如位置、页面、是否是周末节假日等。
交叉特征,如用户侧特征与商品侧特征的交叉等。
用户的行为特征,如用户点击、收藏、购买、观看等。
排序框架需要充分利用上述五大类特征,以便更好的预测用户的点击行为。排序学习是机器学习中一个重要的研究领域,广泛应用于信息检索、搜索引擎、推荐系统、计算广告等的排序任务中,有兴趣的读者可以参考微软亚洲研究院刘铁岩博士的专著《Learning to Rank for Information Retrieval》。常用的排序算法框架有pointwise、pairwise、listwise三类,见图14。
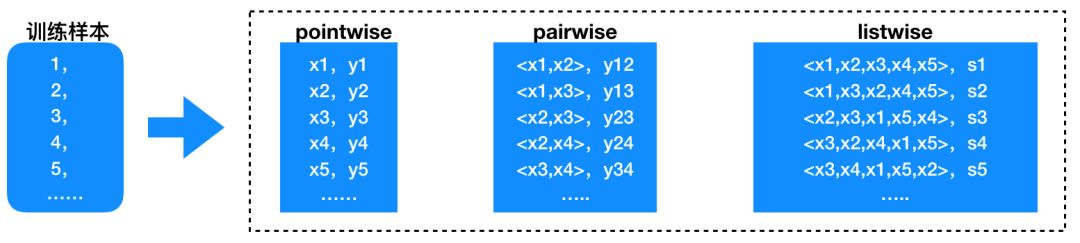
上图中x1,x2,... 代表的是训练样本1,2,... 的特征,y1,y2,s1,... 等是训练集的label(目标函数值)。pointwise学习单个样本,如果最终预测目标是一个实数值,就是回归问题,如果目标是概率预测,就是一个分类问题,例如CTR预估。pairwise和listwise分别学习一对有序对和一个有序序列的样本特征,考虑得更加精细。在推荐系统中常用pointwise方法来做排序,它更直观,易于理解,也更简单。
常用的排序学习算法有logistic回归、GBDT、Wide & Deep等,这里对这些算法的实现原理做一个简单描述。
1. logistic回归模型
logistic回归是比较简单的线性模型,通过学习用户点击行为来构建CTR预估。利用logistic回归构建推荐算法模型,具体模型如下面公式。
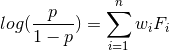
其中,p 是用户喜欢某个标的物的概率;
是权重,是需要学习的模型参数;
是特征i的值,特征如上面所述,有5大类可用特征。
我们可以通过上述公式计算待推荐标的物的p值。最终我们可以按照p值的大小降序排列来对召回的标的物列表做排序。
在工业界,为了更好地将该模型应用到真实业务场景中,很多公司对logistic回归模型做了推广。比如用到在线实时推荐场景中做排序,有Google在2013年推广的FTRL(见参考文献14),以及阿里推广的分片线性模型(见参考文献13)。
2. GBDT模型
GBDT(Gradient Boosting Decision Tree)是一种基于迭代思路构造的决策树算法(可以参考文献15),该算法在实际问题中将生成多棵决策树,并将所有树的结果进行汇总来得到最终答案,该算法将决策树与集成思想进行了有效的结合,通过将弱学习器提升为强学习器的集成方法来提高预测精度。GBDT是一类泛化能力较强的学习算法。
2014年Facebook发表了一篇介绍将GBDT+LR(Logistic Regression)模型用于其广告CTR预估的论文(参考文献16),开启了利用GBDT模型应用于搜索、推荐、广告业务的先河。GBDT作为一种常用的树模型,可天然地对原始特征进行特征划分、特征组合和特征选择,并得到高阶特征属性和非线性映射。从而可将GBDT模型抽象为一个特征处理器,通过GBDT分析原始特征获取到更利于LR分析的新特征,这也正是GBDT+LR模型的核心思想——利用GBDT构造的新特征来训练LR模型。
3. Wide & deep模型
Wide&deep模型最早被Google提出来,并用于Android手机应用商店上APP的推荐排序。目前该算法在国内很多互联网企业得到大规模的采用,有比较好的效果。该模型将传统模型和深度学习模型相结合。wide部分(传统模型,如logistic回归)起记忆(memorization)的作用,即从历史数据中发现item(推荐内容)或者特征之间的相关性,deep部分(深度学习模型)起泛化(generalization)的作用,即相关性的传递,发现在历史数据中很少或者没有出现的新的特征组合,寻找用户的新偏好。通过将这两个模型结合起来可以更好地在用户的历史兴趣和探索新的兴趣点之间做到平衡。感兴趣的读者可以阅读参考文献12。
四、推荐算法落地需要关注的几个问题
前面几节对推荐系统算法和产品做了初步描述,相信大家对常用算法实现思路、怎么用于真实产品中有了比较直观的认识。在本节作者对算法落地中几个重要问题加以说明,以便你可以更好地将推荐算法落地到真实业务场景中。
1. 推荐算法工程落地是否一定需要排序模块
工业上的推荐算法一般分为召回和排序模块,召回的作用是从全量标的物集合(几万甚至上亿)中将用户可能喜欢的标的物取出来(几百个),排序阶段将召回的标的物集按照用户点击的可能性再做一次排序。但是排序阶段不是必须的,特别是对于标的物池不大的产品及团队资源较少的情形,没必要一开始就开发出排序框架。召回算法一般也会对标的物做排序(如果是评分预测模型,如矩阵分解,可以按照评分大小排序,如果是概率模型,可以按照对标的物的偏好概率大小排序)。缺失了排序模块的推荐系统可能精准度没有那么高,但是工程实现上相对更加简单,可以快速落地上线。特别对于刚做推荐系统的团队,可以让系统快速上线,后面再逐步迭代,补全缺失模块。
2. 推荐算法服务于用户的两种形式
推荐算法计算出的推荐结果可以直接插入数据库(如Redis等),直接为用户提供服务,另外一种方式是将核心特征计算好存储下来,当用户请求推荐业务时,推荐web服务通过简单计算将特征转化为最终给用户的推荐结果返回给用户。这两种方式一个是事先计算好,拿来就用,另外一种是准备好核心数据,在请求时实时计算最终结果。
我拿餐厅服务外卖来类比说明,第一种方式是将餐厅有的菜先做好很多份,如果有外卖单过来,直接将做好的送出。第二种是将所有的配菜都准备好,接到外卖单立马将配菜加上调料炒熟再送出去,只要配菜准备足够好,炒菜的时间不太长并且可控,也是可以很好的服务用户的。第一种方式是事先做好的,无法满足用户个性化需求,同时如果做好了没人点的话就浪费了,第二种可以更好满足用户个性化需求,比如用户说不要香菜多放辣椒就可以在现做的时候满足。
第二种方式对整个推荐系统要求更高,服务更加精细,但是第一种方案更加简单,不过也需要更多的存储资源(将所有用户的推荐结果事先存下来)。在推荐系统构建的初级阶段建议采用方案一。
某些推荐业务用方案一是不可行的,比如上面的笛卡尔积范式的推荐系统,因为用户数乘以标的物数是一个巨大的天文数字,公司不可能有这么多的资源将每个用户关联的每个标的物的推荐结果事先计算好存储下来。
3. 推荐系统评估
推荐系统是服务于公司商业目标的(盈利目标,提升用户体验、使用时长、DAU等,最终也是为了盈利),所以推荐系统落地到真实业务场景中一定要定义推荐系统的优化目标,只有目标具体而清晰,并可量化,才能更好的通过不断迭代优化推荐效果。大家可以参考《推荐系统的商业价值》(点击蓝字可回顾)这篇文章,了解怎么定义推荐系统的商业指标。
五、总结
本文对工业级推荐系统的产品形态、推荐算法依赖的数据、算法业务流程、具体召回和排序算法做了概述,希望读者对推荐产品的落地形态有初步了解,同时知道每类推荐范式有哪些可用的算法,以及相关算法的实现思路。在后续文章中,作者会详细讲解主流核心算法的实现细节,欢迎大家持续关注!
参考文献:
1.Multi-Interest Network with Dynamic Routing for Recommendation at Tmall
2.Deep Session Interest Network for Click-Through Rate Prediction
3.Behavior Sequence Transformer for E-commerce Recommendation in Alibaba
4.Billion-scale Commodity Embedding for E-commerce Recommendation in Alibaba
5.Personal Recommendation Using Deep Recurrent Neural Networks in NetEase
6.Deep Reinforcement Learning for List-wise Recommendations
7.Recommendations with Negative Feedback via Pairwise Deep Reinforcement Learning
8.Learning Tree-based Deep Model for Recommender Systems
9.Item2Vec- Neural Item Embedding for Collaborative Filtering
10.Deep Neural Networks for YouTube Recommendations
11.Deep Learning based Recommender System- A Survey and New Perspectives
12.Wide & Deep Learning for Recommender Systems
13.Learning Piece-wise Linear Models from Large Scale Data for Ad Click Prediction
14.Ad Click Prediction- a View from the Trenches
15.Greedy function approximation: a gradient boosting machine
16.Practical Lessons from Predicting Clicks on Ads at Facebook
17.Google News Personalization: Scalable Online Collaborative Filtering
(*本文为 AI科技大本营转载文章,转载请联系原作者)
◆
精彩推荐
◆
参与投稿加入作者群,成为全宇宙最优秀的技术人~


推荐阅读






