业界 | OpenAI提出新型元学习方法EPG,调整损失函数实现新任务上的快速训练
选自OpenAI
机器之心编译
参与:路雪、刘晓坤
刚刚,OpenAI 提出一种实验性元学习方法 Evolved Policy Gradients(EPG),该方法演化学习智能体的损失函数,从而实现在新任务上的快速训练。
OpenAI 发布一种实验性元学习方法 Evolved Policy Gradients(EPG),该方法从学习智能体的损失函数发展而来,可实现在新任务上的快速训练。测试时,使用 EPG 训练的智能体可在超出训练范畴的基础任务上取得成功,比如学习从训练时某物体的位置导航至测试时该物体的位置(房间另一侧)。
论文地址:https://storage.googleapis.com/epg-blog-data/epg_2.pdf
代码地址:https://github.com/openai/EPG
EPG 训练智能体,使其具备如何在新任务中取得进展的先验知识。EPG 没有通过学得的策略网络编码先验知识,而是将其编码为学得的损失函数。之后,智能体就能够使用该损失函数(被定义为时序卷积神经网络)快速学习新任务。OpenAI 展示了 EPG 可泛化至超出分布(out of distribution)的测试任务,其表现与其他流行的元学习算法有质的不同。在测试中,研究人员发现 EPG 训练智能体的速度快于 PPO(一种现成的策略梯度方法)。EPG 与之前为强化学习智能体设计适合的奖励函数的研究(Genetic Programming for Reward Function Search 等)有关,不过 EPG 将这个想法泛化至演化一个完整的损失函数,这意味着损失函数必须高效学习内部的强化学习算法。
第一个视频展示了 OpenAI 的方法如何教会机器人在不重置环境的情况下到达不同的目标,第二个视频是 PPO 方法。左上的数字表示目前的学习更新次数。注意该视频展示了完整的实时学习过程。
EPG 背后的设计知觉来自于我们都很熟悉的理念:尝试学习新技巧,经历该过程中挫折和喜悦的交替。假设你刚开始学习拉小提琴,即使没有人指导,你也立刻可以感觉到要尝试什么。听自己弹奏出的声音,你就能感觉到是否有进步,因为你具备完善的内部奖励函数,该函数来源于其他运动任务的先验经验,并且通过生物进化的过程演化而来。相反,大部分强化学习智能体在接触新任务时未使用先验知识,而是完全依赖于外部奖励信号来指导初始行为。从空白状态开始,也就难怪当前的强化学习智能体在学习简单技巧方面比人类要差得远了。EPG 通过过去在类似任务上的经验,朝「不是空白状态、知道怎么做才能完成新任务」的智能体迈出了一步。

EPG 包含两个优化循环。在内部循环中,智能体从头学习解决从一类任务中采样的特定任务。这类任务可能是「移动抓器到某个位置 [x, y]」。内部循环使用随机梯度下降(SGD)来优化智能体策略,对抗外部循环中的损失函数。外部循环评估内部循环学习所得的返回结果,并使用进化策略(ES)调整损失函数的参数,以提出可带来更高返回结果的新型损失函数。
具备学得的损失函数比当前的强化学习方法有多个优势:使用进化策略来演化损失函数允许我们优化真正的目标(最终训练出的策略性能)而不是短期返回结果,EPG 通过调整损失函数适应环境和智能体历史,从而优于标准的强化学习算法。


上图展示了 OpenAI 的方法如何教会机器人反向跳跃,下面的图是 PPO 方法。EPG 带来了智能体的探索行为,智能体在意识到反向行走会带来高奖励之前已经尝试反向行走了。左上的数字表示目前的学习更新次数。注意该视频展示了完整的实时学习过程。
近期出现了大量关于元学习策略的研究,我们必须要问为什么学习损失函数,而不是直接学习策略?学习循环策略可能会使当前任务出现过拟合,而学习策略初始化会在探索时限制表达性。OpenAI 的动机是期望损失函数可以很好地泛化至大量不同任务中。这当然适用于手工调整的损失函数:设计完备的强化学习损失函数(如 PPO 中的损失函数)可以广泛应用于大量任务(从 Atari 游戏到控制机器人)。
为了测试 EPG 的泛化能力,研究者设置了一个简单的实验,演化 EPG 损失直到智能体「蚂蚁」有效地移动到圆形运动场右侧的随机目标位置。然后,固定损失函数,给蚂蚁一个新的目标,这一次是左侧的位置。令人惊讶的是,蚂蚁学会了走到左侧!以下是它们的学习曲线展示(红线):
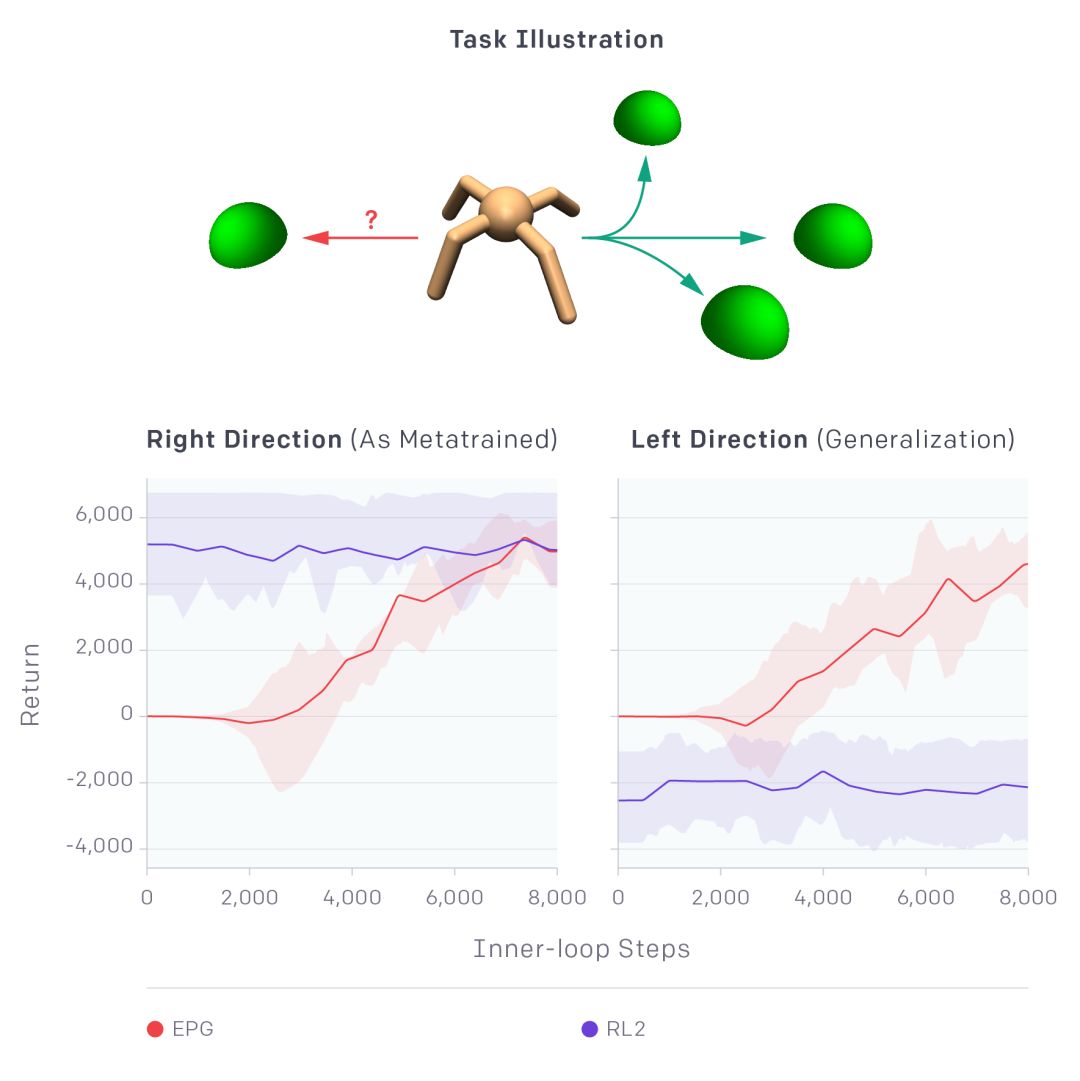
结果非常好,因为它展示了在「超出训练分布」的任务中的泛化效果。这种泛化很难达到。OpenAI 研究人员将 EPG 与另一种元学习算法 RL2 进行了对比,后者尝试直接学习可用于新型任务的策略。实验表明,RL2 确实可以成功地让智能体走向屏幕右侧的目标。但是,如果测试时的目标是在屏幕左侧,则智能体失败,还是一直向右走。也就是说,其对训练任务设置(即向右走)产生「过拟合」。

上述视频(见原文)展示了 OpenAI 的方法(左)如何从头开始教会机器人行走和到达目标(绿色圈),右侧是 RL2。左上的数字表示目前的学习更新次数。注意该视频展示了 3X 实时速度时的完整学习过程。
和所有的元学习方法一样,该方法仍然存在许多限制。现在,我们可以训练一次性处理一类任务的 EPG 损失函数,例如,让一只蚂蚁左右走。然而,面向这类任务的 EPG 损失函数对其他不同类任务未必有效,例如玩《太空侵略者》游戏。相比之下,标准的 RL 损失具备这种泛化能力,同一损失函数可被用于学习大量不同的技能。EPG 获得了更好的表现,却失去了泛化能力。要想同时得到性能与泛化能力,元学习方法还有很长的路要走。

原文链接:https://blog.openai.com/evolved-policy-gradients/
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:editor@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com



