详解这场图片分类赛baseline,赢取官方人才认证+奖金


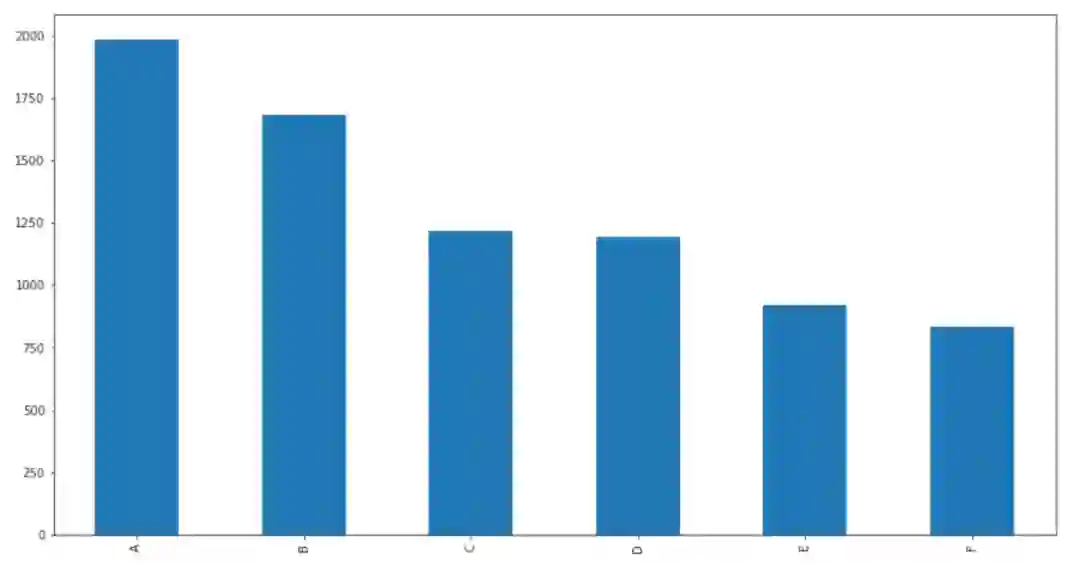
本次比赛将提供10,000张垃圾图片,其中8000张用于训练集,1,000张用于测试集。其中,每张图片中的垃圾都属于纸类、塑料、金属、玻璃、厨余、电池这六类垃圾中的一类。
-
train.zip,训练集,包括7831张垃圾图片。 -
validation.zip,测试集,包括2014张垃圾图片。 -
train.csv,训练集图片标签,标签为A-F,分别代表厨余、塑料、金属、纸类、织物、玻璃。
首先我们可以对赛题数据进行可视化,这里使用opencv读取图片并进行操作:
def show_image(paths):
plt.figure(figsize=(10, 8)) for idx, path in enumerate(paths):
plt.subplot(1, len(paths), idx+1)
img = cv2.imread(path)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
plt.imshow(img)
plt.xticks([]); plt.yticks([])


在构建模型并进行训练之前,非常建议将训练集图片提前进行缩放,这样加快图片的读取速度,也可以加快模型的训练速度。具体的缩放代码如下:
import cv2, glob, osimport numpy as np
os.mkdir('train_512')
os.mkdir('validation_512')for path in glob.glob('./train/*'): if os.path.exists('train_512/' + path.split('/')[-1]): continue
img = cv2.imread(path) try:
img = cv2.resize(img, (512, 512))
cv2.imwrite('train_512/' + path.split('/')[-1], img) except: passfor path in glob.glob('./validation/*'): if os.path.exists('validation_512/' + path.split('/')[-1]): continue
img = cv2.imread(path) try:
img = cv2.resize(img, (512, 512))
cv2.imwrite('validation_512/' + path.split('/')[-1], img) except:
img = np.zeros((512, 512, 3))
cv2.imwrite('validation_512/' + path.split('/')[-1], img)
Pytorch版本baseline
-
定义数据集 -
定义模型 模型训练和预测
class BiendataDataset(Dataset): def __init__(self, img_path, img_label, transform=None):
self.img_path = img_path
self.img_label = img_label
self.transform = transform def __getitem__(self, index): try:
img = Image.open(self.img_path[index]).convert('RGB') except:
index = 0
img = Image.open(self.img_path[index]).convert('RGB') if self.transform is not None:
img = self.transform(img)
label = torch.from_numpy(np.array([self.img_label[index]])) return img, label def __len__(self): return len(self.img_path)
预训练模型推荐使用efficientnet,模型精度会更好。
import timm
model = timm.create_model('efficientnet_b4', num_classes=6,
pretrained=True, in_chans=3)
具体的数据扩增方法为:
transforms.Compose([
transforms.Resize((300, 300)),
transforms.RandomHorizontalFlip(),
transforms.RandomVerticalFlip(),
transforms.RandomAffine(5, scale=[0.95, 1.05]),
transforms.RandomCrop((256, 256)),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
TF2.0版本baseline
如果使用TF2.0,则更加简单:
-
定义ImageDataGenerator -
定义模型 -
模型训练和预测
from efficientnet.tfkeras import EfficientNetB4
models = EfficientNetB4(weights='imagenet', include_top=False)
train_datagen = ImageDataGenerator(
rescale=1. / 255, # 归一化
rotation_range=45, # 旋转角度
width_shift_range=0.1, # 水平偏移
height_shift_range=0.1, # 垂直偏移
shear_range=0.1, # 随机错切变换的角度
zoom_range=0.25, # 随机缩放的范围
horizontal_flip=True, # 随机将一半图像水平翻转
fill_mode='nearest' # 填充像素的方法
)
1. 对数据集图片的主体物体进行定位&检测;
2. 通过五折交叉验证,训练得到5个模型然后对测试集进行投票;
3. 对测试集结果进行数据扩增,然后进行投票。

🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧

登录查看更多
相关内容

Arxiv
0+阅读 · 2022年4月5日




相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2022年4月5日