“寓教于乐”,DeepMind新研究让机器人从0开始学习复杂精细动作
夏乙 编译自 DeepMind blog
量子位 出品 | 公众号 QbitAI

别小看这个笨拙地抓起、移动着物体的机器人,它可是DeepMind的最新研究成果。
有什么特别之处呢?这个机械臂可是在现实世界中直接训练的,没有搞现在模拟器里训练一个智能体,再迁移出来那一套。
这项研究,就是DeepMind今天在官方博客上介绍的“寓教于乐”,让模拟环境和现实世界中的机器人,都能通过一系列微小的辅助任务,来学习一个比较复杂的任务。
量子位将DeepMind博客内容翻译整理如下:
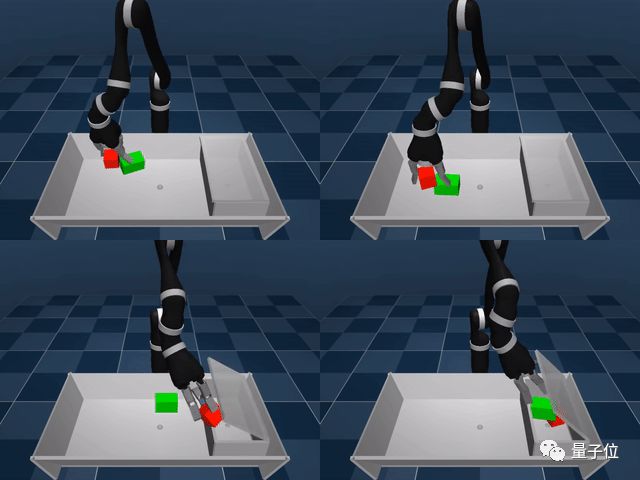
一个AI智能体(agent)要想完成像收拾桌子、堆起东西这样的控制类任务,需要知道该在什么时候、在什么地方、如何协调它那模拟机械手臂和手指上的9个关节,才能正确地移动,达到目标。
要解决一个探索问题,智能体往往需要执行一长串正确的动作,而且每个时间点上,各个关节的动作组合都有着非常多的可能性。于是,这就成了强化学习研究非常感兴趣的领域。
塑造奖励、学徒式学习、示范学习等技巧在探索问题上有一些用处,但这些方法依赖于大量关于任务的知识。因此,在只有最低限度先验知识的情况下,从0开始学习复杂控制问题依然是一个公开的挑战。
DeepMind的新论文Learning by Playing - Solving Sparse Reward Tasks from Scratch提出了一种新的学习范式来攻克探索问题,名叫“预定辅助控制(SAC-X)”。这种方法基于这样一个想法:智能体要从0开始学习复杂的任务,首先要学习探索并掌握一套基本技能。正如婴儿能爬会走之前要发展出协调和平衡能力,给智能体提供与简单技能相对应的内在辅助目标,也能提高他理解并执行更复杂任务的机会。

他们在集中模拟的和真实的机器人上演示了SAC-X方法,所用的任务从堆叠物体到打扫操场(把东西放进盒子里)。为这些任务定义辅助任务遵循一个总原则:鼓励智能体探索感应空间,比如激活手指上的触觉传感器、感测手腕上的力、在抱呢提感受传感器中最大化一个关节角度、或者推动它视觉相机传感器中一个物体的运动等。每个任务在目标完成时都能得到一个简单的奖励1,否则是0。

△ 智能体学习的第一个辅助任务:激活手指上的触摸传感器并移动这两个物体

△ 模拟智能体最终掌握了“堆叠”物体这一复杂任务
得到辅助任务后,智能体能自己决定它当前的“意图”,也就是下一步要追求的目标,可能是另一个辅助任务,也可能是外部定义的目标任务。
最重要的是,通过广泛使用基于重播的off-policy学习,智能体能从它目前没有执行的其他任务中探测奖励信号并从中学习。比如说,智能体可能会在拿起、移动一个物体时,顺便堆叠了物体,这个任务也会让它观察到一个为堆叠所设置的奖励。
因为一系列简单任务可能会引导智能体观察到罕见的额外奖励,于是,预定意图的能力就至关重要。它可以根据所收集的相关知识创建个性化的“课程”,事实证明着是一种在庞大领域探索知识点有效方法,当没有多少外部奖励信号可用时特别管用。
智能体会通过预定的模块来决定该向哪个意图努力,预定程序在训练过程中通过元学习来进化,来最大化主任务的进度,也就显著提高了数据效率。

△ 通过探索很多内部辅助任务,智能体学会了如何堆叠和整理物体
论文中的评估结果显示,SAC-X能用同样的辅助任务,从0开始学习解决研究者们设置的所有任务。
更一颗赛艇的是,现实世界的机械臂也能通过SAC-X来从0开始学习拾取和放置物体。这类研究非常富有挑战性,因为现实世界中的机器人要学习,需要极好的数据效率,所以通常会先在模拟环境中训练一个智能体,然后再将它迁移到真实的机械臂上。
我们来看一下这个机械臂:
△ 真正的机械臂在执行一个它从未见过的任务:拿起并移动这个绿色方块
DeepMind介绍说,他们认为SAC-X是从0开始学习控制任务的重要一步。用这种方法,只需要指定整体目标,辅助任务则可以任意定义,可以基于普遍观点来设置,像本文中所讲的激活各类传感器,也可以是研究人员认为重要的任何任务。
在这方面,SAC-X是一种通用的强化学习方法,除了用在控制和机器人上之外,也广泛适用于一般稀疏强化学习环境。
原文:https://deepmind.com/blog/learning-playing/
论文:
Learning by Playing - Solving Sparse Reward Tasks from Scratch
Martin Riedmiller, Roland Hafner, Thomas Lampe, Michael Neunert, Jonas Degrave, Tom Van de Wiele, Volodymyr Mnih, Nicolas Heess, Jost Tobias Springenberg
https://arxiv.org/abs/1802.10567
— 完 —
加入社群
量子位AI社群13群开始招募啦,欢迎对AI感兴趣的同学,加小助手微信qbitbot5入群;
此外,量子位专业细分群(自动驾驶、CV、NLP、机器学习等)正在招募,面向正在从事相关领域的工程师及研究人员。
进群请加小助手微信号qbitbot5,并务必备注相应群的关键词~通过审核后我们将邀请进群。(专业群审核较严,敬请谅解)
诚挚招聘
量子位正在招募编辑/记者,工作地点在北京中关村。期待有才气、有热情的同学加入我们!相关细节,请在量子位公众号(QbitAI)对话界面,回复“招聘”两个字。

量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态


