推特800赞,DeepMind强化学习综述:她可以很快,但快从慢中来
栗子 发自 凹非寺
量子位 报道 | 公众号 QbitAI
能下围棋、能打刀塔、能玩星际……深度强化学习 (DRL) 就快称霸世界了。
但业界一直有种常见的担忧:
强化学习 (RL) 太慢。人类一两盘就能学会的游戏,AI可能要和游戏环境互动上亿次才能解锁。样本效率低,模拟不出人类学习的过程。
现在,DeepMind团队用新近的研究成果总结,来告诉大家这种担忧不值得:
深度强化学习已经有了非常快速且灵活的技术。
并且,从AI领域诞生的方法,也能为人类的心理学和神经科学带来新的理解。

这篇深度强化学习综述,已经获得了推特观众的799赞。
为什么会慢
最近五年,是DRL爆发的时期。一开始,就像人们批判的那样,算法的确学得很慢。

但要让它快起来,首先要知道为什么慢。
DeepMind举出了两个主要原因:
一是增量式的参数更新 (Incremental Parameter Adjustment) 。最初的算法,从输入的周围环境,到输出的AI动作之间,是靠梯度下降来完成映射的。
在这个过程中,每个增量都需要非常小,才不至于让新学到的信息,把之前学到的经验覆盖了 (这叫做“灾难性干扰”) 。如此一来,学习过程便十分缓慢。
二是弱归纳偏置 (Weak Inductive Bias) 。任何学习过程,都要面临“偏见-方差权衡”。
所谓偏见,就是一开始限定好一些可能的结果,AI从里面找出自己想要的那一种。限定越窄,AI就可以只考虑为数不多的可能性,更快地得出结果。
弱归纳偏置,就需要考虑更多的可能性,学习也就慢一些。重要的是,通用神经网络都是偏见极低的系统,他们有非常大量的参数,可以用来拟合大范围的数据。
DRL,就是把深度网络用到RL里面。所以,最初样本效率必然是极低,需要大量数据来学习。
快从慢中来
不过,从最近的研究上看, 这两个问题都是有办法解决的。
DeepMind举出了两种方法,对症下药。
首先,解决参数增量的问题:
方法是情节性深度强化学习 (Episodic DRL) 。就是给过去发生的事件,保留一个明确的记录 (Explicit Record) 。这个记录会作为依据,指导AI做出新的决策。
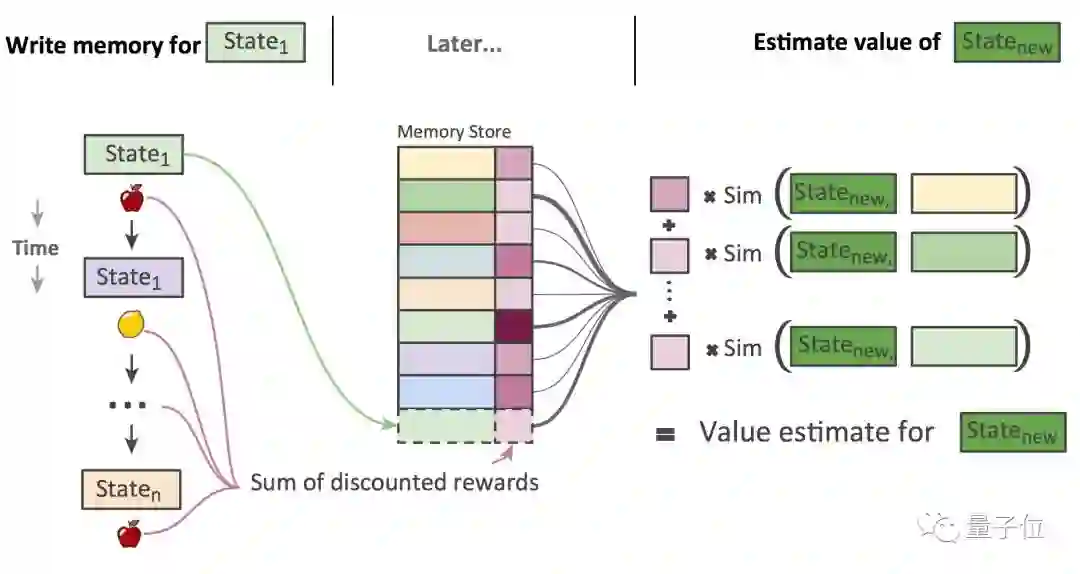
它与机器学习里“非参数”的方法异曲同工,也很像“基于示例 (Exemplar-Based) ”的心理学原理。
当遇到一个新事件,该做新决策的时候,就把当前事件的内部表征 (Internal Representation) ,跟储存的各种过去事件对比一下。匹配分数最高的中选。
和增量方法的区别在于:在这里,从过去的事件里学到的信息,都可以立刻派上用场,由此加速了学习过程。
但注意,快速的情节学习,是以缓慢的增量学习为基础的。
因为,在把当前事件和过去事件的表征作对比之前,AI先要学会这些表征:连接权重 (Connection Weights) 的学习,依然要靠增量来进行,就像传统的DRL算法那样。
慢慢学好表征之后,才能开始迅猛地奔跑。
DeepMind说,“快从慢中生”并不是什么巧合,在心理学和神经科学上的体现,不亚于AI领域 (这个部分,大家可以自行探索原文) 。
然后,再解决归纳偏置的问题:
首先限定好一个狭窄的范围,再让AI去探索。道理都懂,可怎么知道应该限定在哪里?
答案是,借鉴过去的经验。

打个比方,第一次用智能手机的人类,可能从前还用过其他的设备。那里的经验,就可以帮他很快学会智能手机的用法。如果没有那些经验,就只能广泛尝试,影响学习速度了。
这个思路,也是从心理学上来的,叫做“学着学习 (Learning to Learn)”。
心理学家Harry Harlow就曾经用猴子来做实验:给猴子两个不熟悉的物体,一个下面放食物,一个不放。换两个物体,再换两个……久之猴子就知道,一边有食物一边没有,不管物体是什么,不管左边有还是右边有。
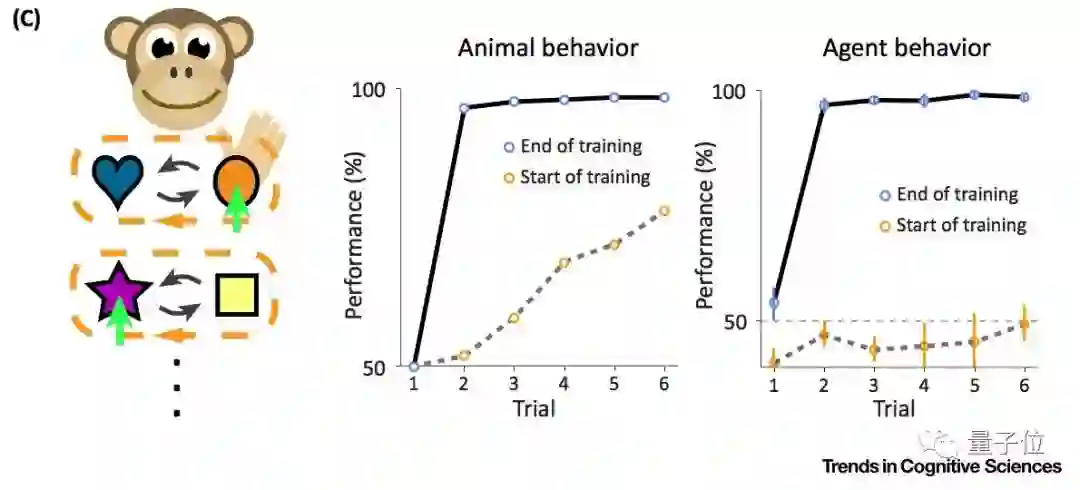
回到AI上来,用过去的经验来加速学习,在机器学习里叫做元学习 (Meta-Learning) 。
Wang与Duan带领的两项研究,几乎是同时发表。都把这样的原理用在了深度强化学习上,就是元强化学习 (Meta RL) 。
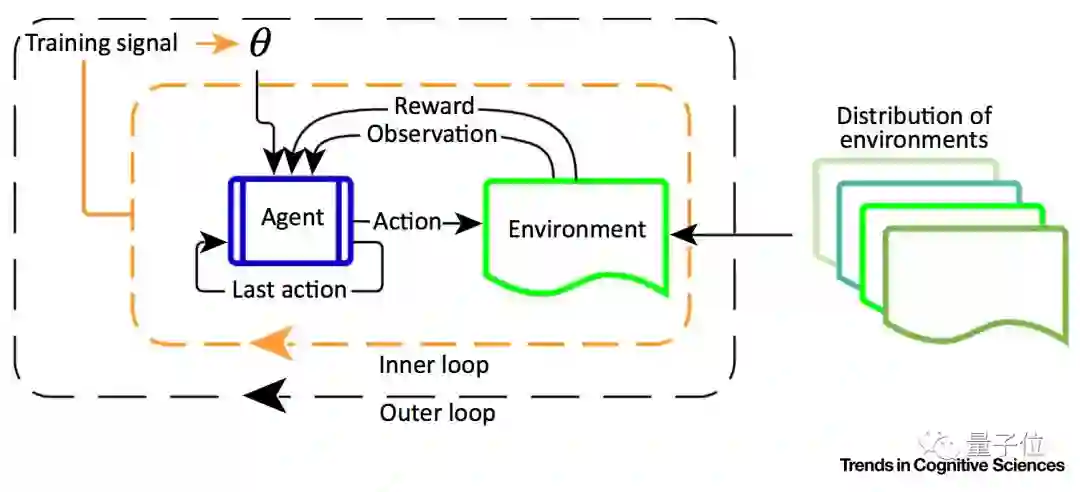
一个RNN是用许多互相关联的RL任务来训练的。
RNN的权重慢慢调整,然后可以吸取各种RL任务里面的共同点,改变网络的设定。原本,它没办法做到快速改变,来支持任何一个单一任务。
重点来了,从RNN的活动动态 (Activity Dynamics) 中,可以生出一个独立的RL算法,根据过往的任务,快速解决新任务。
一个RL算法,能生出另一个RL算法,这就是元强化学习。
像情节性RL一样,元RL也涉及了快速和慢速之间的联系:
RNN中的连接,是在不同RL任务的学习中缓慢更新的,建立起不同任务之间共同的部分,把它内置到网络里去。
让这个RNN,来实现新的RL算法,就可以快速搞定各种情况了。毕竟,已经有了慢速学习的归纳偏置做基础 (就像人类使用智能手机之前,已经用过其他设备那样)。
依然,慢是快的前提。
当然,情节性DRL可以和元RL合在一起用,相辅相成。
在情节性的元强化学习里,元学习是在RNN里实现的,不过上面叠加了一个情节记忆系统,作用是恢复RNN里的活动模式 (Patterns of Activity) 。
就像情节性RL一样,情节记忆会对各种过去的事件进行编目,可以查询。
但决策过程不一样,不是按照匹配分数来选择下一步的动作。而是和RNN存储好的活动模式,联系起来。
这些模式非常重要,通过RNN,它们可以总结出智能体学到的东西。
当智能体遇到了类似过去的情况,就会在从前的经验中,恢复一些隐藏的activations,让之前学过的信息立即派上用场,影响当前的策略。
这就叫“情节性元强化学习”,可以进一步加快强化学习的速度。

慢慢地,人们开始减轻对强化学习算法的担忧;并重新开始相信,这样的AI可以模拟人类的学习过程。
传送门
不知未来,不断加速的强化学习,还能在哪些领域超越人类呢?
综述原文传送门:
https://www.cell.com/action/showPdf?pii=S1364-6613%2819%2930061-0
— 完 —
小程序|get更多AI资讯与资源
加入社群
量子位AI社群开始招募啦,量子位社群分:AI讨论群、AI+行业群、AI技术群;
欢迎对AI感兴趣的同学,在量子位公众号(QbitAI)对话界面回复关键字“微信群”,获取入群方式。(技术群与AI+行业群需经过审核,审核较严,敬请谅解)

量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态
喜欢就点「在看」吧 !



