多模态注意力机制+多模态数据,完全实现端到端课堂活动检测| ICASSP 2020

编辑 | 丛 末

论文地址:https://arxiv.org/abs/1910.13799
研究背景
预备知识
1、问题定义
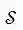 为一节课堂录音切分出的片段序列,记为
为一节课堂录音切分出的片段序列,记为
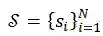 ,其中
,其中
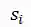 表示这节课中的第 i 句对话,N 表示这节课的总对话数。令
表示这节课中的第 i 句对话,N 表示这节课的总对话数。令
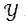 表示对应的标签序列,记为
表示对应的标签序列,记为
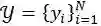 ,其中
,其中
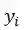 表示每个音频片段的说话人是学生还是老师。对于每个片段,我们提取它的音频特征
表示每个音频片段的说话人是学生还是老师。对于每个片段,我们提取它的音频特征
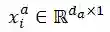 和文本特征
和文本特征
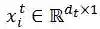 。
。
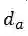 和
和
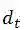 分别表示两种特征的维度。令
分别表示两种特征的维度。令
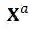 和
和
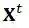 表示片段序列的音频特征和文本特征,其中
表示片段序列的音频特征和文本特征,其中
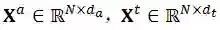 。结合上文提到的课堂活动检测任务的内容,我们现在可以将此任务定义为一个序列标注问题:
及其对应的音频特征和文本特征,我们的目标是找到最有可能的课堂活动类别序列
。结合上文提到的课堂活动检测任务的内容,我们现在可以将此任务定义为一个序列标注问题:
及其对应的音频特征和文本特征,我们的目标是找到最有可能的课堂活动类别序列
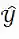 :
:
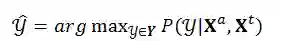
2、相关工作
技术细节
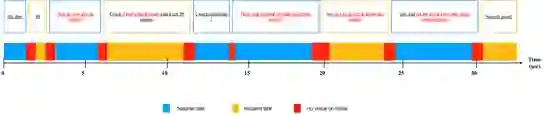
1、数据描述
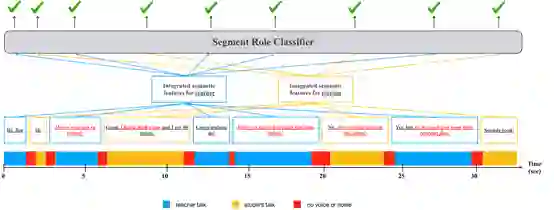
2、模型结构
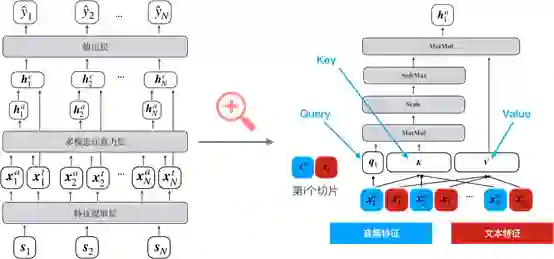
1)特征提取层
)。文本特征()和音频特征()来源于两个事先预训练得到的编码器。音频特征的编码器为使用GE2E[5]在大量不同说话人音频数据上训练得到,用于将一段音频信号编码为一个特征向量;文本特征来源于使用word2vec在大量课堂录音经过ASR转录得到的文本上训练的词向量,通过Mean-Pooling层,将一句文本编码为一个特征向量。因此,对于课堂录音中的每一句话i,我们通过不同的预训练编码器,从音频与文本两个方面提取了句子在不同模态下的特征信息。
2)多模态注意力机制
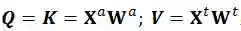 ,其
中Q、K和V是经典自注意力机制(self-attention)中的Query、Key和Value;
,其
中Q、K和V是经典自注意力机制(self-attention)中的Query、Key和Value;
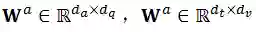 。注意力权重矩阵
。注意力权重矩阵
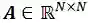 通过Q与K的点乘结果经过softmax归一化计算得到。最后,多模态混合表征 H,通过A与V的点乘计算得出,完整的公式如下:
通过Q与K的点乘结果经过softmax归一化计算得到。最后,多模态混合表征 H,通过A与V的点乘计算得出,完整的公式如下:
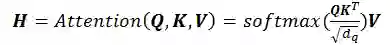
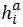 )与每句话的文本特征(
)与每句话的文本特征(
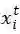 )拼接后(
)拼接后(
 )输入一个BiLSTM网络,用于引入整堂课的上下文信息。最后将BiLSTM的输出经过一个全连接层之后输出预测该句话的说话人是老师还是学生。
)输入一个BiLSTM网络,用于引入整堂课的上下文信息。最后将BiLSTM的输出经过一个全连接层之后输出预测该句话的说话人是老师还是学生。
3)注意力正则项

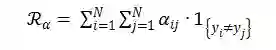
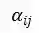 代表了本节课中切分出的第 i 句话与第 j 句话。
代表了本节课中切分出的第 i 句话与第 j 句话。
4)训练损失函数
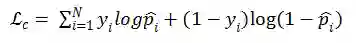
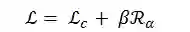
实验
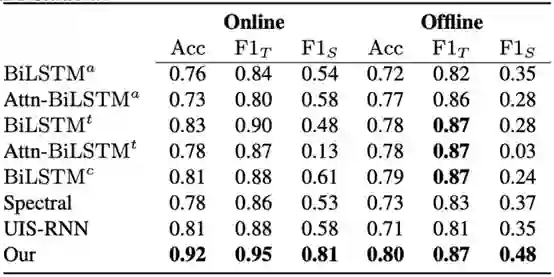
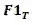 与
与
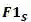 分别表示学生与老师的
分别表示学生与老师的
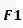 指标
指标
参考文献:


登录查看更多
相关内容

Arxiv
11+阅读 · 2018年3月23日




相关VIP内容
相关资讯
相关论文
Arxiv
11+阅读 · 2018年3月23日