上海交大提出多模态框架「EmotionMeter」,更精准地识别人类情绪


在碎片化阅读充斥眼球的时代,越来越少的人会去关注每篇论文背后的探索和思考。
在这个栏目里,你会快速 get 每篇精选论文的亮点和痛点,时刻紧跟 AI 前沿成果。
点击本文底部的「阅读原文」即刻加入社区,查看更多最新论文推荐。
本期推荐的论文笔记来自 PaperWeekly 社区用户 @Cratial。为了结合用户的内部大脑活动和外部潜意识行为,本文提出了使用 6 个 EEG 电极和眼动追踪眼镜来识别人类情绪的多模态框架 EmotionMeter。
如果你对本文工作感兴趣,点击底部阅读原文即可查看原论文。
关于作者:吴仕超,东北大学硕士生,研究方向为脑机接口、驾驶疲劳检测和机器学习。
■ 论文 | EmotionMeter: A Multimodal Framework for Recognizing Human Emotions
■ 链接 | https://www.paperweekly.site/papers/2000
■ 作者 | Wei-Long Zheng / Wei Liu / Yifei Lu / Bao-Liang Lu / Andrzej Cichocki
引出主题
不同模态方法描述了情绪的不同方面,并且包含互补信息。以融合技术将这些信息结合起来可以构建鲁棒性更强的情绪识别模型。
目前,大多数的研究都集中在听觉和视觉模态相结合的多模式情绪识别上,然而,来自中枢神经系统,例如 EEG 信号和外部行为,例如眼球运动的多模态结合已被证明是对情绪识别更加有效的方法。
为了结合用户的内部大脑活动和外部潜意识行为,本文提出了使用 6 个 EEG 电极和眼动追踪眼镜来识别人类情绪的多模态框架 EmotionMeter。本文提出的情绪识别系统的框架如图 1 所示。
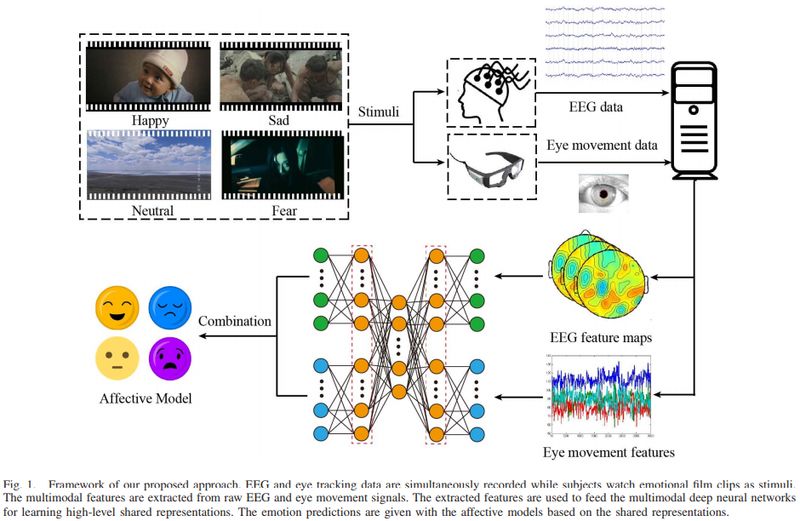
▲ 图1
本文工作:本文设计了一种包含 6 个对称颞叶电极的电极放置方式,可以很容易地嵌入到耳机或眼镜框架中。为验证本文算法的有效性,设计了四种情绪(高兴、悲伤、恐惧和中性)的识别实验。
本文揭示了 EEG 信号和眼动信息对于情绪识别的互补特性,并通过使用多模态深度神经网络改善了系统的识别性能。本文运用来自不同实验阶段的训练和测试数据集研究了本文方法的稳定性,并证明了在多次实验内和实验之间的稳定性。
实验设计
在我们的材料库中,共有 168 个包含四种情绪的电影片段,44 位被试(22 位女性,均为大学生)被要求在观看电影片段时评估他们的情绪状态(在 valence 和 arousal 两个维度下进行评分(-5~5))。
不同电影片段的平均得分分布情况如图 2 所示。从图中可以看出,不同情绪状态的电影片段在 valence 和 arousal 两个维度下的得分情况存在显著差异。
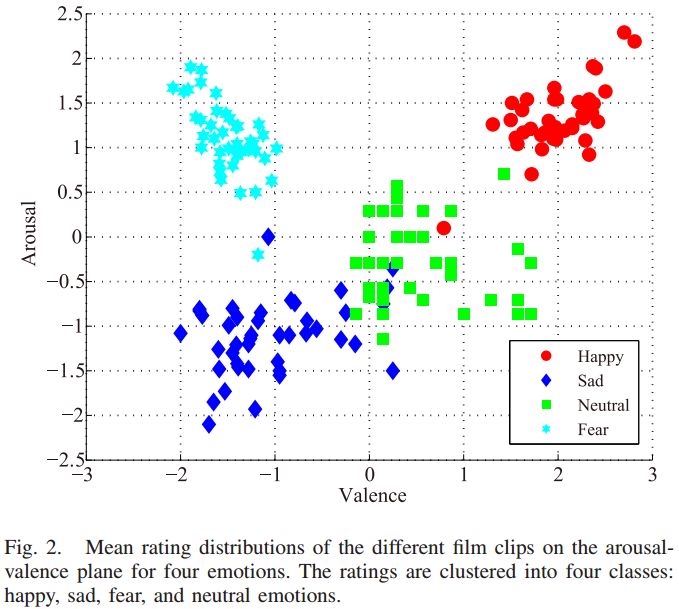
▲ 图2
最后,本文从材料库中精心挑选出 72 个认同度最高的电影片段用于情绪诱发实验。每个电影片段时长约为 2 分钟。为了避免重复,每个电影片段只被用于一次实验。
为了研究本文模型在一段时间内的稳定性,我们在不同的时间为每位被试设计了三个不同的实验(sessions)。每次实验(session)包含 24 个刺激片段(trials),其中每类情绪有 6 个刺激片段(trials),并且三次实验所用的刺激片段完全不同。图 3 给出了本文实验的详细设计流程。
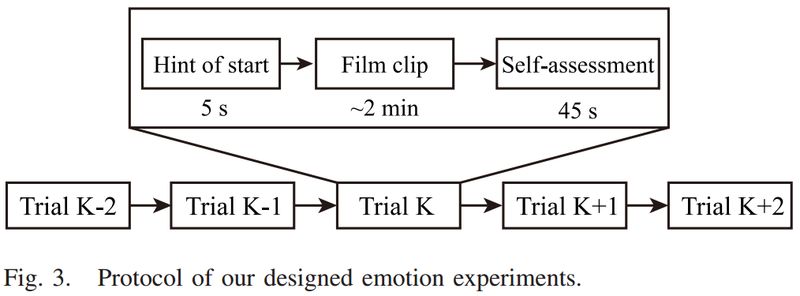
▲ 图3
数据记录实验共包括 15 名(8 名女性,年龄在 20~24 岁)被试,均为右利手。每位被试参与实验 3 次,共获得 45 次实验数据。本文使用的数据集(SEED-IV)将作为 SEED [1] 的子集可免费获得用于学术研究。
根据国际 10-20 电极系统,本文选择颞叶对称的六个电极(FT7, FT8, T7, T8, TP7, TP8)进行实验。电极布局如图 4 所示。
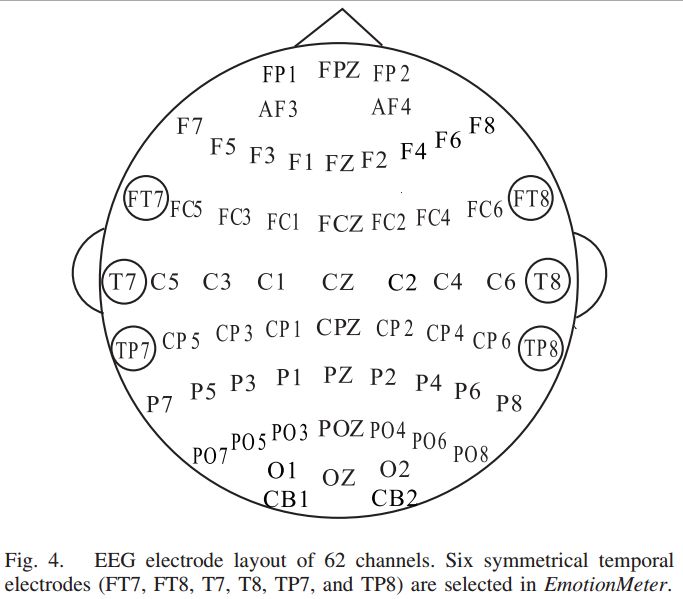
▲ 图4
为了进行对比,本文同时记录了 62 通道的 EEG 数据。原始 EEG 数据用 ESI NeuroScan 系统以 1000hz 的采用频率进行采集,并同时运用 SMI ETG eye-tracking glasses 记录眼动信息。图 5 显示了本文系统的硬件设置。
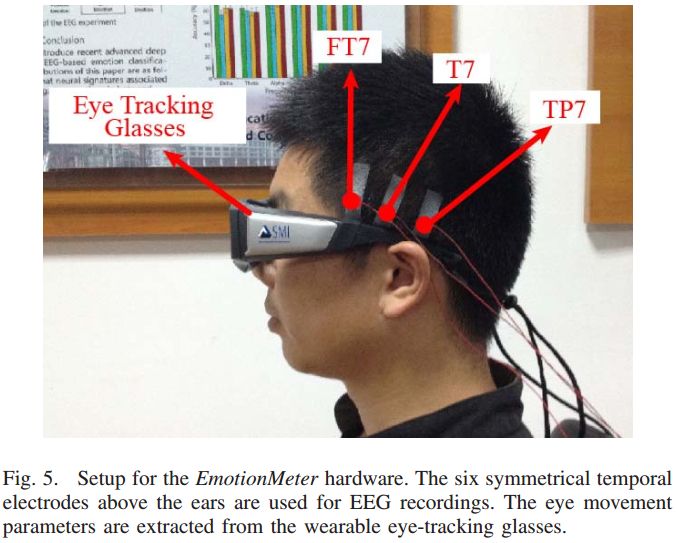
▲ 图5
研究方法
预处理
尽管瞳孔直径与情绪处理有关,但它很容易受到环境亮度的影响。基于不同被试对相同刺激的瞳孔反应变化具有相似模式的观察结果,我们应用基于主成分分析(PCA)的方法来估计瞳孔亮度反射。对于 EEG 信号,本文运用 1~75Hz 的带通滤波器去除伪迹,并对 EEG 和眼动数据进行重采样以降低计算复杂度。
特征提取
针对 EEG 信号,根据我们以前的研究,本文运用短时傅里叶变换(STFT)和 4s 长度的窗口以非重叠的方式提取功率谱密度(PSD)和微分熵(differential entropy, DE)两类特征。
针对所有通道的五个频带我们计算了 PSD 和 DE 特征:1) delta: 1-4Hz; 2) theta: 4-8Hz; 3) alpha: 8-14Hz; 4) beta: 14-31 Hz; and 5) gamma: 31-50Hz。
对于两个电极(T7和T8),四个电极(T7,T8,FT7和FT8)和六个电极(T7,T8,FT7,FT8,TP7和TP8)的 PSD 和 DE 特征的尺寸分别为 10,20 和 30。
我们应用线性动态系统(linear dynamic system)方法来滤除与 EEG 特征无关的噪声和伪迹。表 1 中显示了从眼球运动数据中提取的各类特征信息。
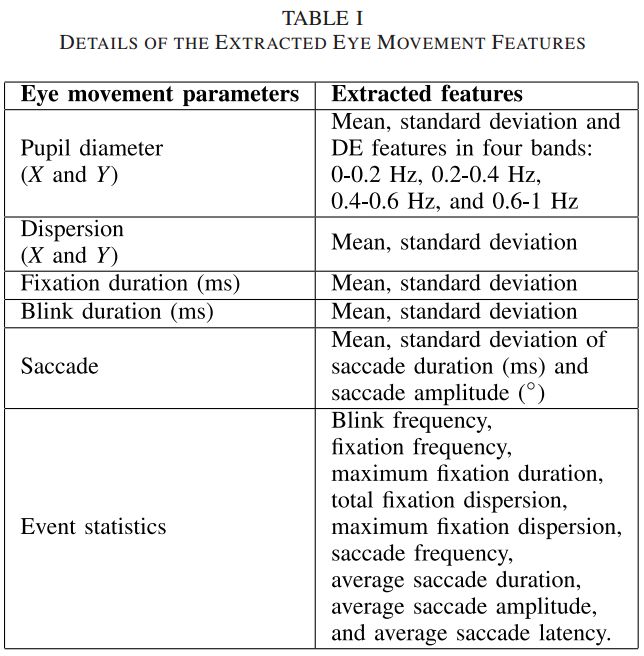
▲ 表1
眼动特征的维度为 33,图 6 显示了 5 类眼动参数。
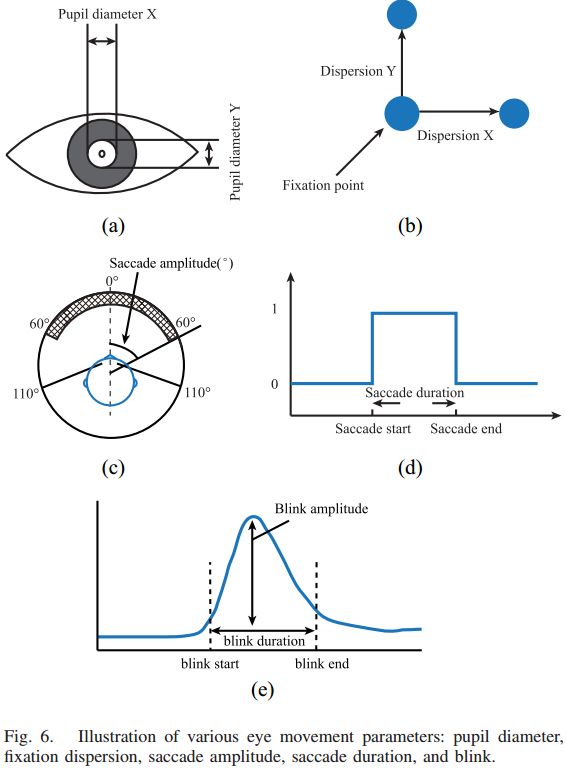
▲ 图6
分类方法
我们使用支持向量机(线性核)作为基准分类器,准确度和标准差被用于评估分类性能。本文采用特征级融合作为模态融合的基准,将脑电图和眼动特征向量直接连接成一个较大的特征向量作为分类器的输入。
对于单一模态和多模态的实验评估,我们将一次实验的数据分为训练数据和测试数据,其中前 16 个刺激片段(trials)是训练数据,最后 8 个刺激片段(trials)(每个情绪包含 2 个 trials)是测试数据。
为了分析 session 之间性能的一致性,将一个 session 的数据用作训练数据,并将另一个 session 的数据用作测试数据。
多模态深度学习
为了提高识别性能,我们采用双峰深度自动编码器(bimodal deep auto-encoder, BDAE)来提取脑电图和眼球运动的共有表示。图 7 描述了本文提出的深度神经网络的结构。
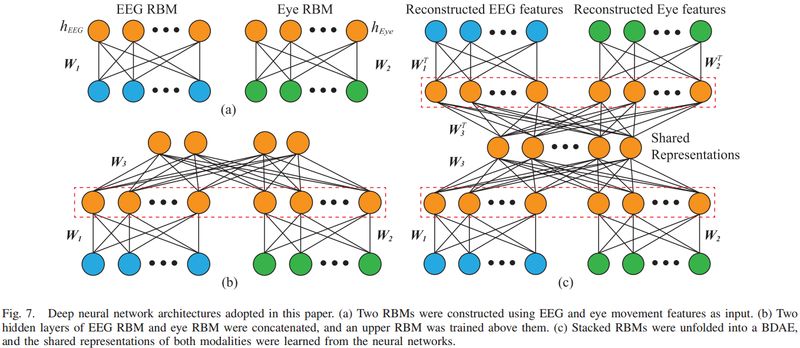
▲ 图7
实验结果与分析
基于EEG信号的情绪识别
首先,我们评估了 EmotionMeter 在不同脑电电极配置下的识别准确率,实验结果如表 2 所示。“total”表示五个频带特征的直接级联。
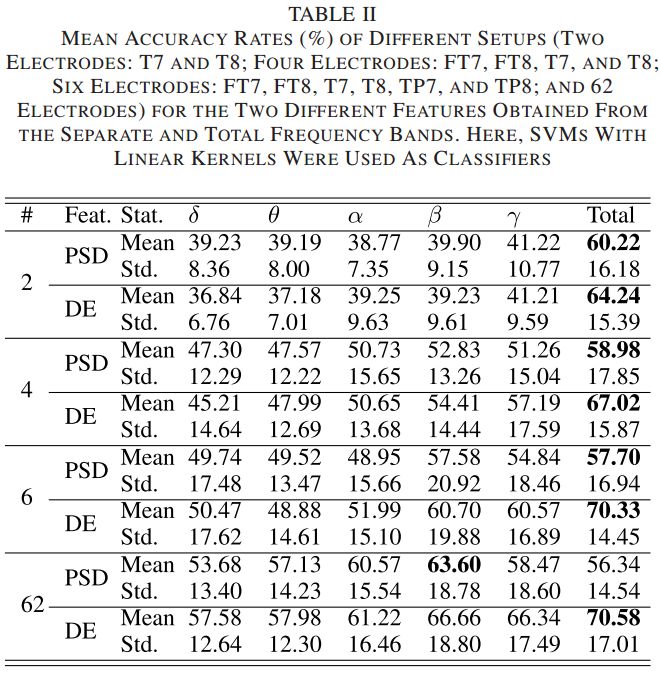
▲ 表2
一次实验中,DE 特征的可视化显示和对应的情绪标签如图 8 所示,图中呈现了高频特征中的动态神经模式。从图中可以看出,delta 的 DE 特征没有显示出明显的变化,而 gamma 和 beta 反应与情绪标签具有一致性。
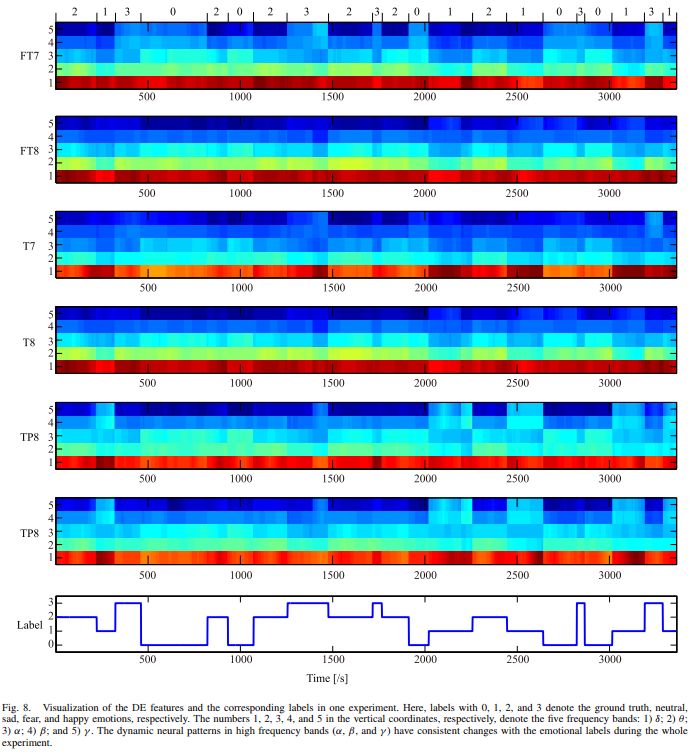
▲ 图8
互补特性分析
对于仅使用眼动数据的情绪识别,我们获得的平均准确度和标准偏差为 67.82%/ 18.04%,略低于仅使用 EEG 信号获得的识别结果(70.33%/ 14.45%)。
对于模态融合,本文比较两种方法:1)特征级融合和2)多模态深度学习。对于特征级融合,EEG 和眼动数据的特征向量直接连接成一个较大的特征向量作为 SVM 的输入。
表 III 显示了每种单一模式(眼球运动和脑电图)和两种模态融合方法的表现,图 9 显示了使用不同模态的准确度盒形图。
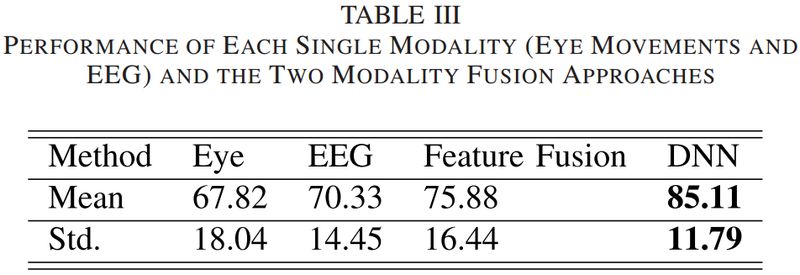
▲ 表3
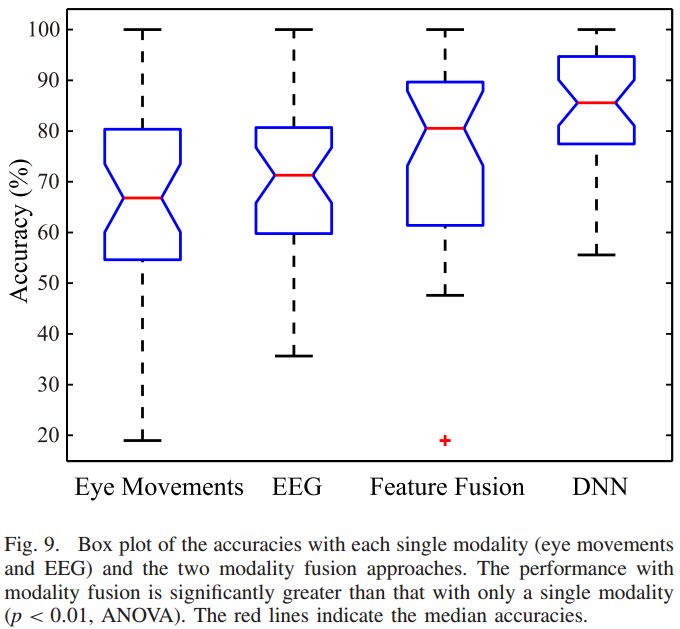
▲ 图9
为了进一步研究脑电图和眼动数据的互补特征,我们分析了每种模态的混淆矩阵,揭示了每种模态的优缺点。图 10 和图 11 分别给出了基于眼动数据和脑电图的混淆图和混淆矩阵。实验结果表明脑电和眼动数据对情绪识别具有不同的判别力。结合这两种模式的互补信息,模态融合可以显着提高分类精度(85.11%)。
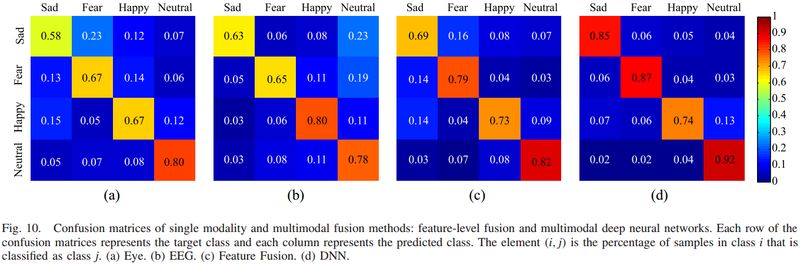
▲ 图10
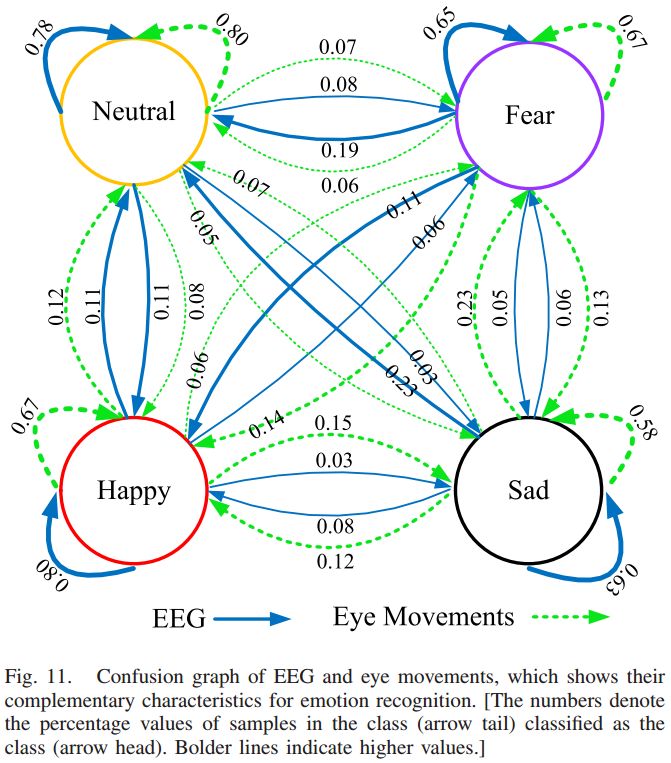
▲ 图11
各session之间的稳定性分析
我们选择来自相同被试的不同 session 的总频带 DE 特征和眼动数据特征,构成训练和测试数据集。表 IV 列出了两个,四个和六个电极配置下的平均识别准确率和标准差。这些结果证明了 EmotionMeter 框架的相对稳定性。
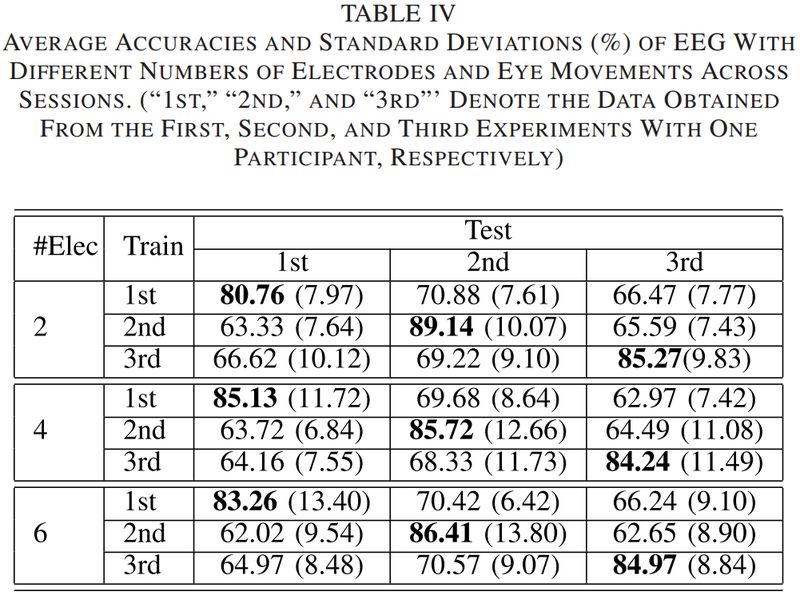
▲ 表4
结论与分析
情绪可以通过内部生理反应和外部行为表现出来。来自不同模态的信号从不同方面表征了情绪状态,并且来自不同模态的互补特征可以进行融合以构建比单模态方法鲁棒性更强的情绪识别系统。本文提出的情绪识别框架 EmotionMeter 就是一种融合 EEG 信号和眼动数据的多模态情绪识别系统。
本文由 AI 学术社区 PaperWeekly 精选推荐,社区目前已覆盖自然语言处理、计算机视觉、人工智能、机器学习、数据挖掘和信息检索等研究方向,点击「阅读原文」即刻加入社区!

点击标题查看更多论文解读:

▲ 戳我查看招募详情

关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 查看原论文


