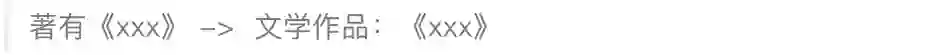OpenKG地址:http://openkg.cn/dataset/zgjdlsrw
项目地址:http://www.zjuwtx.work/project/kg
开放许可协议:CC BY-SA 4.0 (署名相似共享)
贡献者:浙江大学(王天笑)
1、引言
中国近代历史涌现了⼤量的杰出⼈物和事迹,史料文献丰富,构成了一个庞⼤的知识体系。本项⽬旨在收集挖掘中国近代历史⼈物信息,构建⼈物及其相关实体的知识图谱,为历史资料的检索和研究⼯作提供帮助。
中国近现代历史⼈物信息主要来源于百度百科和历史记两个⽹站。通过 python scrapy 爬⾍获取了 近1300位⼈物的结构化数据,半结构化数据和⽂本数据。其中,结构化数据主要包含⼈物的姓名、字号、出⽣地、⽣卒年⽉等信息;半结构化数据包括⼈物间的关系、历史成就等;⽂本数据主要是⼈物的生平介绍、评论等,有⽹站负责编辑维护,语⾔描述和记录的史料不⼀定完全准确。
项目尝试了基于语义⻆⾊标注和基于深度学习的实体关系抽取⽅法。
(1)基于LTP语义角色标注的实体关系抽取
LTP(Language Technology Platform)是由哈尔滨工业⼤学开源的中⽂⾃然语⾔处理⼯具,用户可以使⽤这些⼯具对于中⽂⽂本进⾏分词、词性标注、句法分析等等⼯作。Github:https://github.com/HIT-SCIR/ltp
上述例句被分解为了中⼼语(动词:加⼊),主语A0(王俊昌),宾语A1(中国共产党)和时间状 语ARGM-TMP(1943年2⽉)。通过构建基于语义⻆⾊标注的规则,可以从⽂本数据中提取符合规则的关系,准确度较⾼。但规则构建依赖⼈⼯。
OpenUE 是⼀个轻量级知识图谱抽取⼯具,⽤于基于预训练语言模型的知识图谱抽取任务。Github:https://github.com/zjunlp/OpenUE
使⽤OpenUE⼯具包和默认ske数据集训练并执⾏抽取。在简单句⼦中准确率较⾼,但是在所有⽂本 数据中的表现并不理想。原因可能是⽂本语句通常⽐较复杂,且句⼦间存在上下⽂关联的情况。例如主 语缺失等。
OpenNRE 是⼀个开源且可扩展的工具包,它提供了一个统⼀的框架来实现关系提取模型。项⽬尝 试使⽤基于OpenNRE的中⽂人物关系抽取,Github:
https://github.com/taorui-plus/OpenNRE
按照上述Github项⽬的描述训练模型并执⾏关系提取任务,结果同样在简单句型中表现良好,但在 多数复杂句型中出现了遗漏和错误。综上所述,出于准确度、史实正确性优先的考虑,项目最终使⽤了基于语义⻆⾊标注的实体关系抽取⽅法。
项目基于neo4j图数据库存储实体关系数据。实体对象共3类:⼈物,组织(学校),成就(作品)。其中人物包含属性:名称、附加名称、出⽣地、出⽣⽇期、死亡⽇期、⼯作职责、名族、国籍(在华外籍⼈物)。实体关系共3个⼤类:相关⼈物、毕业于、创作。相关⼈物可细分为7个⼦类,21个具体关系,如下图所示:
![]()
项目最终成果使⽤BS形式部署上云。后端打包为Docker镜像部署到阿⾥云ECI,前端部署到阿⾥云CDN。可以访问 http://www.zjuwtx.work/project/kg 查看。
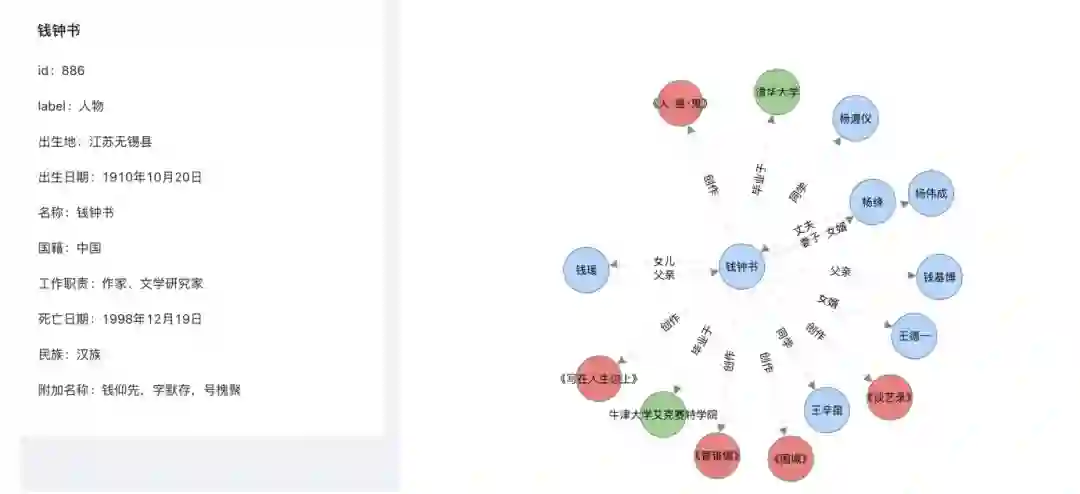
基本的⼈物检索功能,查看⼈物属性以及与其他实体间的关系。
![]()
基于规则的图谱推理,通过⾃定义Cypher脚本实现。包括关系推理和属性补全。
考虑到数据来源有限,同时数据内容以及数据处理过程不可避免地会存在⼀些问题,导致了图谱知识的缺失和错误。项目提供了知识众包功能,所有⽤户可以快速提交新增、修改数据的请求,在审核通过后会合并到现有的知识图谱中。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。
![]()
点击阅读原文,进入 OpenKG 网站。