【TNNLS2022】SGCPNet: 面向实时语义分割的空间细节引导上下文传播网络
【导读】构建实时视觉处理模型具有很大的研究价值和实用意义。合肥工业大学和中国科学院深圳先进技术研究院在CCF-B类期刊TNNLS上发表了《Real-Time Semantic Segmentation via Spatial-Detail Guided Context Propagation》,提出一种基于空间细节引导的上下文传播网络(SGCPNet),能在保证分割精度地同时,极大地提升模型的分割效率、降低算力消耗。
面向实时语义分割的空间细节引导上下文传播网络
Real-Time Semantic Segmentation via Spatial-Detail Guided Context Propagation
作者:郝世杰1, 周源1, 郭艳蓉1,洪日昌1,程俊2,汪萌1
1合肥工业大学
2 中国科学院深圳先进技术研究院
论文地址:
https://ieeexplore.ieee.org/abstract/document/9729997
代码:
https://github.com/zhouyuan888888/SGCPNet

摘要:
视觉计算在很多实际应用中都发挥着至关重要的作用。然而,一些视觉计算任务(如语义分割)通常需要消耗较多的算力,这对资源受限但需要快速响应的系统形成了巨大挑战。因此,构建实时视觉处理模型具有很大的研究价值和实用意义。为此,本研究提出了一种基于空间细节引导的上下文传播网络(SGCPNet),其能在保证分割精度地同时,极大地提升模型的分割效率、降低算力消耗。该网络建立在基于空间细节引导的上下文传播策略上。该策略使用浅层的空间细节来指导低分辨率上下文信息的传播,从而有效地重构所丢失的空间信息,避免了在网络内始终维持高分辨率特征,从而降低计算开销。同时,空间细节的高效重构使得本模型仍然具有准确的分割性能。在若干公开数据集上的实验结果显示,SGCPNet模型能够在精度和速度之间取得较好的平衡。例如,该模型仅包含0.61M的参数。在Cityscapes 数据集上,该模型能实现69.5% mIoU的分割精度、分割速度能达到178.5 FPS(GTX 1080Ti)。
I.引言
视觉计算在实际应用中发挥着越来越重要的作用,如动作识别 [1]、[2]、物体检测[3]-[5]和物体跟踪[6]、[7]等场景。这些应用共同特点是:视觉传感器会产生大量数据,且往往需要有快速、甚至是实时的处理速度。在这种情况下,边缘计算已成为一种很好的补充,它将计算从云端驱动到网络边缘,使数据处理贴近数据源,从而提升计算效率[8]。
深度学习的成功给边缘计算同时带来了机遇和挑战[9]、[10]。一方面,深度学习技术能够显著提升视觉系统的性能。然而,另一方面,这些模型通常具有较大的计算和存储开销,这对系统的执行速度和功耗提出了挑战[11],[12]。该挑战广泛存在于许多视觉计算任务中,尤其是旨在为每个像素分配语义标签的语义分割任务。但语义分割可为视觉系统提供精细的、像素级语义信息(如图1),因而它在诸多应用中具有重要作用,如自动驾驶[13]和医疗辅助系统[14]。

图1.语义分割任务的示例。
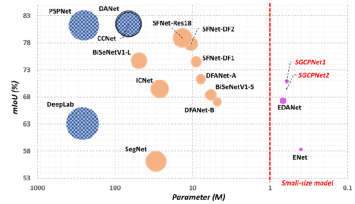
图2.本方法和其他方法的对比(模型大小、精度和运行速度)。注:标记越小表示模型的执行速度越快。
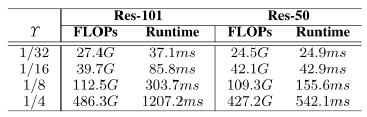
表1.在神经网络中,特征图分辨率对于浮点运算量(FLOPs)和运行时间(Runtime)的影响。ϒ表示所维护的特征图分辨率和输入图片分辨率的比率。
近年来,基于深度学习的语义分割模型[15]-[17]在提升分割精度方面取得了良好进展。但模型往往存在尺寸大和复杂度高等问题,很难将它们直接应用到资源受限的场景中。模型压缩是解决这些问题的一种可行方法[9],例如,网络裁剪和量化[18]-[20]、知识蒸馏[21]、复合式模型压缩[22]。但如果能直接设计一个轻量级的语义分割模型,使该模型同时满足分割速度快、分割精度高、硬件消耗低等要求,则更具吸引力。
在此,先简要分析一下当前部分语义分割模型计算开销大的原因。为了保证分割精度,当前主流方法(如[15]、[16]、[23]-[25])主要采用在网络内部维持高分辨率特征的策略。如图3(a)所示,该策略可以有效地保持空间细节信息,但较大的特征图尺寸降低了卷积核的感受野,往往需要采用空洞卷积[26]来尽可能地聚合更多的上下文信息。因此,从计算开销的视角来看,这些方法都引入了较高的计算成本来维持特征的分辨率。在此,以ResNet [27] (移除了ResNet的最后一个全连接层)为例,来说明特征分辨率对浮点运算 (FLOPs)和运行时间(Runtime)的影响。从表1结果可以看到,特征图分辨率的增加会导致FLOPs显着增多、速度大幅降低。
基于上述分析,维护高分辨率特征图应是提升分割效率的一个瓶颈。可以通过特征图的快速下采样来降低计算复杂度。其基本原理在于语义上下文属于区域级信息,即邻域内的像素通常共享一个共同的语义标签,没有必要总是在高分辨率特征图上聚合上下文。但由于特征图中的空间信息严重丢失,直接使用低分辨率特征会降低分割的精确性。为了解决这一矛盾,本研究试图高效地重构低分辨率特征图的空间信息,在保证分割精度的同时,降低模型计算开销,从而提升语义分割的效率。
基于这一思路,本工作提出了空间细节引导的上下文传播策略,如图3(b) 所示。它旨在利用浅层的空间细节来指导全局上下文特征向邻域传播,从而重构出全局上下文中所丢失的空间信息。上下文的传播需满足两个基本要求:首先,在上下文传播过程中,上下文信息
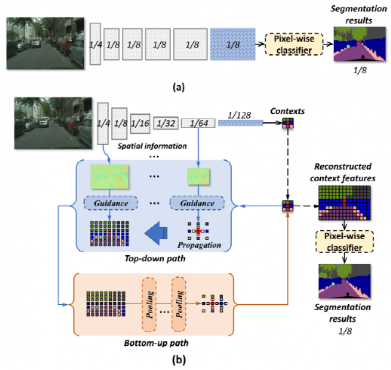
图3. 基于空间细节引导的上下文传播策略示意图(即,(b))。在图中,(a)表示传统语义分割方法,即同时保持神经网络内的空间细节并聚合上图像的下文信息。
应与其邻域内的空间细节保持一致性,保证上下文传播的有效性;其次,在传播后,原始的全局上下文信息能从传播后的特征中准确地恢复,以保证传播的准确性。
如图5所示,本方法构建了轻量级的双向网络来实现“自上而下”和“自下而上”的传播路径。具体来说,在自上而下路径中,全局上下文在空间细节的引导下逐渐传播到邻域。而在自下而上路径中,通过使用池化操作,上下文信息被重新提取,并且重新提取的上下文信息应该与传播之前的全局上下文尽可能的相同。基于上述构造,本工作组建了轻量级的语义分割模型--基于空间细节引导的上下文传播网络(SGCPNet)。该网络具有较低的存储和计算成本,以及较快的计算速度。例如,它只包含0.61 M参数、分割一张1024 × 2048图像仅需4.5 GFLOPs;在一张GTX 1080 Ti显卡上,分割1024 × 2048图片的速度可以达到103.7 FPS,分割360 × 480图片的速度可达到731.3 FPS。与此同时,SGCPNet的分割精度仍保持在较高水平。例如,在Cityscapes 测试集上,SGCPNet可以实现70.9% mIoU的分割精度;在CamVid的测试集上,分割精度可以达到69% mIoU。图2将 SGCPNet 与相关方法在模型大小(x 轴)、分割精度(y 轴)、分割速度(标记的大小)方面进行了可视化。可以看到,SGCPNet 在这些性能指标上能够取得良好的平衡,显示了其在资源受限的语义分割任务中的优势。
本研究的贡献在于提出了一种新的基于空间细节引导的上下文传播策略,基于该策略的SGCPNet网络可以高效地重构全局上下文中所丢失的空间信息,从而避免在网络内维护高分辨率特征所带来的计算开销,进而达到兼顾分割精度和运算效率的目标。
II.相关工作
A.专注于提高分割精度的语义分割方法
由于获得足够的上下文和空间细节信息对于语义分割的准确性十分重要,Yu等人[26]提出了空洞卷积,缓解了传统卷积操作的局限性。空洞卷积通过在卷积核中插入“空洞”来扩大卷积操作的感受野、帮助神经网络聚合更多的上下文信息。因此,它能避免在网络内使用一些其他用于扩大感受野的下采样操作(例如,池化操作),从而在聚合足够上下文信息的同时尽可能地维护网络内的空间细节信息。基于[26],Chen等人[16] 提出了基于空洞的空间金字塔池化模块(ASPP),该模块将空洞卷积与空间金字塔结构巧妙结合,实现了从多个不同感受野中聚合上下文信息的功能。Zhao等人[15]通过额外考虑视觉场景的全局上下文信息进一步将 ASPP 扩展到金字塔池化模块 (PPM),从而帮助模型从更全局的角度理解视觉场景。为了使语义分割模型感知更多的上下文信息,Huang等人[30]提出了CCNet,它为每一个特征向量聚合了位于其“十”字路径内的上下文信息。而Fu 等人[17]提出同时聚合全局上下文信息和特征通道间的关联。Zhang等人[24]提出使用字典学习来提高分割精度。他们通过构建了一个可学习的字典来存储整个数据集的语义上下文信息。相反,Ma等人[31]建议设计一个语义一致性模块(SCM),以更好地维护网络内的空间细节信息。He等人[25]提出使用基于全局引导的局部亲和力来引导金字塔上下文信息的聚合,使深度学习模型对物体的大小和形状的多样性更加鲁棒。而Zhang等人[32]提出通过明确考虑物体轮廓和显着对象的引导来增强语义分割的准确性。
为了同时获得足够的上下文和空间细节信息,上述语义分割方法采用在网络内维持较高分辨率特征图的策略,并采用空洞卷积为网络聚合足够的上下文信息。尽管这些方法可以实现准确的分割结果,但它们往往需要耗费昂贵的算力,且分割速度与实时处理的要求相差甚远。例如,DeepLab分割一张512 × 1024的图像需要消耗457.8 GFLOPs,分割速度只有0.25 FPS;PSPNet分割一张713 × 713图像的速度只能达到0.78 FPS,且需消耗412.2 GFLOPs。因此,上述这些模型往往不适用于资源受限、但需要实现快速分割的应用场景。
B.专注于提高分割效率的方法
除了分割的准确性之外,分割效率对于诸多实际应用也同样至关重要。近期,人们在构建轻量级语义分割模型的研究上付出了巨大努力。Badrinarayanan等人[33] 提出了一种基于“编码器-解码器”结构的模型SegNet。在编码器部分,通过使用池化操作,特征被逐渐下采样到较低的分辨率,并且相应的池化索引被依次保存下来。在解码器部分,通过所保存的池化索引对特征进行上采样,这避免了需要学习如何对低分辨率特征图进行上采样,大大提高了分割速度。Zhao等人[34]提出了采用多分支的语义分割模型ICNet,其中不同的分支用来处理不同分辨率的输入,且不同的分支也具有不同的网络深度。具体地,较深的分支用于从低分辨率输入中提取语义上下文信息,而较浅的分支用来从高分辨率的输入图片中捕获空间细节。这样在尽可能地节省计算成本的同时,也可以使语义分割模型获得足够的上下文信息和空间细节特征。此外,Yu等人[35]和Poudel等人[36]提出分别构建空间路径和上下文路径,从而独立地学习空间细节和上下文信息。与方法[34]相同,在[35]和[36]中,空间路径具有较浅的网络深度,而上下文路径具有较深的网络深度。在工作[37]中,Yu等人通过进一步引入引导聚合层来改进方法[35],从而可以更好地实现空间细节和上下文信息之间的融合。李等人[38]提出了特征重用策略,以充分利用网络前几层所包含的特征信息。在工作[39]中,Li等人提出了网络SFNet,该网络可以在有效对齐低分辨率和高分辨率特征图的同时保持较低的计算开销。Lo[40]等人为了同时提高分割的准确性和效率,设计了一个具有非对称卷积结构和密集连接的网络。Paszke [41]等人通过设计一个小型解码器和使用早期下采样策略构建了网络ENet。该网络十分轻量化,仅包含约0.4 M的网络参数。
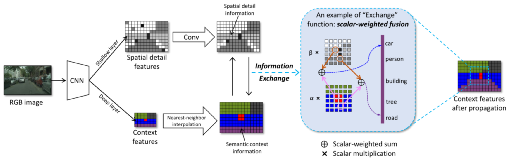
图4.基于空间细节引导的上下文传播策略示意图
当前提升分割效率的方法主要专注于研究如何单独维护空间细节和聚合上下文信息(例如[34]-[37])。但这种解耦式的方法仍包含不必要的计算开销,例如上下文信息和空间细节信息可以分别从语义分割模型的深层和浅层获取,而不必要构建单独的学习机制。此外,本文认为特征融合模块是整个模型的关键之处,需要精心设计,尤其是在计算资源受限的情况下。基于此,本研究提出同时从网络中学习空间细节和上下文信息,并显式地考虑上下文和空间细节信息之间的相关性,即用空间细节来指导上下文信息的传播。本研究以学习的方式实现空间细节信息对于上下文特征的指导,而非使用保存的池化索引,这与 [33]有明显的不同。
III.所提出的方法
A.基于空间细节引导的上下文传播的策略
提出基于空间细节引导的上下文传播策略的动机简单明了,即将全局上下文传播到更高分辨率的网格并与低级空间细节保持一致性。该策略的基本操作如图4所示。具体地,从相对较深网络层获得的上下文特征C首先通过最近邻插值操作Upsample(·)上采样到更高分辨率,此过程可以被看作是一种朴素的上下文传播(即,没有引入任何空间细节的引导)。其次,来自相对较浅层的空间细节S被用来细化上采样后的上下文特征,其中交互函数Exchange(·,·) 用来促进C和S之间不断交互,从而重构所丢失的空间信息。该过程可以描述如下:

其中C'表示传播后的上下文特征。在公式(1)中,卷积操作Conv(·)被用来进一步细化S的空间细节信息,因为网络浅层特征通常会包含一定的噪声。为了提升模型效率,本文采用了可分离卷积[42]去实现卷积操作。交换函数Exchange(·,·)可以被设计成不同的形式,例如特征的直接融合、或构建像素级的注意力机制。为促进模型在有效性和效率之间取得良好平衡,在此将交换函数Exchange(·,·)设计为简单的线性加权融合:
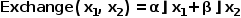
其中α和β是输入x1(例如,上下文特征)和x2(例如,空间细节特征)的可学习标量权重。学习函数通过施加较大的权重β来细化上下文中不正确的响应。图4提供了一个示例来简单地解释此过程。假设,初步上采样的特征图C是局部不准确的,而施加了函数Exchange(·,·)后,这些不准确的地方可以在空间细节信息的引导下进行更新,如一些被误判为“人”的地方被纠正为类别“汽车”、被误判为“汽车”的响应被修正为类别“道路”。这样,上采样后的上下文与原始图像的空间细节具有更好的一致性,从而尽可能地恢复所丢失的空间信息,如图6所示。
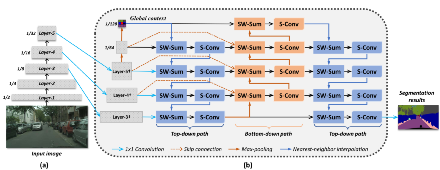
图5.基于空间细节引导的上下文传播网络(SGCPNet)。其中,“SW-Sum”表示标量加权求和操作,“S-Conv”表示可分离卷积。此外,(a)表示骨干网络,(b)表示SGCP模块。
正如前文所述,上下文传播需满足两个基本要求:(1)在上下文传播过程中,上下文应与邻域内的空间细节信息保持一致性;(2)在传播后,原始上下文信息应尽可能地从传播后的特征图中恢复。为此,本方法构建了双向路径来实现空间细节引导的上下文传播策略,分别称之为自上而下路径和自下而上路径。如图3(b)所示,沿着自上而下路径,全局上下文被回传到网络浅层,并不断与空间细节信息进行交互,从而对所丢失的空间细节信息进行重构。而自下而上路径旨在重新提取传播后特征图中的全局上下文信息,该过程可以通过不断地使用最大池化或平均池化操作来实现。重提取的上下文信息应与传播前的上下文尽可能地相同。此外,采用了最大池化操作来实现上下文的重提取,其有利于选择更具判别性的特征响应。表4中提供的消融实验也表明使用最大池可以产生更准确的分割结果。交替使用自上而下和自下而上路径,可使使特征同时包含足够的上下文信息和空间细节。通过这种方式,可以缓解因需要在网络内持续维护高分辨率特征的需求,从而在保持分割精度的同时大大提高分割效率。
B.SGCPNet的网络结构
基于上述策略,本研究构建了基于空间细节引导的上下文传播网络(SGCPNet)。如图 (5)所示,SGCPNet是一种“编码器-解码器”框架的变体。其中,轻量级网络MobileNet [43]被用作编码器的骨干网络。为了保证分割的高效率性,本方法没有在网络中持续维护空间细节信息。反之,特征图被逐渐下采样,直到输入图片分辨率的1/32,这可以大幅减少计算消耗,使模型具有更快的分割速度。然而,空间细节信息的丢失会导致分割精度的降低。为克服此问题,本研究设计了一个轻量级的基于空间细节引导的上下文传播(SGCP)模块作为解码器,如图5(b)所示。其能有效地恢复上下文特征中所丢失的空间细节信息,从而保证较高的分割精度。为了能在较低的计算开销下实现有效的上下文传播,SGCP模块被设计为双向结构。
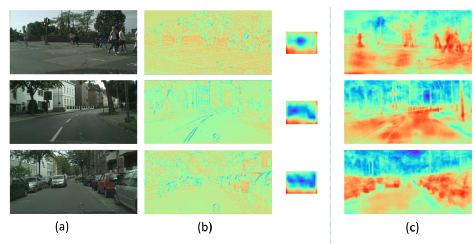
图6. SGCP模块处理后的上下文特征可视化。对于(b)和(c),红色表示较高的响应,而蓝色表示较低的特征响应。上图中,(a)表示输入图像,(b)表示原始的空间细节特征和全局上下文特征。(c)表示SGCP模块处理后的上下文图。
C.SGCP模块
如图5(b)所示,在SGCP模块中,三个1×1卷积操作首先应用于最后三个主干层所产生的特征,将特征编码为更加丰富的更高维表示。三个新特征层分别被称为Layer-3†、Layer-4†和Layer-5†。为了聚合更多的全局上下文信息,两个最大池操作被依次应用于Layer-5†。这两个最大池化操作的核都被设置为3×3,步幅被设置为2,从而最终的上下文特征被压缩为输入分辨率的1/128。显然,它包含更多的全局语义上下文信息,而其空间细节信息丢失严重。
为了在所聚合的全局上下文中重构出所丢失的空间细节信息,采用了基于空间细节引导的上下文传播策略。为实现上下文的有效传播,本方法采用了双向网络,其中分别引入了自上而下路径和自下而上路径。这两条路径具有相似的网络结构(例如,它们都由卷积操作和标量加权融合组成)。然而,为了使这两条路径具有不同的功能,自上而下路径额外采用了最近邻插值操作,而自下而上路径采用了最大池操作。因可分离卷积[42]计算开销适中、且能有效性地提取深度特征,在此遵从了方法[37]、[38],并采用分离卷积来构建SGCP模块的卷积层。可分离卷积由一个点卷积和一个深度卷积组成,其中深度卷积单独提取分布在每个通道中所包含的特征,而点卷积用来对深度卷积所提取的特征进行线性组合。为了聚合来自相邻层的信息,在自上而下和自下而上路径中,采用了标量加权融合操作:
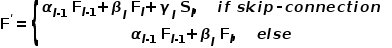
其中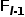
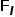
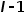
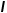
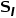
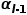
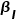
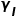
如图5(b)所示,在SGCP模块中,本方法首先构建了一个自上而下路径,使全局上下文和空间细节信息之间持续交互,从而在空间细节的引导下全局上下文被逐渐传播到邻域,直到得到初步重构的特征图(其分辨率为输入图片的1/8)。其次,构建了一个自下而上路径,以从传播后的上下文图中对全局上下文特征进行重提取。重提取的全局上下文特征与原始的全局上下文信息之间应尽可能相同。因此,如图5(b)所示,跳跃连接将原始的上下文和空间细节信息插入到自下而上路径的相应层中。最后,另一条自上而下路径通过充分地利用先前路径中所包含的信息来生成最终的上下文特征,并且1×1卷积分类器被用来得出最终的分割结果。
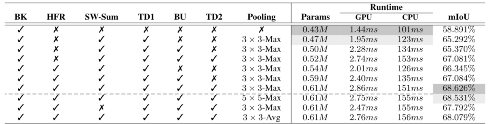
如表5所示,SGCP是轻量级模块,其只包含约0.18 M的参数,但其仍能产生令人满意的性能。图6视化了被SGCP模块处理后的全局上下文特征。具体地,从图6(b)可以看出,一方面,空间信息包含很多细节信息(例如,边界和纹理),但它无法较好地感知场景语义信息。另一方面,全局上下文信息能大范围地感知不同的语义区域,但其空间细节信息丢失严重。而本方法所提出的SGCP模块能够有效地重构上下文特征中所丢失的空间细节信息。因此,如图6(c)所示,传播后的上下文图可以同时清晰地反映场景语义信息和空间细节特征。章节IV-D中的消融实验也同样定量地验证了SGCP模块的有效性。例如,主干网络在Cityscapes验证集上仅能达到58.891% mIoU的分割精度。而添加上SGCP模块,分割精度可以被提高到68.626% mIoU,且这只会带来大约0.18 M的参数。
IV.实验
A.实现细节
本研究提出的语义分割模型是基于Pytorch实现,使用GPU型号为GTX 1080Ti。遵循之前的工作[16]、[25],本方法采用了“poly”学习率,即

B.模型效率层面的比较
本节将SGCPNet与相关模型在效率方面进行了详细的对比,其中采用了三个主流的评估指标,即模型参数(Params)、浮点运算量(FLOPs)、每秒分割帧数(FPS)。为了更好地比较,相关模型被划分为三类:1)大尺寸模型;2)中尺寸模型;3)小尺寸模型。其中,大尺寸模型表示模型的Params和FLOPs要同时大于50M和300G。中尺寸模型指模型的Params在1M到50M之间,或FLOPs在10G到300G之间。在小型模型中,Params和FLOPs应同时小于1M和10 G。根据该分类标准, SGCPNet显然属于小尺寸模型,因其只包含约0.61M的参数,并且它的FLOPs明显小于10G(如,即使分割一张1024×2048图片,其计算成本也仅为4.5 GFLOPs)。
表2将SGCPNet和相关模型在不同分辨率下进行了对比。为了比较的公平性,表中在所有的分辨率上均测试了SGCPNet的效率。从表2可以看出,大尺寸模型专注于提高分割精度,他们往往需要消耗昂贵的计算开销。例如,DeepLab [16]共包含262.1 M参数,分割一张512 × 1024图片,其需消耗457.8 GFLOPs,且分割速度仅为0.25 FPS;PSPNet[15]包含250.8M参数,处理一张713 × 713 图片需消耗421.2 GFLOPs,并且运行速度仅为0.78 FPS。尽管CCNet [30]和DANet [17]具有较少的参数,但他们的FLOPs仍保持在较高水平,并且他们的速度远远不能满足实时处理的需求。
表2. 本方法与其他相关方法在模型参数(Params)、分割速度(FPS)和计算开销(FLOPs)方面的对比。
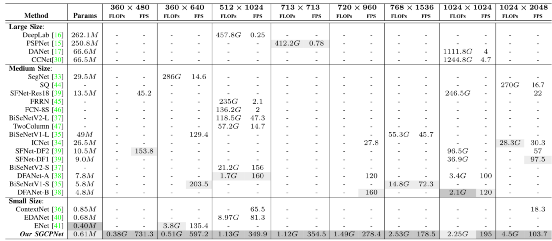
中型模型的存储和计算开销远小于大型模型,他们在效率方面往往能取得较为良好的表现,如SFNet-DF1[39]和DFANet [38]可以实现大约100 FPS的分割速度,并且模型参数也小于10 M。小尺寸模型的存储和计算成本成通常很小,因此他们比较适用于资源受限的场景。表2表明SGCPNet在所对比的模型中具有第二小的模型尺寸(Params = 0.61 M),且它的模型参数比中型和大型模型小几十、甚至几百倍。此外,该模型在几乎所有的分辨率上都具有最小的FLOPs和更快的分割速度。
C.模型精度和效率的综合比较
对于实时语义分割任务,准确性和效率之间的平衡是模型评估的重要指标。这一节将SGCPNet和相关模型在准确性和效率之间的平衡方面进行了对比。
(a)Cityscapes数据集
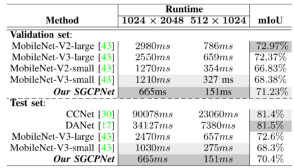
Cityscapes[28]数据集包含25000张道路场景图片,其中5000张图片被精细标注,而20000张图片被粗标注。本节实验只采用了精细标注的图片,其中2975/500/1525张图片被分别用于训练/验证/测试。该数据集包含30个语义类别。遵循之前的工作[15]、[48],本实验采用了19个类别去评估模型的性能。为了更好地展示模型效率,在此数据集上,本实验采用了两种不同的输入分辨率,1024 × 2048和768 × 1536。根据不同的输入分辨率,模型被分别重命名为SGCPNet1和SGCPNet2,其中SGCPNet1表示模型在1024 × 2048分辨率上进行评估(与[34]、[39]、[44] 相同),SGCPNet2表示模型在较小的768 × 1536分辨率上进行训练和测试。本方法在Cityscapes数据集上的分割结果和分割示例,请分别参阅表3和图7。
性能分析:与小尺寸模型相比,SGCPNet1和SGCPNet2在效率和准确性之间的平衡要好于ContextNet [36]和EDANet [40]。虽然,SGCPNet1和SGCPNet2的参数略多于ENet [41](约 0.21 M),但SGCPNet1和SGCPNet2的分割精度更高。并且,本方法消耗的FLOPs相对较少,例如,即使在分割分辨率为768 × 1536的图片时,本模型所消耗的FLOPs仍比ENet在分割360 × 640图片时少约1.3 GFLOPs。本模型在准确性和效率之间的平衡同样也比表中的中型模型要更加出色。例如,本模型同时在效率和准确性这两个方面上比某些中型模型要更好(如SegNet [33]、SQ [44] 、FCN-8S [46])。SCGPNet1和SGCPNet2的分割精度与FRRN[45]、TwoColumn [47]、ICNet [34]、BiSeNetV2-S [37]、BiSeNetV1-S [35]、DFANet-A、DFANet-B [38]等模型处于同一水平,但SCGPNet1和SGCPNet2比几乎所有的中型模型都具有更少的 FLOPs和更高的FPS。而对于较高精度的中型模型,如SFNet [39]、BiseNetV1-L [35]、BiseNetV2- L [37],他们所要消耗的FLOPs是本模型的数十倍、甚至数百倍。这些模型之间的比较表明本模型能在分割精度和效率之间取得更好的平衡,故更适用于资源受限场景下的语义分割任务。在本实验中,SGCPNet还与一些大型模型进行了对比,以进一步证明提高模型效率的重要性。如表3所示,大尺寸模型在分割精度方面非常有优势,它们的分割精度比SGCPNet1和SGCPNet2高出10%左右。但这些方法通常计算开销大,响应速度较慢,不适用于实时计算系统。
表3. SGCPNet和相关方法在Cityscapes测试集上的分割性能。
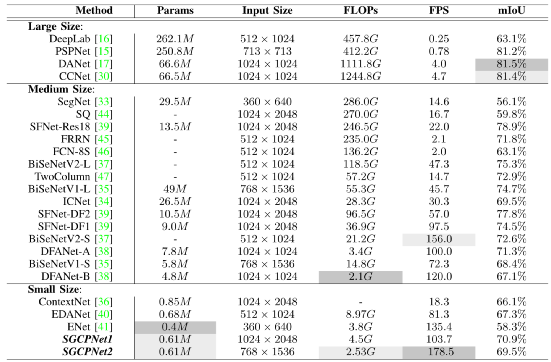
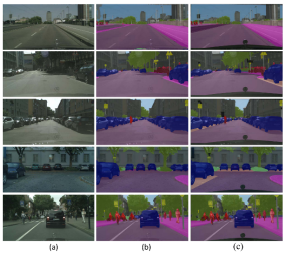
图7.本方法在Cityscapes验证集上的一些典型的分割结果示例。其中,(a)表示输入RGB图片,(b)表示本方法所得到的分割结果,(c)表示分割的真值标签。
(b)Camvid数据集
CamVid数据集[29]采集于高分辨率道路场景的视频帧,其包含了32个不同的语义类别和701张图片。遵循之前的工作[34]、[38],本实验采用了其中11个类别来评估模型的性能,并且将数据集划分为367/101/233用于模型的训练、验证和测试。表4总结了本方法与最近其他相关工作之间的性能对比。
表4. 本方法在Camvid数据集上的性能。
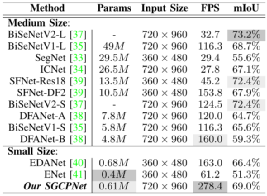
表5. 基于CPU测得的模型速度和精度。
性能分析:与其他小尺寸模型相比,SGCPNet能在准确性和效率之间取得更好的平衡。例如,SGCPNet的分割精度比EDANet [40]和ENet [41]高出2.6%和17.7%,并且分割速度也同样比他们快115.4 FPS和217.2 FPS。SGCPNet的分割精度仍能排在中型模型的第四位,并且它的型模参数要更少、分割速度要更快,如SGCPNet的模型大小仅是SFNet-Res18 [39]的二十分之一。Camvid数据集上的实验结果也同样表明了本模型在资源受限场景下的语义分割任务中具有一定的优势。
D. 消融实验
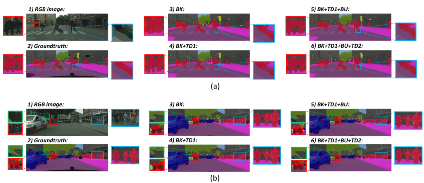
图8.自上而下和自下而上路径对最终分割结果影响的可视化。
表6. 对各个组件的消融实验。“BK”表示主干网络,“HFR”表示采用了更高维的特征表示(即Layer -3†、Layer -4†和Layer- 5†)。“TD1”和“TD2”表示第一个和第二个自上而下路径,“BU”表示自下而上路径。“SW-SUM”表示标量加权求和操作。
V. 结论
本研究设计了基于空间细节引导的上下文传播网络(SGCPNet)并用于实时语义分割任务之中。该模型在上下文信息学习和提取过程中无需维持高分辨率特征图,并仍能很好地保留充足的上下文和空间细节信息,因而能够在分割精度和效率上取得较好的平衡。从各类测试结果中可以看到,本方法有应用于资源受限下语义分割的潜力。
参考文献
[1] H. Rahmani, A. Mian, and M. Shah, “Learning a deep model for human action recognition from novel viewpoints,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 40, no. 3, pp. 667–681, Mar. 2018.
[2] P. Zhang, C. Lan, J. Xing, W. Zeng, J. Xue, and N. Zheng, “View adaptive neural networks for high performance skeleton-based human action recognition,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 41, no. 8, pp. 1963–1978, Aug. 2019.
[3] Y. Pang, J. Cao, Y. Li, J. Xie, H. Sun, and J. Gong, “TJU-DHD: A diverse high-resolution dataset for object detection,” IEEE Trans. Image Process., vol. 30, pp. 207–219, 2021.
[4] Y. Li, Y. Pang, J. Cao, J. Shen, and L. Shao, “Improving single shot object detection with feature scale unmixing,” IEEE Trans. Image Process., vol. 30, pp. 2708–2721, 2021.
[5] J. Xie, Y. Pang, H. Cholakkal, R. Anwer, F. Khan, and L. Shao, “PSC-Net: Learning part spatial co-occurrence for occluded pedestrian detection,” Sci. China Inf. Sci., vol. 64, no. 2, pp. 1–13, Feb. 2021. [6] S. Yun, J. Choi, Y. Yoo, K. Yun, and J. Y. Choi, “Action-driven visual object tracking with deep reinforcement learning,” IEEE Trans. Neural Netw.Learn.Syst., vol. 29, no. 6, pp. 2239–2252, Jun. 2018. [7] L. Zhao, X. Gao, D. Tao, and X. Li, “Learning a tracking and estimation integrated graphical model for human pose tracking,” IEEE Trans. Neural Netw. Learn. Syst., vol. 26, no. 12, pp. 3176–3186, Dec. 2015.
[8] W. Shi, J. Cao, Q. Zhang, Y. Li, and L. Xu, “Edge computing: Vision and challenges,” IEEE Internet Things J., vol. 3, no. 5, pp. 637–646, Oct. 2016.
[9] J. Chen and X. Ran, “Deep learning with edge computing: A review,” Proc. IEEE, vol. 107, no. 8, pp. 1655–1674, Aug. 2019.
[10] X. Wang, Y. Han, V. C. M. Leung, D. Niyato, X. Yan, and X. Chen, “Convergence of edge computing and deep learning: A comprehensive survey,” IEEE Commun. Surveys Tuts., vol. 22, no. 2, pp. 869–904, 2nd Quart., 2020.
[11] S.-C. Lin et al., “The architectural implications of autonomous driving: Constraints and acceleration,” in Proc. 23rd Int. Conf. Architectural Support Program. Lang. Operating Syst., Mar. 2018, pp. 751–766.
[12] S. Liu, J. Tang, Z. Zhang, and J.-L. Gaudiot, “Computer architectures for autonomous driving,” Computer, vol. 50, no. 8, pp. 18–25, 2017.
[13] S. Liu, L. Liu, J. Tang, B. Yu, and W. Shi, “Edge computing for autonomous driving: Opportunities and challenges,” Proc. IEEE, vol. 107, no. 8, pp. 1697–1716, Jun. 2019.
[14] M. H. Hesamian, W. Jia, X. He, and P. Kennedy, “Deep learning techniques for medical image segmentation: Achievements and challenges,” J. Digit. Imag., vol. 32, no. 4, pp. 582–596, 2019.
[15] H. Zhao, J. Shi, X. Qi, X. Wang, and J. Jia, “Pyramid scene parsing network,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Jul. 2017, pp. 2881–2890.
[16] L.-C. Chen, G. Papandreou, I. Kokkinos, K. Murphy, and A. L. Yuille, “DeepLab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 40, no. 4, pp. 834–848, Apr. 2017.
[17] J. Fu et al., “Dual attention network for scene segmentation,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2019, pp. 3146–3154.
[18] S. Han, H. Mao, and W. J. Dally, “Deep compression: Compressing deep neural networks with pruning, trained quantization and Huffman coding,” 2015, arXiv:1510.00149.
[19] S. Bhattacharya and N. D. Lane, “Sparsification and separation of deep learning layers for constrained resource inference on wearables,” in Proc. 14th ACM Conf. Embedded Netw. Sensor Syst. (CD-ROM), Nov. 2016, pp. 176–189.
[20] S. Yao, Y. Zhao, A. Zhang, L. Su, and T. Abdelzaher, “DeepIoT: Compressing deep neural network structures for sensing systems with a compressor-critic framework,” in Proc. 15th ACM Conf. Embedded Netw. Sensor Syst., Nov. 2017, pp. 1–14.
[21] G. Hinton, O. Vinyals, and J. Dean, “Distilling the knowledge in a neural network,” 2015, arXiv:1503.02531.
[22] S. Liu, Y. Lin, Z. Zhou, K. Nan, H. Liu, and J. Du, “On-demand deep model compression for mobile devices: A usage-driven model selection framework,” in Proc. 16th Annu. Int. Conf. Mobile Syst., Appl., Services, Jun. 2018, pp. 389–400.
[23] W. Liu, A. Rabinovich, and A. C. Berg, “ParseNet: Looking wider to see better,” 2015, arXiv:1506.04579.
[24] H. Zhang et al., “Context encoding for semantic segmentation,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., Jun. 2018, pp. 7151–7160.
[25] J. He, Z. Deng, L. Zhou, Y. Wang, and Y. Qiao, “Adaptive pyramid context network for semantic segmentation,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2019, pp. 7519–7528.
[26] F. Yu and V. Koltun, “Multi-scale context aggregation by dilated convolutions,” 2015, arXiv:1511.07122.
[27] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2016, pp. 770–778.
[28] M. Cordts et al., “The cityscapes dataset for semantic urban scene understanding,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2016, pp. 3213–3223.
[29] G. J. Brostow, J. Fauqueur, and R. Cipolla, “Semantic object classes in video: A high-definition ground truth database,” Pattern Recognit. Lett., vol. 30, no. 2, pp. 88–97, 2008.
[30] Z. Huang, X. Wang, L. Huang, C. Huang, Y. Wei, and W. Liu, “CCNet: Criss-cross attention for semantic segmentation,” in Proc. IEEE/CVF Int. Conf. Comput. Vis. (ICCV), Oct. 2019, pp. 603–612. [31] S. Ma, Y. Pang, J. Pan, and L. Shao, “Preserving details in semanticsaware context for scene parsing,” Sci. China Inf. Sci., vol. 63, no. 2, pp. 1–14, Feb. 2020. [32] Z. Zhang and Y. Pang, “CGNet: Cross-guidance network for semantic segmentation,” Sci. China Inf. Sci., vol. 63, no. 2, pp. 1–16, Feb. 2020. [33] V. Badrinarayanan, A. Kendall, and R. Cipolla, “SegNet: A deep convolutional encoder-decoder architecture for image segmentation,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 39, no. 12, pp. 2481–2495, Jan. 2017. [34] H. Zhao, X. Qi, X. Shen, J. Shi, and J. Jia, “ICNet for real-time semantic segmentation on high-resolution images,” in Proc. Eur. Conf. Comput. Vis., Sep. 2018, pp. 405–420. [35] C. Yu, J. Wang, C. Peng, C. Gao, G. Yu, and N. Sang, “BiseNet: Bilateral segmentation network for real-time semantic segmentation,” in Proc. Eur. Conf. Comput. Vis. (ECCV), Sep. 2018, pp. 325–341. [36] R. P K Poudel, U. Bonde, S. Liwicki, and C. Zach, “ContextNet: Exploring context and detail for semantic segmentation in real-time,” 2018, arXiv:1805.04554.
[37] C. Yu, C. Gao, J. Wang, G. Yu, C. Shen, and N. Sang, “BiSeNet v2: Bilateral network with guided aggregation for real-time semantic segmentation,” 2020, arXiv:2004.02147.
[38] H. Li, P. Xiong, H. Fan, and J. Sun, “DFANet: Deep feature aggregation for real-time semantic segmentation,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2019, pp. 9522–9531.
[39] X. Li et al., “Semantic flow for fast and accurate scene parsing,” 2020, arXiv:2002.10120.
[40] S.-Y. Lo, H.-M. Hang, S.-W. Chan, and J.-J. Lin, “Efficient dense modules of asymmetric convolution for real-time semantic segmentation,” in Proc. ACM Multimedia Asia, Dec. 2019, pp. 1–6. [41] A. Paszke, A. Chaurasia, S. Kim, and E. Culurciello, “ENet: A deep neural network architecture for real-time semantic segmentation,” 2016, arXiv:1606.02147.
[42] F. Chollet, “Xception: Deep learning with depthwise separable convolutions,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Jul. 2017, pp. 1251–1258.
[43] A. Howard et al., “Searching for MobileNetV3,” in Proc. IEEE/CVF Int. Conf. Comput. Vis. (ICCV), Oct. 2019, pp. 1314–1324.
[44] M. Treml et al., “Speeding up semantic segmentation for autonomous driving,” in Proc. MLITS, NIPS Workshop, vol. 2, 2016, p. 7.
[45] T. Pohlen, A. Hermans, M. Mathias, and B. Leibe, “Full-resolution residual networks for semantic segmentation in street scenes,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Jul. 2017, pp. 4151–4160.
[46] J. Long, E. Shelhamer, and T. Darrell, “Fully convolutional networks for semantic segmentation,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2015, pp. 3431–3440.
[47] Z. Wu, C. Shen, and A. van den Hengel, “Real-time semantic image segmentation via spatial sparsity,” 2017, arXiv:1712.00213.
[48] H. Zhao et al., “PSANet: Point-wise spatial attention network for scene parsing,” in Proc. Eur. Conf. Comput. Vis., Sep. 2018, pp. 267–283.
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“SGCP” 就可以获取《【TNNLS2022】SGCPNet: 面向实时语义分割的空间细节引导上下文传播网络》专知下载链接





