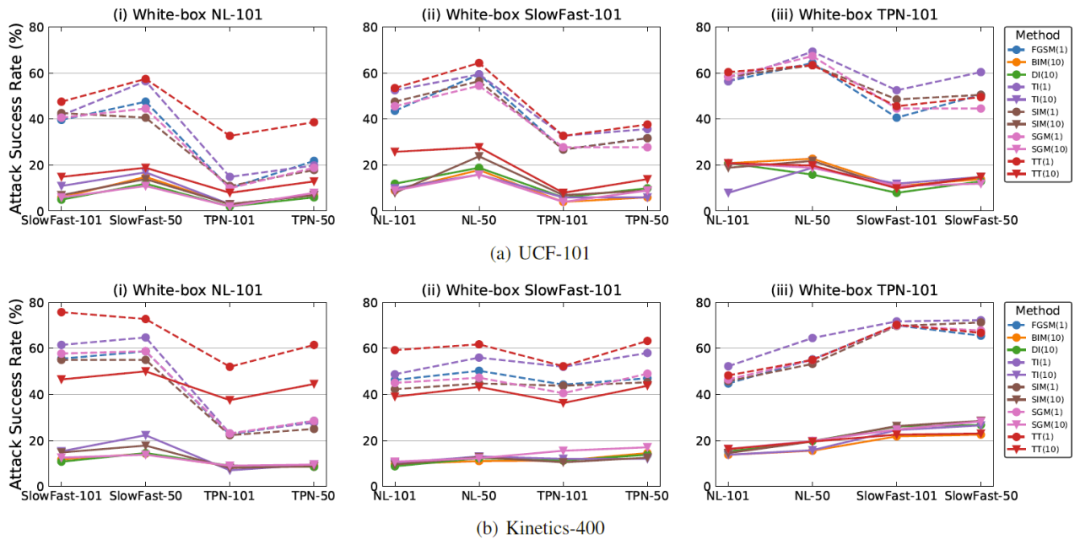
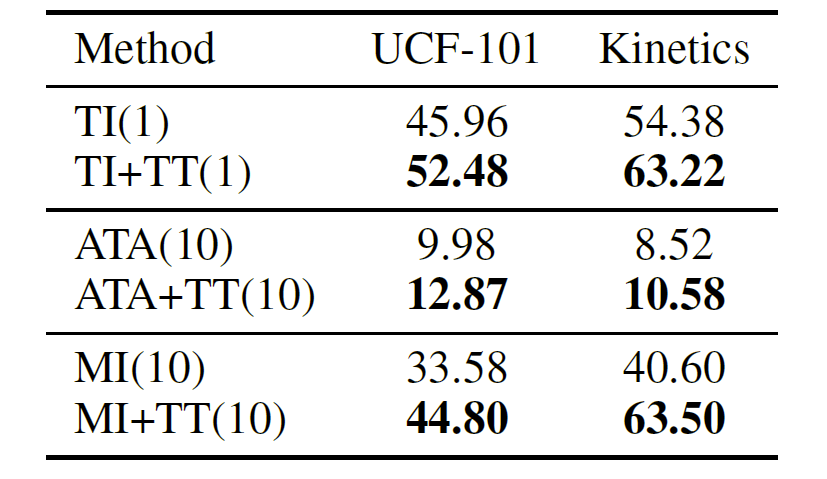
首个基于时序平移的视频迁移攻击算法,复旦大学研究入选AAAI 2022
复旦大学开展针对视频模型中对抗样本迁移性的研究,以促进视频模型的安全发展。

论文链接:https://arxiv.org/pdf/2110.09075.pdf
代码链接:https://github.com/zhipeng-wei/TT
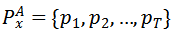 ,其中T表示输入视频帧的数目。
那么针对模型A和模型B,可得到
,其中T表示输入视频帧的数目。
那么针对模型A和模型B,可得到
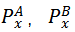 ,结合 Spearman’s Rank Correlation,可计算模型间时序判别模式的相似性
,结合 Spearman’s Rank Correlation,可计算模型间时序判别模式的相似性
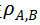 ,即
,即
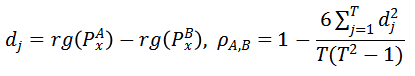
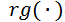 执行基于重要性值的排序操作并返回视频各帧的排序值。
执行基于重要性值的排序操作并返回视频各帧的排序值。
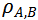 的值在-1和1之间,当其等于0时表示模型A和模型B间的判别模式不存在关系,而-1或者1则表示明确的单调关系。
的值在-1和1之间,当其等于0时表示模型A和模型B间的判别模式不存在关系,而-1或者1则表示明确的单调关系。
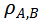 的值越大则模型间的判别模式越相似。
基于此,可实现不同视频模型时序判别模式间关系的度量。
的值越大则模型间的判别模式越相似。
基于此,可实现不同视频模型时序判别模式间关系的度量。

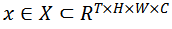 表示输入视频,
表示输入视频,
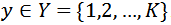 表示其对应真实标签,其中T,H,W,C分别表示帧数,高度,宽度和通道数,K表示类别数目。
使用
表示其对应真实标签,其中T,H,W,C分别表示帧数,高度,宽度和通道数,K表示类别数目。
使用
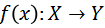 表示视频模型对于视频输入的预测结果。
定义
表示视频模型对于视频输入的预测结果。
定义
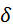 为对抗噪声,那么攻击目标可以定义为
为对抗噪声,那么攻击目标可以定义为
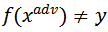 ,其中
,其中
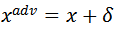 ,且限制
,且限制
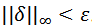 。
定义
。
定义
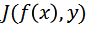 为损失函数。
则非目标攻击的目标函数可定义为:
为损失函数。
则非目标攻击的目标函数可定义为:
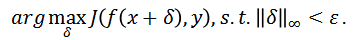
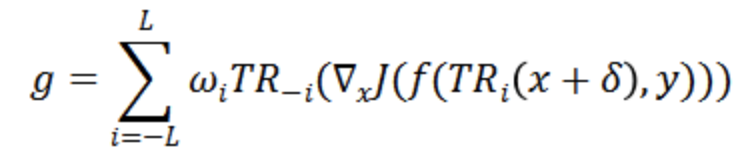
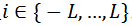 。
函数
。
函数
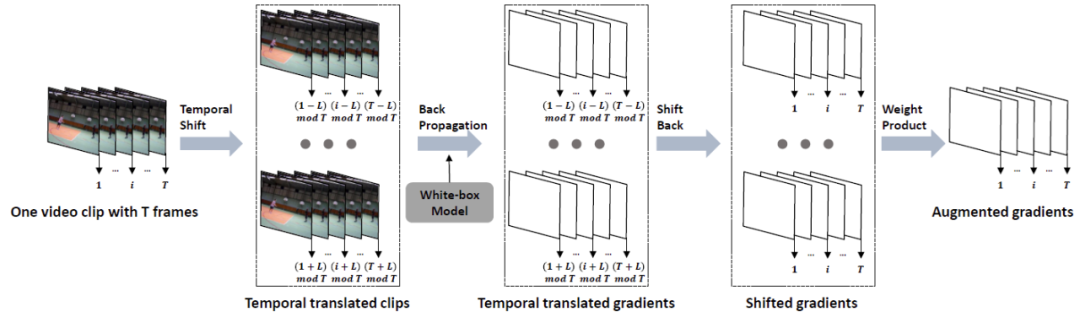
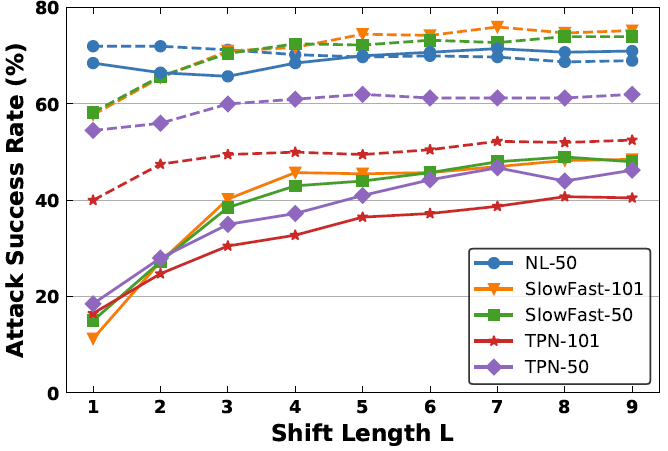
 表示将所有的视频输入沿着时序维度平移i帧。
当平移后的位置大于T时,设当前帧为第i帧,即t+i>T,则第t帧的位置变为第t+i-T帧,否则为第t+i帧。
而在时序平移后的视频输入上计算完梯度后,仍会沿着时序维度平移回原始视频帧序列,并通过w_i来整合来自不同平移长度的梯度信息。w_i
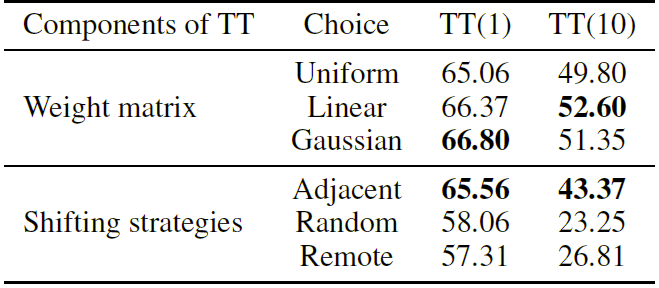
可利用均一、线性、高斯三种方式生成(参考 Translation-invariant 攻击方法)。
表示将所有的视频输入沿着时序维度平移i帧。
当平移后的位置大于T时,设当前帧为第i帧,即t+i>T,则第t帧的位置变为第t+i-T帧,否则为第t+i帧。
而在时序平移后的视频输入上计算完梯度后,仍会沿着时序维度平移回原始视频帧序列,并通过w_i来整合来自不同平移长度的梯度信息。w_i
可利用均一、线性、高斯三种方式生成(参考 Translation-invariant 攻击方法)。
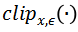 用来限制生成的对抗噪声满足
用来限制生成的对抗噪声满足
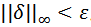 。
。

苏黎世联邦理工DS3Lab:构建以数据为中心的机器学习系统

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com
登录查看更多
相关内容

对抗样本由Christian Szegedy等人提出,是指在数据集中通过故意添加细微的干扰所形成的输入样本,导致模型以高置信度给出一个错误的输出。在正则化背景下,通过对抗训练减少原有独立同分布的测试集的错误率——在对抗扰动的训练集样本上训练网络。
对抗样本是指通过在数据中故意添加细微的扰动生成的一种输入样本,能够导致神经网络模型给出一个错误的预测结果。
实质:对抗样本是通过向输入中加入人类难以察觉的扰动生成,能够改变人工智能模型的行为。其基本目标有两个,一是改变模型的预测结果;二是加入到输入中的扰动在人类看起来不足以引起模型预测结果的改变,具有表面上的无害性。对抗样本的相关研究对自动驾驶、智能家居等应用场景具有非常重要的意义。
Arxiv
13+阅读 · 2018年1月6日



相关VIP内容
相关资讯
相关论文
Arxiv
13+阅读 · 2018年1月6日