NeurIPS 2021 | 类别解耦及其在对抗检测和防御中的应用

预测一个图像的类别, 神经网络所需的最少必要信息是什么?在输入的图像空间提取这种信息能够帮助我们了解神经网络主要关注的区域,并且为对抗检测和防御提供新的思路。在本文中,我们提出了一个基于VAE-分类器的类别解耦方法,通过VAE和分类器的互相竞争,把输入图片解耦成类别相关和类别冗余的两部分。我们分别对自然样本和对抗样本做类别解耦,发现对抗噪声主要集中类别相关的部分,这对于分类模型和对抗攻击提供了新的解释。
基于这个发现,我们提出在类别相关部分上进行对抗样本的检测,在类别冗余的部分上进行对抗样本的防御,这两个简单的策略能够大幅提升检测和防御多种未知对抗攻击的性能。本工作是由京东探索研究院、中国科学技术大学、华盛顿大学西雅图分校、马里兰大学帕克分校联合完成,已经被NeurIPS 2021 接收。


01
研究背景
近年来,深度学习在很多领域取得了非常好的效果,但是深度神经网络仍然存在这以下两点问题:
(1)神经网络的可解释性差:虽然神经网络能够在很多下游任务取得非常高的准确率,但是人们不知道神经网络是依赖于输入中的哪些信息。那么我们能否如图1所示,在输入层面将图片解耦成类别相关和类别冗余的两部分,其中类别相关的部分就是神经网络主要依赖来完成对下游任务的预测的部分。这样我们就能够解释神经网络的推理行为,分析复杂的数据结构。

图1 在输入层面进行类别解耦
(2)神经网络的脆弱性:众所周知,训练好的神经网络对于输入层面的微小对抗性扰动十分敏感和脆弱。但是该如何解释这种现象呢?对抗扰动主要攻击的是神经网络的哪些部分呢?为了回答这些问题,也需要我们在输入层面讲输入样本解耦成类别相关和类别冗余的两部分,其中类别相关的部分很可能就是对抗攻击主要攻击的部分。那么我们就可以基于类别相关的部分来进行对抗样本的检测,同时利用没有被对抗样本攻击到的类别冗余的部分进行对抗防御。
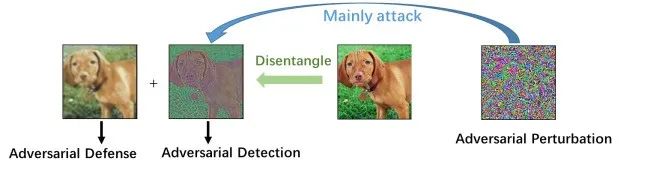
图2 类别解耦用于对抗样本的检测和防御
02
类别解耦
1、类别解耦的变分自编码器
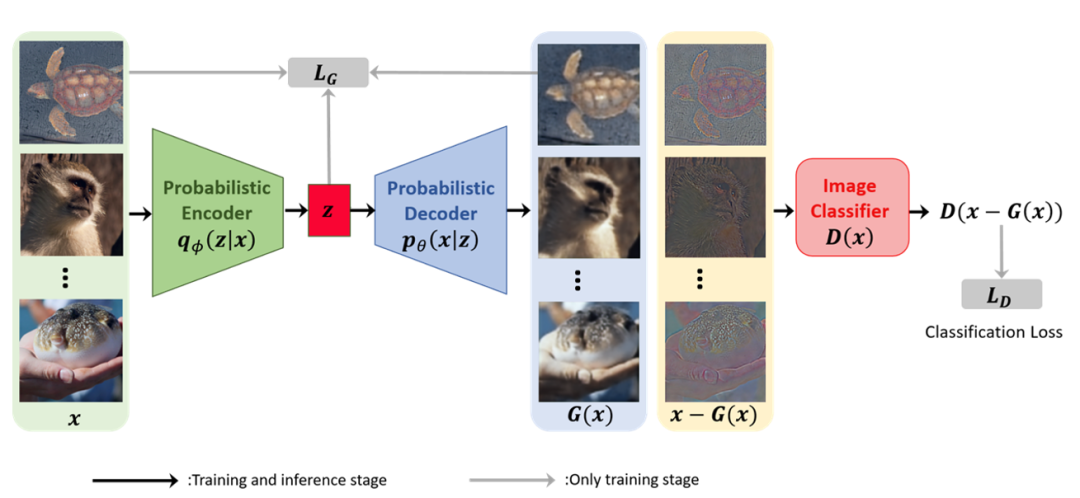
图3 类别解耦的变分自编码器
我们提出了一个模型,能在输入层面将样本解耦成类别相关和类别冗余的两部分。我们的模型叫做类别解耦的变分自动编码器(CD-VAE),由一个变分自编码器 (VAE)[2] 和一个分类器组成。如图3所示,我们使用VAE重构出类冗余部分
目标函数如公式(1)-(3)所示,由
(1)
(2)
(3)
CD-VAE可用于分析神经网络的行为和复杂数据的内在属性。例如,
2 、比较自然样本和对抗样本的类别解耦

表1各个解耦部分的

图 4 各个解耦部分的可视化
为了进一步研究对抗样本是如何攻击分类器的,我们提供了一项实证研究来比较自然样本
我们可以看一下
然后我们可以看类别相关部分
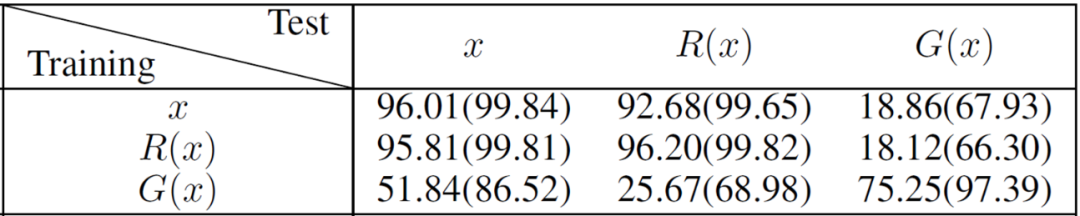
表2 在各个解耦部分训练并测试分类器:Top-1 (Top-5)。
为了进一步了解类别信息在
3、类别解耦在对抗检测中的应用
我们的发现可以直接导出在对抗检测和防御中的两个应用。
首先,我们可以在
4、类别解耦在对抗防御中的应用
如前表所示,
最后,我们扩展CD-VAE来防御最具挑战性的白盒攻击。在这里,我们允许攻击方访问我们的所有模型,包括分类器和CD-VAE。之前我们提出使用
(8)
(9)
给定一个对抗样本
03
实验结果
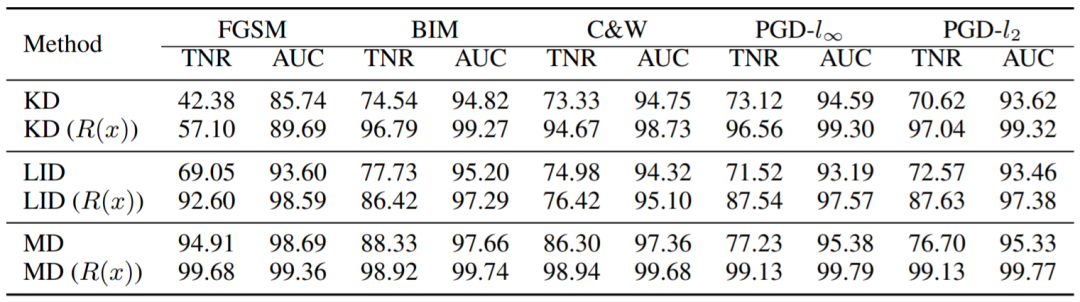
表3 对于5种对抗攻击的检测效果(CIFAR10)
表3是对抗性检测的结果。我们在三个基线[4-6]上进行实验,并将我们的方法应用于这三个基线,只需将它们的输入 由
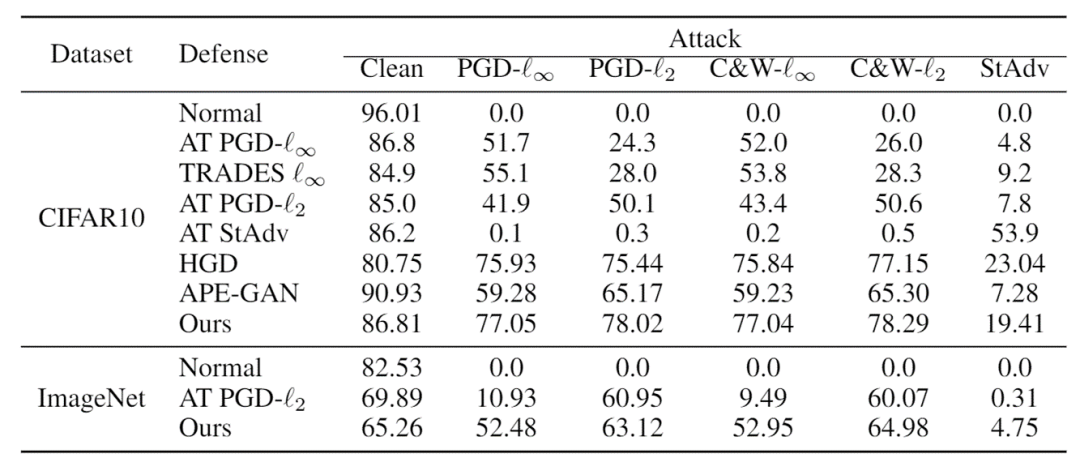
表4 针对灰盒攻击的防御效果(CIFAR10和Restricted-ImageNet)
表4是针对灰盒攻击的防御效果。CD-VAE优于基于对抗训练的方法和其他基于预处理的方法(HGD[7]、APE-GAN[8])。例如,PGD 是一种非常流行的攻击方法,我们的方法可以将对于PGD 攻击的鲁棒性提高 2% 以上。
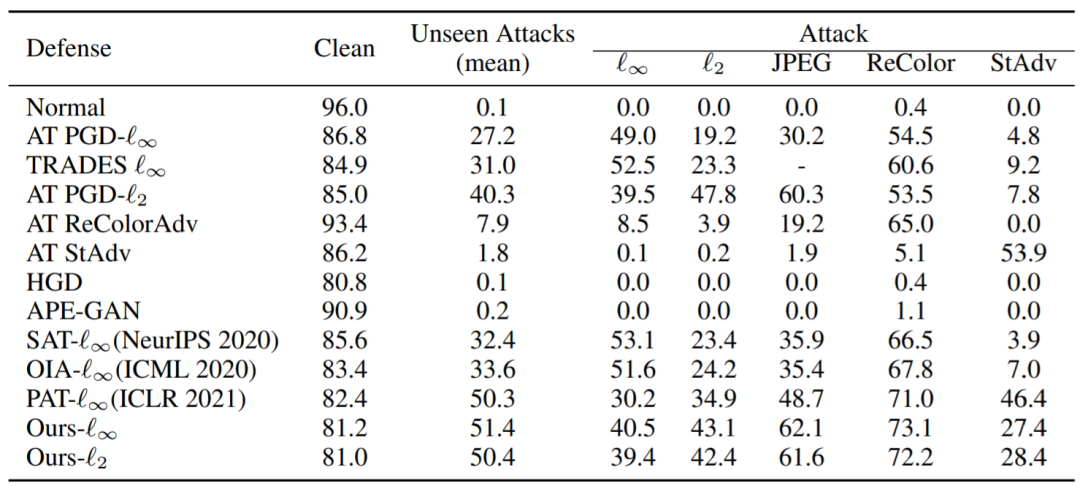
表5 针对白盒攻击的鲁棒性 (CIFAR10)
表5是针对白盒攻击的鲁棒性。我们针对多种白盒攻击评估我们的方法和基线。我们的方法十分鲁棒,尤其对于那些未见过的攻击(即没有用于对抗训练的攻击),它实现了最高的未见攻击(平均)准确度。而其他基于对抗训练的方法对用于训练的攻击方法效果很好,但无法应对未见过的攻击。例如,使用 recolor 进行对抗训练的模型对recolor attack防御效果很好,但对 stadv的防御却很失败,得到接近 0 的准确率。相反,即使我们在训练期间没有使用 stadv,但对 stadv 依然十分鲁棒。
04
结论
在本文中,我们提出了一个基于VAE+分类器的类别解耦模型:类别解耦的变分自动编码器(CD-VAE)来将输入图像x分解为
文章:https://proceedings.neurips.cc/paper/2021/file/8606f35ec6c77858dfb80a385d0d1151-Paper.pdf
代码:https://github.com/kai-wen-yang/CD-VAE
参考文献
THE END



