在本文中,阿里安全、澳大利亚斯威本科技大学和 EPFL 的研究者提出了一种新型 ViT 模型(Robust Vision Transformer, RVT),以及两项提高 ViT 鲁棒性的训练技术:位置相关的注意力缩放(PAAS)和基于图像块的数据增强。RVT 显著提升了视觉分类的鲁棒性和泛化性,在多个 ImageNet 鲁棒性基准上取得了 SOTA 效果。上述研究成果已被 CVPR 2022 收录。
尽管深度神经网络在视觉识别任务上已经取得了巨大成功,但其在对抗攻击和数据域偏移下的脆弱性一直被诟病。针对该问题,大量在对抗样本和域偏移下的识别鲁棒性研究被提出,这些研究通常从更强的数据增强、模型正则、训练策略、更优的网络结构设计方面提升深度模型的鲁棒性。其中,大多数鲁棒性研究将 CNN 结构作为前提假设,所提出的鲁棒训练方案也仅适用于 CNN 结构。
近年来,Dosovitskiy 等人提出 ViT 模型,它将 transformer 结构引入计算机视觉,并在图像分类任务上优于 CNN。得益于其强大的建模能力,基于 transformer 的视觉结构迅速占领了各种任务的排行榜,包括目标检测和语义分割等。随着 ViT 开始撼动 CNN 模型的统治地位,针对新型 ViT 模型的鲁棒训练方法需要被提出。
目前已有研究开始对比 ViT 和 CNN 之间的鲁棒性,并通过实验得出 ViT 在通用扰动上的识别能力强于 CNN,然而该研究仅仅得出经验性的初步结论,缺乏对 ViT 模型每个组件和设计单元的具体分析。另一方面,大量 ViT 变体,例如 Swin、PVT 等相继提出。所有 ViT 的变体均只考虑模型在正常样本上的识别表现,缺乏在对抗和通用扰动下的鲁棒性探讨。
在近日被 CPVR 2022 接收的论文《Towards Robust Vision Transformer》中,阿里巴巴人工智能治理与可持续发展研究中心 (AAIG) 的研究者
首次对 ViT 模型的组成部分和设计单元进行拆解,并单独对 ViT 中不同模块的不同设计方法进行鲁棒性探究
。通过综合研究结论,他们提出了一种更为鲁棒的新型 ViT 模型 RVT,并在多个视觉分类的鲁棒性和泛化性基准上优于 SOTA ViT 和卷积神经网络。
![]()
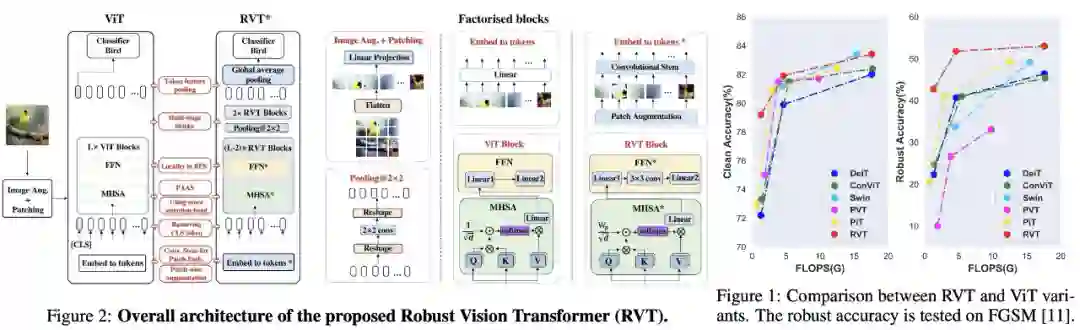
下图左为 RVT 模型的整体架构,图右为 RVT 与不同 ViT 变体的比较。
![]()
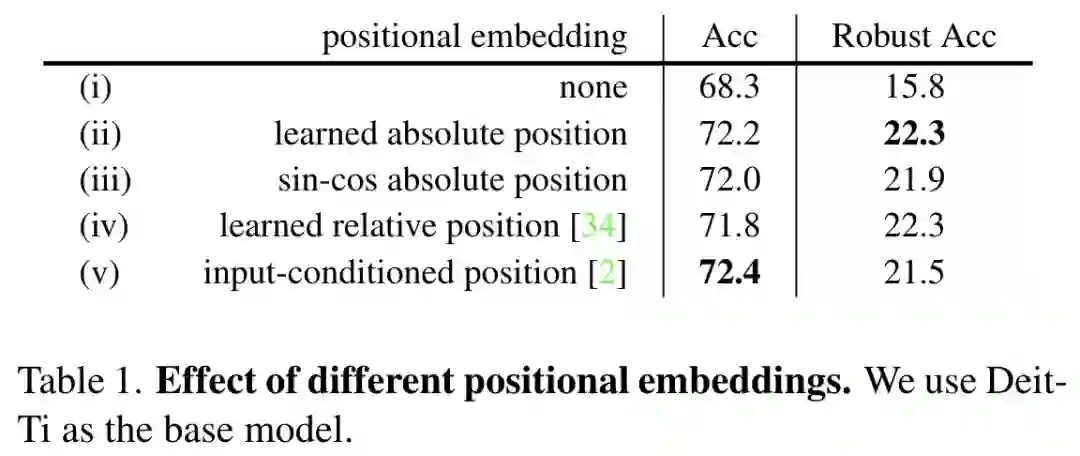
研究者采用 DeiT-T 作为基准模型,采用 ImageNet 验证集和 FGSM 攻击算法下的准确率分别作为正常以及鲁棒识别能力指标。下表 1 给出了不同位置嵌入的影响,
位置嵌入对于形状特征的提取起到了关键作用,而不同位置嵌入方式并未发现显著差异
。
![]()
下表 2 分别展示了图像块特征提取方式、自注意力范围、以及不同前馈层和分类层形式的影响。实验经验性地发现使用卷积提取图像块特征,并采用全局自注意力和用于分类的 CLS token,通常使得 ViT 具备更好的鲁棒性。
![]()
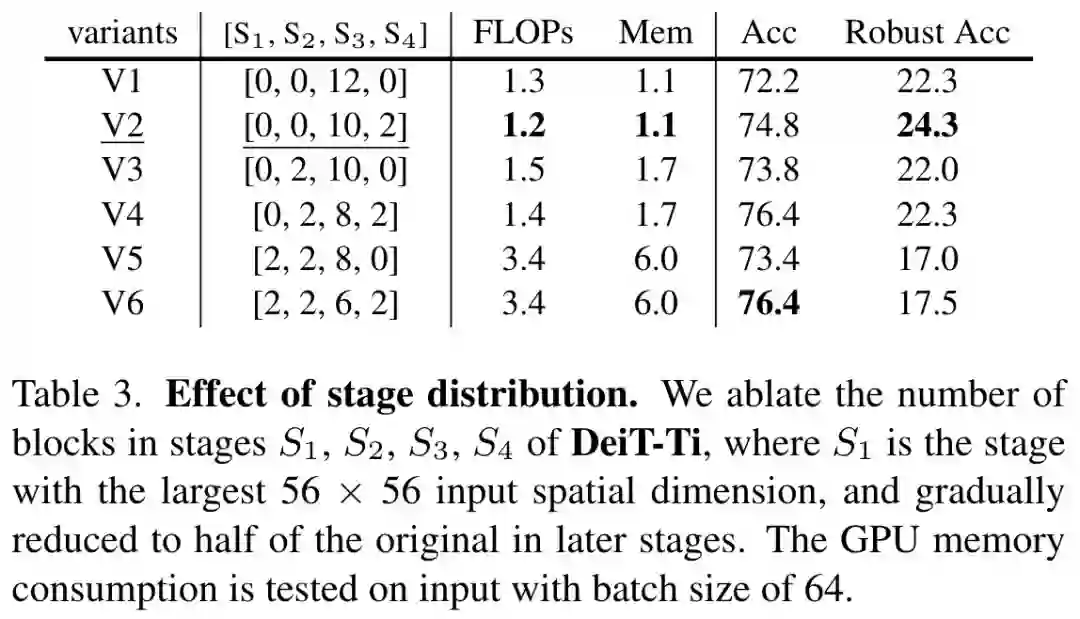
下表 3 研究了当 ViT 采用类似 CNN 中阶段性下采样的设计,是否会影响鲁棒性。当自注意力在大尺寸特征图上计算时,会引起计算量显著增加,并大幅损害模型鲁棒性,反之大尺度的自注意力层具备更好的鲁棒性。
![]()
自注意力通常采用多头的形式以增强表征能力。由下表 4 看出,多头注意力同时也增强了鲁棒性,但当注意力头持续增加至冗余,模型表现不升反降,因此为选择 ViT 选择合适的注意力头数是至关重要的。
![]()
根据以上发现,研究者提出了
更加鲁棒的新型 ViT 模型 RVT,相比原始 ViT 模型,RVT 具备鲁棒性的同时,正常场景下识别能力更强,计算也更加高效
。
位置相关的自注意力缩放将点积注意力中缩放操作修改为更通用的版本,即点积注意力中,每一对 query-key 的点积会被可学习的位置重要性矩阵缩放,取代原始的常数
![]() ,d 为特征维数。使用位置相关的自注意缩放可有效提升模型的鲁棒性。
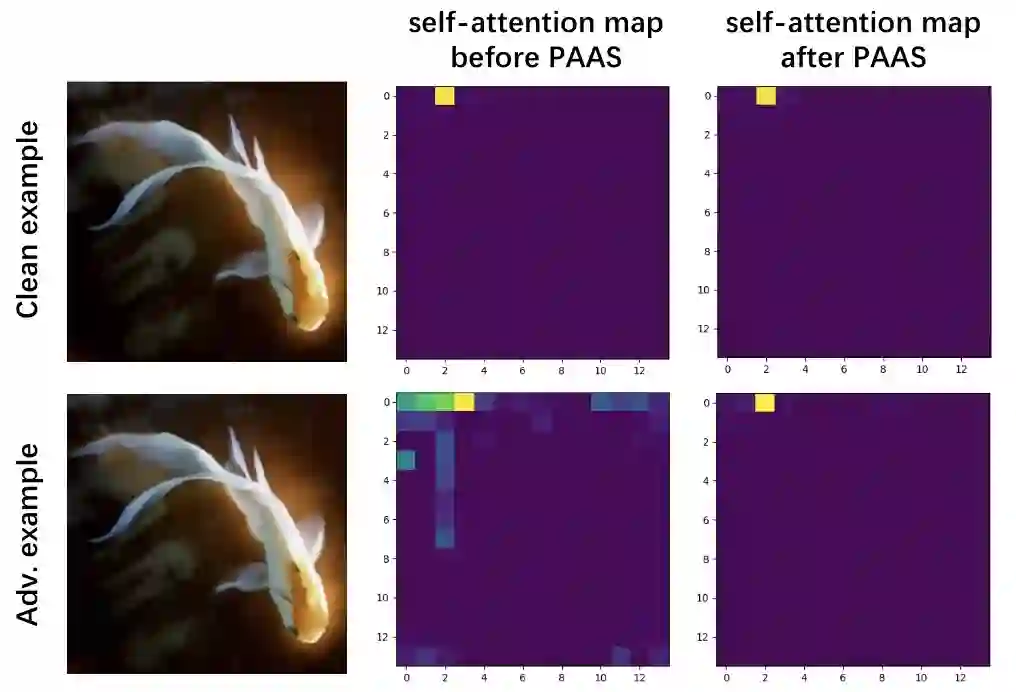
如下图所示,在对抗样本输入下,ViT 的自注意力图出现噪声并激活一些不相关区域,使用位置相关的自注意力缩放后,该噪声被有效抑制,并只有对分类有帮助的相关位置被激活,间接提升了鲁棒性。
,d 为特征维数。使用位置相关的自注意缩放可有效提升模型的鲁棒性。
如下图所示,在对抗样本输入下,ViT 的自注意力图出现噪声并激活一些不相关区域,使用位置相关的自注意力缩放后,该噪声被有效抑制,并只有对分类有帮助的相关位置被激活,间接提升了鲁棒性。
![]()
传统的数据增强通过提高训练数据多样性防止模型过拟合。相比 CNN,ViT 需要更大量训练数据以收敛至最优,数据增强的作用因此尤为明显。与 CNN 不同的是,ViT 将输入图像切分为图像块单独提取特征后,再送入注意力层。
传统数据增强对所有图像块使用相同增强方式,为针对 ViT 模型进一步提升训练数据多样性,本文提出对切分的图像块采用不同随机数据增强,即对于切分后的各个图像块,再独立做随机裁剪缩放,随机水平翻转,添加随机高斯噪声等简单图像变换。
与 MixUp、AugMix、RandAugment 类似,基于数据块的数据增强也有助于 ViT 模型的鲁棒性。通过对单个图像块做简单随机变换,等同于在图像块嵌入上添加有意义的干扰,在该干扰下的训练有助于模型抵抗未知干扰,进而提升对抗攻击下的识别率。
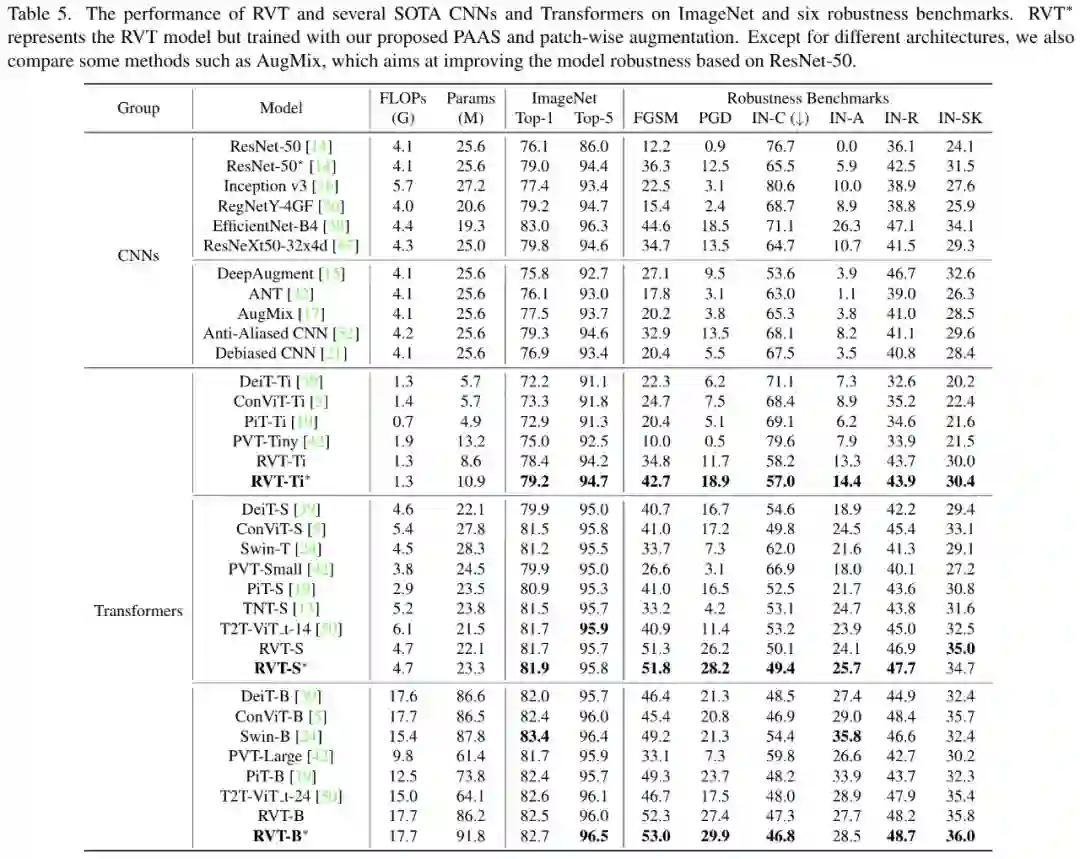
研究者设计了三个规模的 RVT 模型用于实验:RVT-T、RVT-S 和 RVT-B。将采用位置相关的自注意力缩放和基于图像块的数据增强两项改进的 RVT 模型标注为 RVT*。评测数据集包含 ImageNet-1K 中的验证集合、两个白盒攻击算法 FGSM 与 PGD、自然对抗样本集合 ImageNet-A、模拟图像损坏样本集合 ImageNet-C、黑白剪贴画图像样本集合 ImageNet-Sketch、人工创作非自然图像样本集合 ImageNet-R。
实验对比结果如表 5所示,RVT 在三个规模上均优于 CNN 和其他的 ViT 变体模型。对抗鲁棒性上,提出的 RVT-Ti 及 RVT-S 模型在 FGSM 上均获得了 10% 以上的提升。RVT-S * 在 ImageNet-C 上获得 49.4 的 mCE,该结果优于大部分通用鲁棒训练方法。RVT-B * 在 ImageNet-A、ImageNet-R、ImageNet-Sketch 上分别取得 28.5%、48.7%、36.0% 的准确率,超越了目前的 SOTA,充分验证了 RVT 应对测试数据域偏移的能力。
![]()
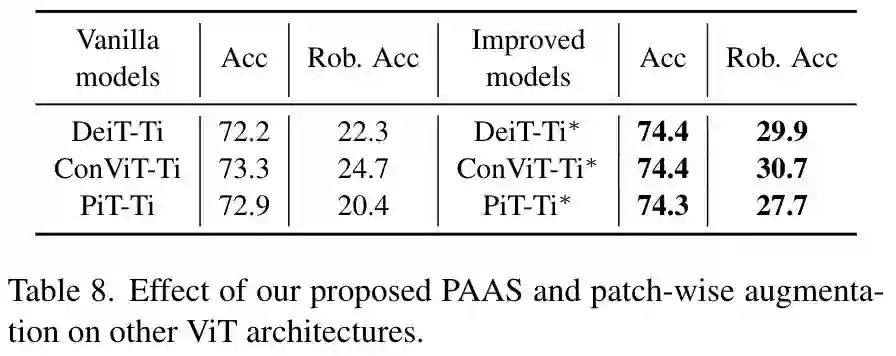
另外,除了应用于 RVT 模型之外,该研究提出的位置相关的自注意力缩放和基于图像块的数据增强还可广泛应用于其他 ViT 模型。
为验证其效果,研究者采用 DeiT-Ti、ConViT-Ti、PiT-Ti 三个基础模型,并分别在训练过程中使用位置相关的自注意力缩放和基于图像块的数据增强,结果显示三个基础模型均获得了显著提升,结果如下表 8 所示。
![]()
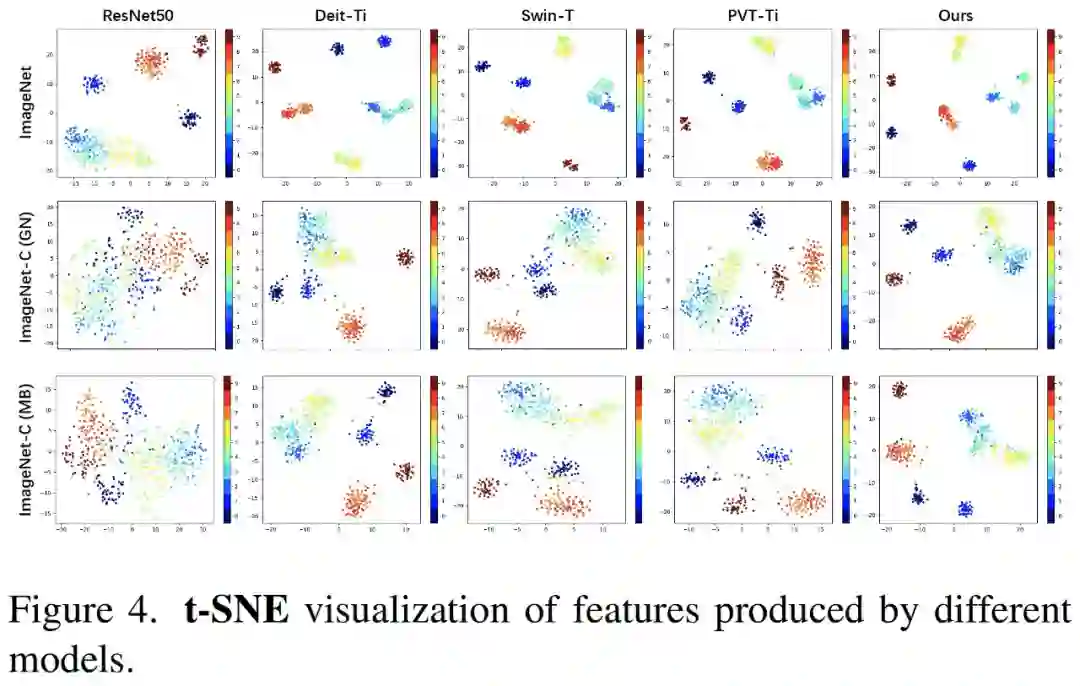
研究者还采用 t-SNE 技术对 RVT 模型提取特征进行降维及可视化,由下图 4 可看出,在正常分类样本和噪声样本上,RVT-S 的特征均更加紧凑,类内样本点靠近类簇,类间样本相距较远。该形态使得表征更具判别性,更难以被攻破。
![]()
论文一作为阿里巴巴人工智能治理与可持续发展研究中心算法工程师毛潇锋,主要研究方向为计算机视觉,对抗机器学习等,曾在AAAI/CVPR/MM/TIP上发表论文。
薛晖,阿里巴巴人工智能治理与可持续发展研究中心(AAIG)主任,带领团队在计算机视觉、自然语言处理、数据挖掘与网络安全等领域的国际顶级会议和期刊上发表论文100多篇,多次在国际国内知名赛事中取得冠军,获授权国内国际专利60余项,申请中专利达到200多项。
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com



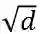 ,d 为特征维数。使用位置相关的自注意缩放可有效提升模型的鲁棒性。
,d 为特征维数。使用位置相关的自注意缩放可有效提升模型的鲁棒性。