TPAMI 2021|VideoDG:首个视频领域泛化模型
本文介绍TPAMI 2021的中稿论文:VideoDG: Generalizing Temporal Relations in Videos to Novel Domains。
作者:姚治宇*,王韫博*,王建民,俞士纶,龙明盛
链接:https://www.zhuanzhi.ai/paper/028b77e5d88a032032f2e567580b7d8d
代码:https://github.com/thuml/VideoDG

引言
传统的机器学习一般假设源领域(source domain)和目标领域(target domain)的数据分布符合独立同分布i.i.d假设。然而实际中,源领域和目标领域往往存在领域偏移(domain shift),即会有分布外Out of Distribution(OOD)情景出现。领域泛化(Domain Generalization)旨在仅通过使用源领域数据进行模型学习来实现在不可见的目标领域的OOD泛化。
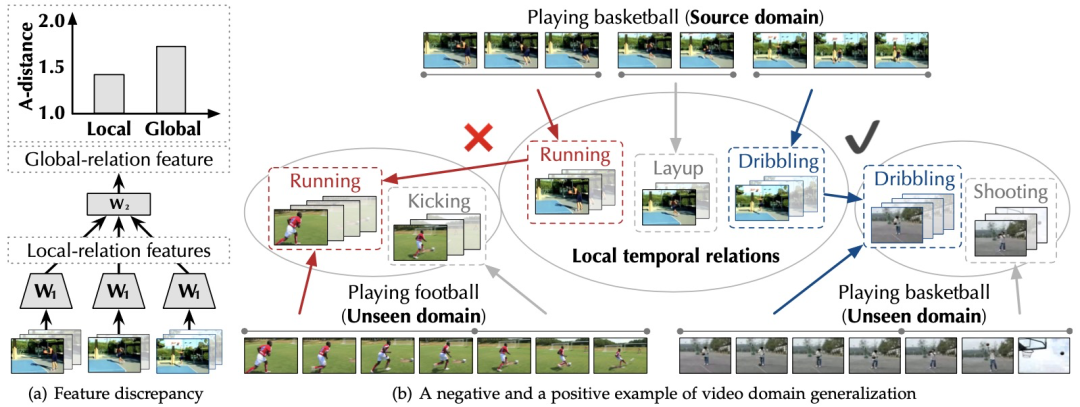
领域泛化的研究已经经历了十年的发展,涵盖了各种图像应用,例如图像识别,图像分割等。然而对于视频方面的应用,比如视频动作识别,领域泛化却鲜有涉及。本文致力于探究视频领域泛化(video domain generalization)在动作识别问题中的应用,我们认为训练更具泛化性的动作识别模型对解决视频领域泛化问题至关重要。比如,不同的人执行相同的动作在不同的场景下,模型往往可能无法识别一个执行在新的环境的旧动作。
在本文中,我们首先发现以前模型之所以视频领域泛化能力较差,是因为当泛化到目标领域时,目标时空数据同时存在着空域偏移(spatial domain shift)和时域偏移(temporal domain shift)。空域偏移是由于视频帧的静态特征的变化引起的,如图4所示,相同人做的动作在不同的视角下静态特征是完全不同的。以往的图像域泛化方法可以部分解决这一问题,比如对抗性自适应数据增强方法ADA。不同于图像之间只共享静态物体特征,时空序列之间会共享同一类型的局部时空运动特征,时域偏移往往由于局部时空运动在未知目标领域的意外缺失或错位而产生。如图1所示,运球上篮与踢足球共享“跑步”这一局部运动。
VideoDG的核心贡献主要是两个方面:
-
VideoDG通过对抗性金字塔网络( APN)在不同的时间尺度上校准局部时空运动关系和全局运动关系特征,利用全局时空运动防止局部时空泛化到错误的方向,兼顾了迁移性与判别性。 -
VideoDG引入了配套的鲁棒时空金字塔对抗数据增强方法( RADA)训练算法,使用 局部时空运动生成对抗样本来增强源领域并提高了APN对由关系特征衍生的不同时空对抗样本的鲁棒性。
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“RADA” 就可以获取《TPAMI 2021|VideoDG:首个视频领域泛化模型》专知下载链接




