国科大CVPR 2020论文:自监督学习新方法,让数据更复杂的视频表征学习性能大提升

新智元推荐
新智元推荐
编辑:元子
【新智元导读】自监督表征学习由于无需人工标注,特征较好的泛化性等优势受到了越来越多的关注,并不断有研究在图像、语言等领域取得了较大进展。本论文则立足于数据形式更为复杂的视频表征学习,介绍了一种简单且有效的自监督学习方法,并在视频动作分类和检索这两个常见的目标任务中提升了性能,该论文入选了CVPR2020.

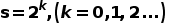 采样得到不同倍率
采样得到不同倍率
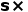 的快进视频段
的快进视频段
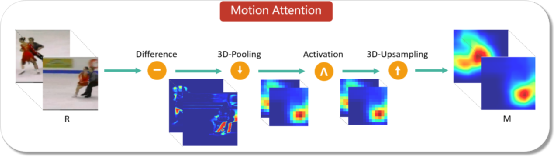
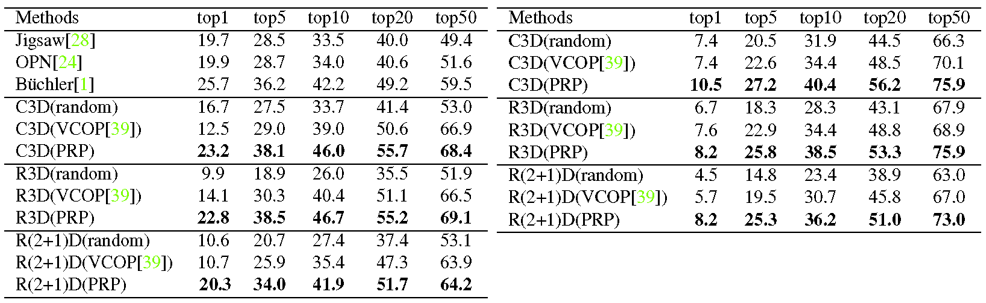
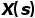 作为网络输入,之后通过基于间隔分类的判别感知和基于慢放重构的生成感知这两种模式进行视频的表征学习。对于输入的快进视频,判别感知通过进行采样间隔的分类促使网络注重前景运动的主要变化(低分辨率特性);生成感知通过进行一定倍率的插值重构促使网络还原更多的运动细节(高分辨率特性);最终二者通过共享网络主干和联合优化来达到表征学习的协同互补。
作为网络输入,之后通过基于间隔分类的判别感知和基于慢放重构的生成感知这两种模式进行视频的表征学习。对于输入的快进视频,判别感知通过进行采样间隔的分类促使网络注重前景运动的主要变化(低分辨率特性);生成感知通过进行一定倍率的插值重构促使网络还原更多的运动细节(高分辨率特性);最终二者通过共享网络主干和联合优化来达到表征学习的协同互补。
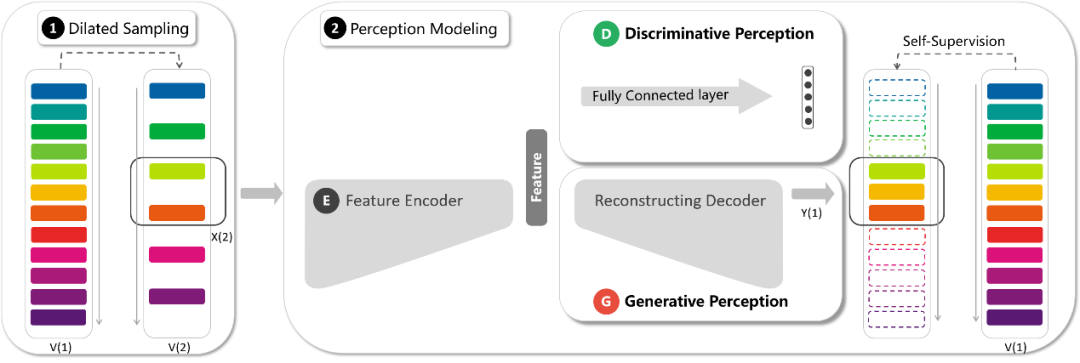
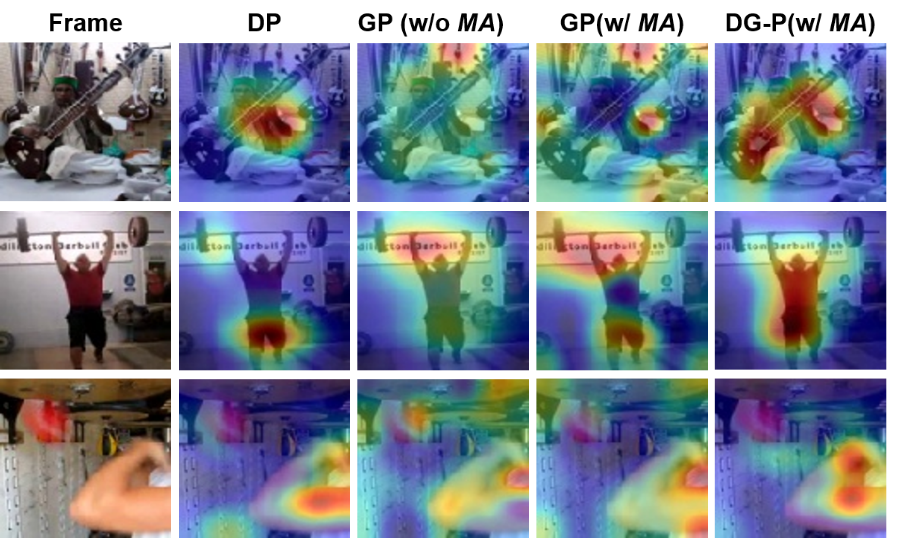
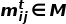 来促进网络更注重对特定区域(前景运动区域)的重构。该权值形成的运动激活图
来促进网络更注重对特定区域(前景运动区域)的重构。该权值形成的运动激活图
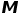 通过图3所示的几个步骤简单得到。其中包括:帧差(提取运动信息),下采样(抑制噪声),激活(稳定响应值),上采样(恢复到重构视频大小)。
通过图3所示的几个步骤简单得到。其中包括:帧差(提取运动信息),下采样(抑制噪声),激活(稳定响应值),上采样(恢复到重构视频大小)。
 计算过程
计算过程
叶齐祥:国科大教授,博士生导师,主要研究方向视觉目标感知、弱监督视觉建模、深度特征学习。

登录查看更多
相关内容
专知会员服务
36+阅读 · 2020年3月12日
专知会员服务
87+阅读 · 2020年3月1日
Arxiv
9+阅读 · 2018年8月30日



相关VIP内容
专知会员服务
36+阅读 · 2020年3月12日
专知会员服务
87+阅读 · 2020年3月1日
相关资讯
相关论文
Arxiv
9+阅读 · 2018年8月30日