ResNet架构可逆!多大等提出性能优越的可逆残差网络
选自arXiv
作者:Jens Behrmann、Will Grathwohl、
Ricky T. Q. Chen等
机器之心编译
近日,来自德国不来梅大学和加拿大多伦多大学的研究者提出一种新架构——可逆残差网络,可用于分类、密度估计和生成任务。而在此之前,单个架构无法在判别和生成任务上同时取得优秀性能。值得一提的是,NeurIPS 2018 最佳论文获得者 David Duvenaud 、陈天琦也是本文作者。
神经网络模型的一个主要诉求是用单个模型架构解决各种相关任务。然而,最近的许多进展都是针对特定领域量身定制的特定解决方案。例如,无监督学习中的当前最佳架构正变得越来越具有领域特定性 (Van Den Oord et al., 2016b; Kingma & Dhariwal, 2018; Parmar et al., 2018; Karras et al., 2018; Van Den Oord et al., 2016a)。另一方面,用于判别学习的最成功的前馈架构之一是深度残差网络 (He et al., 2016; Zagoruyko & Komodakis, 2016),该架构与对应的生成模型有很大不同。这种划分使得为给定任务选择或设计合适架构变得复杂。本研究提出一种在这两个领域都表现良好的新架构,弥补了这一差距。
为此,研究者将精力集中于可逆网络,在相同的模型范例中,可逆网络已被证明在判别 (Gomez et al., 2017; Jacobsen et al., 2018) 和生成 (Dinh et al., 2014; 2017; Kingma & Dhariwal, 2018) 任务上都具有竞争性的表现。已有的可逆网络通常依赖对固定维度进行分割的启发式法,而体积不守恒(non-volume conserving)的常见分割法受到了限制,且其选择对网络的性能又有极大的影响 (Kingma & Dhariwal, 2018; Dinh et al., 2017)。这使得构建可逆网络很困难。在本文中,研究者展示了一些有助于实现优秀密度估计性能的外来设计会严重损害判别性能。
为了克服这一问题,研究者利用 ResNet 作为常微分方程的 Euler 离散化,并证明通过简单地改变标准 ResNet 的归一化机制就可以构建可逆 ResNet。图 1 可视化了标准和可逆 ResNet 学习到的动态差异。
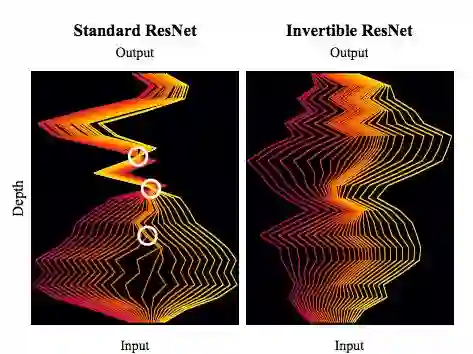
图 1:标准残差网络(左)和可逆残差网络(右)的动态。可逆 ResNet 描述了双射连续动态(bijective continuous dynamics),而常规 ResNet 导致与非双射连续动态相对应的交叉和折叠路径(白色圈)。由于折叠路径,标准 ResNet 不是有效的密度模型。
这种方法允许每个残差块的无约束架构,而每个块只需要小于 1 的 Lipschitz 常数。研究者证明,在构建图像分类器时,这种限制对性能的影响可以忽略不计——在对 MNIST、CIFAR10 和 CIFAR100 图像进行分类时,它们的性能与不可逆的同类分类器相当。
接下来,研究者展示了如何将 i-ResNet 训练成无标注数据上的最大似然生成模型。为了计算似然度,他们向残差模块的雅可比行列式引入了一个易处理的近似。与 FFJORD(Grathwohl et al., 2019)类似,i-ResNet flow 拥有不受约束(自由形式)的雅可比行列式,这使得它们能够学习比其他可逆模型使用的三角形映射更具表达性的变换。实验表明,与当前最佳的图像分类器和基于流的生成模型相比,i-ResNets 的性能也具有竞争力,它将通用架构在现实中的应用又推进了一步。
论文:Invertible Residual Networks

论文链接:https://arxiv.org/pdf/1811.00995.pdf
摘要:本研究证明,标准 ResNet 架构可以是可逆的,且可用于分类、密度估计和生成任务。通常,执行可逆需要分割维度或限制网络架构。但本研究提出的方法只需要在训练期间添加一个简单的归一化步骤,这在标准框架中已经可以做到。可逆 ResNets 定义了一个可使用最大似然在无标注数据上训练的生成模型。为了计算似然度,我们对残差块的雅可比对数行列式引入易处理的近似。实验结果表明,可逆 ResNet 的性能堪比当前最优的图像分类器和基于流的生成模型,而单个架构在这之前是无法做到的。
2. 在 ResNet 中执行可逆性
以下定理表明,一个简单的条件就足以使上述动态过程可解,从而使 ResNet 可逆:

注意,这一条件不是可逆性的必要条件。
使用 Lip(g) < 1 可使 ResNet 可逆,但我们没有这种可逆的解析形式,不过我们可以通过一个简单的定点迭代来获得,见算法 1。

3. 使用 i-ResNet 进行生成建模
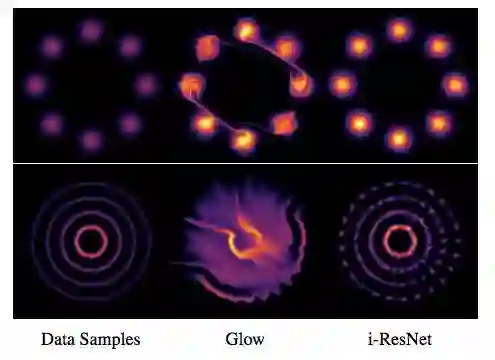
图 2:i-ResNet 流和 Glow 的可视化比较。




表 1:i-ResNet、ResNet 与 NICE (Dinh et al., 2014)、Real-NVP (Dinh et al., 2017)、Glow (Kingma & Dhariwal, 2018) 及 FFJORD (Grathwohl et al., 2019) 的对比结果。「Non-volume Preserving」指允许收缩和扩张的能力,以及计算变量 (3) 变化的确切似然。「Unbiased Estimator」是指对数行列式的随机近似。
5. 实验
研究者对可逆 ResNet 进行了大量实验研究。首先,研究者用数值方法验证了 i-ResNets 的可逆性。接下来,他们研究了 i-ResNet 在多个常用图像分类数据集上的判别能力。另外,他们还将 i-ResNet 的判别性能与其他可逆网络进行了对比。最后,他们研究了如何将 i-ResNet 用于定义生成模型。
5.1 验证可逆性和分类性能

图 3:原始图像(上)、i-ResNet 在 c = 0.9 时的重建结果(中)以及相同架构的标准 ResNet 的重建结果(下)。该图表明固定点迭代在没有 Lipschitz 约束的情况下无法重建输入图像。

表 2:i-ResNet 与类似深度和宽度的 ResNet-164 基线架构的对比结果,其中 Lipschitz 约束通过系数 c 来变化。Vanilla 与 i-ResNet 架构相同,但是它不具备 Lipschitz 约束。
5.2 i-ResNet 与其他可逆架构的对比

表 3:i-ResNet 与最新技术 Glow 在 CIFAR10 数据集上的分类结果。这里对比了两个版本的 Glow 和与 Glow 层数、通道数都类似的 i-ResNet 架构(i-ResNet, Glow-Style)。
5.3 生成建模
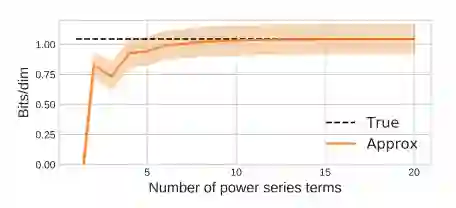
图 4:本文提出的对数行列式估计量的偏差和标准差随幂级数项数量增加而发生的变化。方差是由随机 trace estimator 决定的。

图 5:i-ResNet flow 中的 CIFAR10 样本。
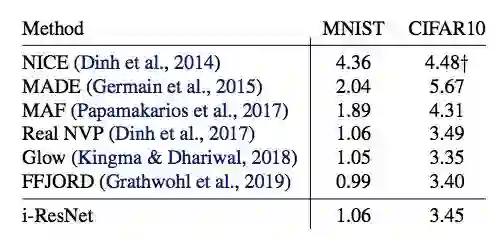
表 4:多种方法在 MNIST 和 CIFAR10 数据集上的 bits/dim 结果。† 使用 ZCA 预处理,因此其结果无法与其他方法直接对比。

本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com

