学界 | UC Berkeley提出新型分布式框架Ray:实时动态学习的开端
选自arXiv
机器之心编译
参与:路雪、刘晓坤
为应对新型 AI 应用不断提高的性能需求,近日 Michael Jordan 等人提出了一个新型的分布式框架 Ray,主要针对当前集群计算框架无法满足高吞吐量和低延迟需求的问题,以及很多模拟框架局限于静态计算图的缺点,并指出强化学习范式可以自然地结合该框架。
人工智能在一些现实世界应用中正逐渐发展为主力技术。然而,到目前为止,这些应用大部分都是基于相当受限的监督学习范式,其中模型是离线学习的,然后提供在线预测。随着人工智能领域的成熟,使用比标准的监督学习设置更宽泛的设置成为必需。和仅仅做出并提供单个预测不同,机器学习应用必须越来越多地在动态环境中运行,对环境变化做出反应,执行一系列动作以达到目标。这些更加宽泛的需求实际上可以自然地在强化学习(RL)的范式内构造,强化学习可以在不确定的环境中持续学习。一些基于 RL 的应用已经达到了引人注目的结果,例如谷歌的 AlphaGo 打败围棋人类世界冠军,这些应用也正在探索自动驾驶汽车、UAV 和自动化操作领域。
把 RL 应用和传统的监督学习应用区分开来的特征有三个。首先,RL 通常高度依赖模拟来探索状态、发现动作的后果。模拟器可以编码计算机游戏的规则、物理系统的牛顿动力学(如机器人),或虚拟环境的混合动力学。这通常需要消耗大量的算力,例如构建一个现实的应用可能需要经过几亿次模拟。其次,RL 应用的计算图是异质、动态演化的。一次模拟可能需要几毫秒到几分钟不等,并且模拟的结果还会影响未来模拟中使用的参数。最后,很多 RL 应用,如机器人控制或自动驾驶,需要快速采取行动以应对不断变化的环境。此外,为了选择最优动作,这些应用需要实时地执行更多的模拟。总之,我们需要一个支持异质和动态计算图的计算框架,同时可以在毫秒延迟下每秒执行百万量级的任务。
已有的集群计算框架并不能充分地满足这些需求。MapReduce [18]、Apache Spark [50]、Dryad [25]、Dask [38] 和 CIEL [32] 不支持通用 RL 应用的高吞吐量和低延迟需求,而 TensorFlow [5]、Naiad [31]、MPI [21] 和 Canary [37] 通常假定计算图是静态的。
这篇论文做出了如下贡献:
指出了新兴 AI 应用的系统需求:支持(a)异质、并行计算,(b)动态任务图,(c)高吞吐量和低延迟的调度,以及(d)透明的容错性。
除了任务并行的编程抽象之外,还提供了 actor 抽象(基于动态任务图计算模型)。
提出了一个可水平伸缩的架构以满足以上需求,并建立了实现该架构的集群计算系统 Ray。
论文:Ray: A Distributed Framework for Emerging AI Applications

论文地址:https://arxiv.org/abs/1712.05889
下一代的 AI 应用将具备持续和环境进行交互以及在交互中学习的能力。这些应用对系统有新的高要求(无论是性能还是灵活性)。在这篇论文中,我们考虑了这些需求并提出了 Ray,一个满足上述需求的分布式系统。Ray 实现了一个动态任务图计算模型(dynamic task graph computation model),该模型支持任务并行化和 actor 编程模型。为了满足 AI 应用的性能需求,我们提出了一个架构,该架构使用共享存储系统(sharded storage system)和新型自下而上的分布式调度程序实现系统控制状态的逻辑集中。我们的实验展示了亚毫秒级的远程任务延迟,以及每秒可扩展至超过 180 万任务的线性吞吐量。实验证明 Ray 可以加速难度高的基准测试,而且是新兴强化学习应用和算法的自然、高效选择。
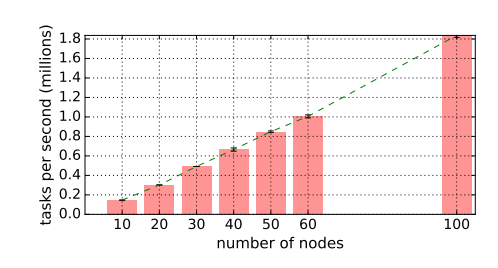
图 7:该系统利用 GCS 和自下而上的分布式调度程序,以线性方式实现的端到端可扩展性。Ray 用 60 个 m4.16xlarge 节点可以达到每秒 100 万任务的吞吐量,在 1 分钟内处理 1 亿任务。鉴于代价,我们忽略 x ∈ {70,80,90}。
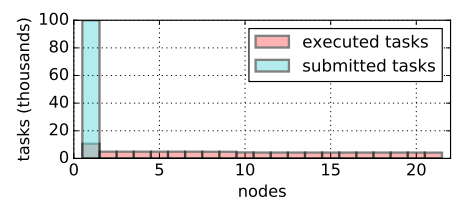
图 8:Ray 保持平衡负载。第一个节点的驱动程序提交 10 万个任务,全局调度程序在 21 个可用节点中平衡这些任务。
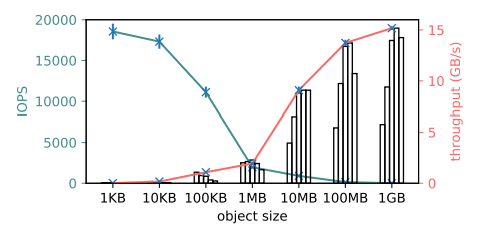
图 9:对象存储写入的吞吐量和输出操作(IOPS)。对于单个客户端,在 16 核实例(m4.4xlarge)上大型对象的吞吐量超过 15GB/s(红色),小型对象的吞吐量超过 18K IOPS(蓝绿色)。它使用 8 个线程复制超过 0.5MB 的对象,用 1 个线程复制其他小型对象。条形图代表 1、2、4、8、16 个线程的吞吐量。以上结果是 5 次运行的平均值。
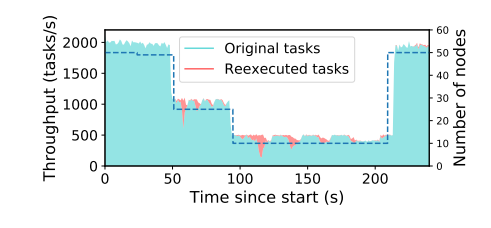
图 10:分布式任务的全透明容错性。虚线代表集群中节点的数量。曲线表示新任务(蓝绿色)和重新执行的任务(红色)的吞吐量。驱动程序持续提交和检索 10000 个任务。每个任务耗时 100ms,依赖于前一个回合的一个任务。每个任务的输入和输出大小为 100KB。
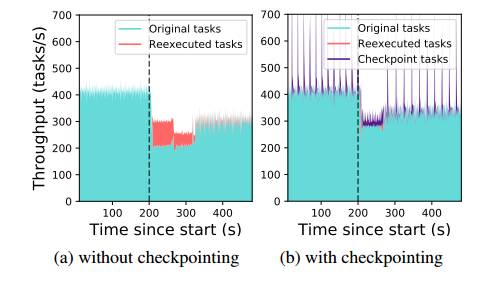
图 11:actor 方法的全透明容错性。驱动程序持续向集群中的 actor 提交任务。在 t = 200s 时,我们删除了 10 个节点中的 2 个,使集群的 2000 个 actor 中的 400 个在剩余节点中恢复。
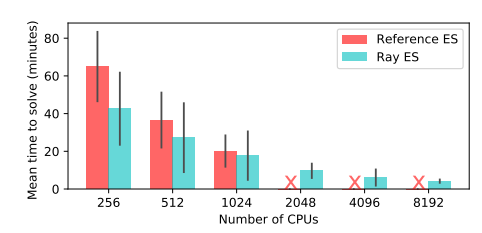
图 12:Reference ES 和 Ray ES 系统在 Humanoid-v1 任务中得到 6000 分的时间 [13]。Ray ES 实现可以扩展到 8192 个核。而 Reference ES 系统无法运行超过 1024 个核。我们使用 8192 个核获得了 3.7 分钟的中位耗时,比之前公布的最佳结果快一倍。在此基准上,ES 比 PPO 快,但是运行时间方差较大。
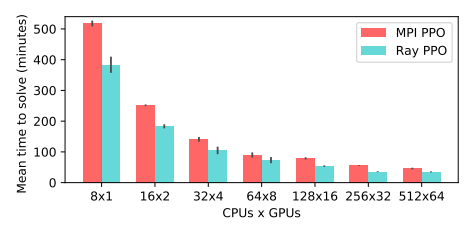
图 13:MPI PPO 和 Ray PPO 在 Humanoid-v1 任务中得到 6000 分的时间 [13]。Ray PPO 实现优于专用的 MPI 实现 [3],前者使用的 GPU 更少,代价也只是后者的一小部分。MPI 实现中每 8 个 CPU 就需要 1 个 GPU,而 Ray 至多需要 8 个 GPU,每 8 个 CPU 所需的 GPU 不超过 1 个。

表 3:低延迟机器人模拟结果

本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com
点击「阅读原文」,在 PaperWeekly 参与对此论文的讨论。
