用 CNN 分 100,000 类图像

本文作者郑哲东,原载于知乎专栏(http://suo.im/1cHlTJ )。
[Title]:Dual-Path Convolutional Image-Text Embedding
[arXiv]:http://cn.arxiv.org/abs/1711.05535
[Code]:layumi/Image-Text-Embedding(http://suo.im/uGOPg )
Motivation
在这篇文章中我们尝试了 用 CNN 分类 113,287 类图像 (MSCOCO)。
实际上我们将每张训练集中的图像认为成一类。(当然, 如果只用一张图像一类,CNN 肯定会过拟合)。同时,我们利用了 5 句图像描述 (文本),加入了训练。所以每一类相当于 有 6 个样本 (1 张图像 + 5 句描述)。
文章想解决的问题是 instance-level 的 retrieval,也就是说 如果你在 5000 张图的 image pool 中,要找 “一个穿蓝色衣服的金发女郎在打车。” 实际上你只有一个正确答案。不像 class-level 或 category-level 的 要找 “女性 “可能有很多个正确答案。所以这个问题更细粒度,也更需要 detail 的视觉和文本特征。

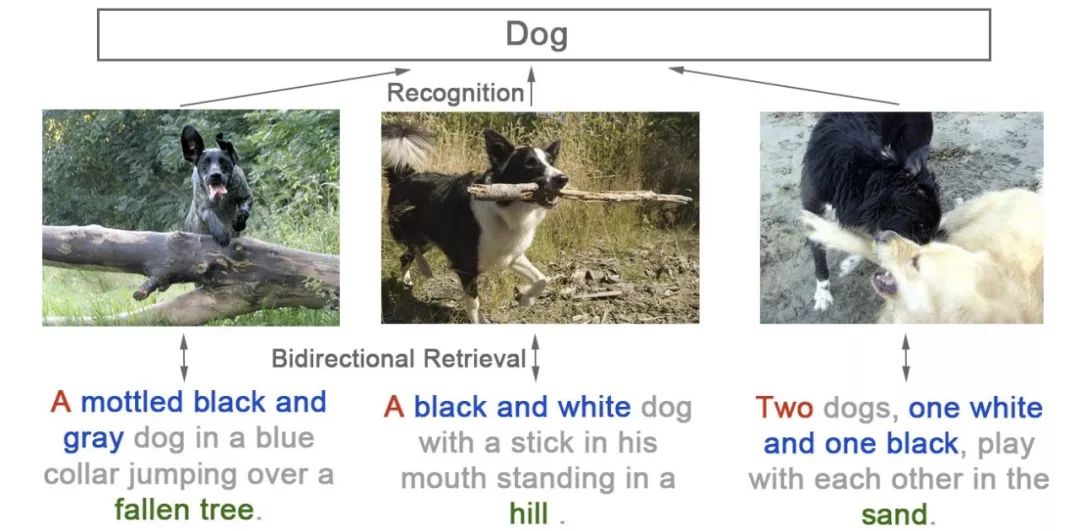
同时我们又观察到好多之前的工作都直接使用 class-level 的 ImageNet pretrained 网络。但这些网络实际上损失了信息(数量 / 颜色 / 位置)。以下三张图在 imagenet 中可能都会使用 Dog 的标签,而事实上我们可以用自然语言给出更精准的描述。也就是我们这篇论文所要解决的问题(instance-level 的图文互搜)。
Method
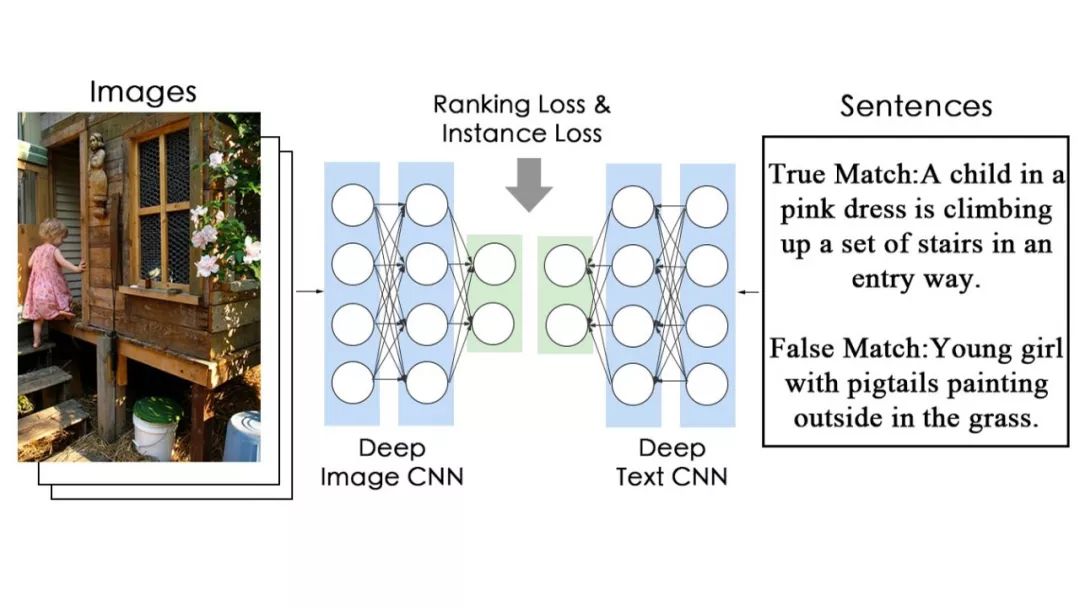
1. 对于自然语言描述,我们采用了相对不那么常用的 CNN 结构,而不是 LSTM 结构。
来并行训练,finetune 整个网络。结构如图。结构其实很简单。
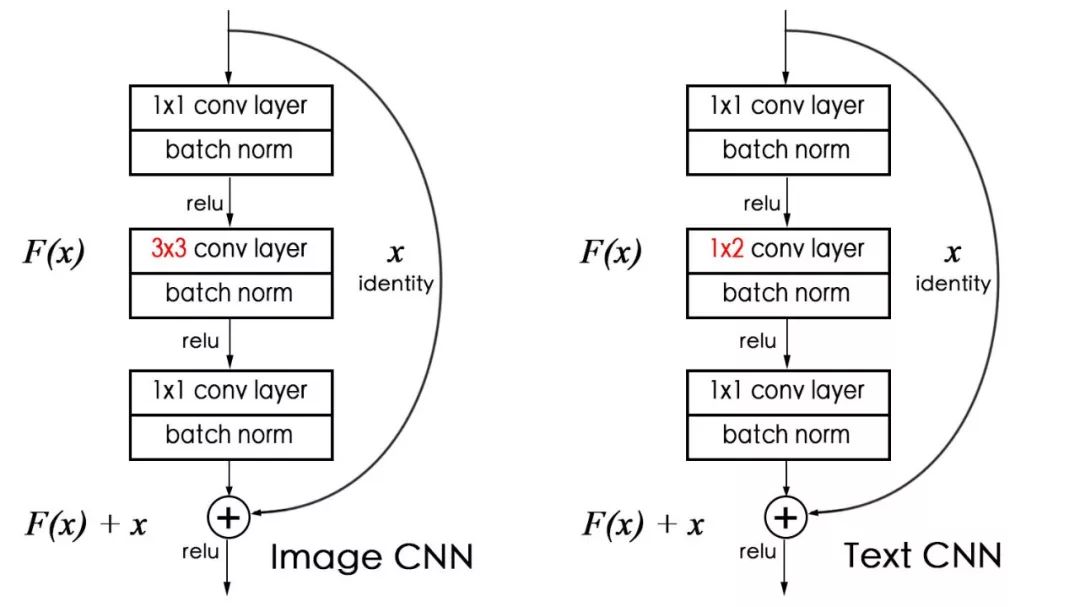
对于 TextCNN,我们是用了类似 ResNet 的 block。注意到句子是一维的,在实际使用中,我们用的是 1X2 的 conv。
2. Instance loss。
我们注意到,最终的目的是让每一个图像都有区分 (discriminative) 的特征,自然语言描述也是。所以,为什么不尝试把每一张图像看成一类呢。(注意这个假设是无监督的,不需要任何标注。)
这种少样本的分类其实在之前做行人重识别就常用,但行人重识别(1467 类,每类 9.6 张图像,有人为 ID 的标注。)没有像我们这么极端。
Flickr30k:31,783 类 (1 图像 + 5 描述), 其中训练图像为 29,783 类
MSCOCO:123,287 类 (1 图像 + ~5 描述), 其中训练图像为 113,287 类

注意到 Flickr30k 中其实有挺多挺像的狗的图像。
不过我们仍旧将他们处理为不同的类,希望也能学到细粒度的差别。
(而对于 CUHK-PEDES,因为同一个人的描述都差不多。我们用的是同一个人看作一个类,所以每一类训练图片多一些。CUHK-PEDES 用了 ID annotation,而 MSCOCO 和 Flickr30k 我们是没有用的。)
3. 如何结合 文本和图像一起训练?
其实,文本和图像很容易各学各的,来做分类。所以我们需要一个限制,让他们映射到同一个高层语义空间。
我们采用了一个简单的方法:在最后分类 fc 前,让文本和图像使用一个 W,那么在 update 过程中会用一个软的约束,这就完成了(详见论文 4.2)。 在实验中我们发现光用这个 W 软约束,结果就很好了。(见论文中 StageI 的结果)
4. 训练收敛么?
收敛的。欢迎大家看代码。就是直接 softmax loss,没有 trick。
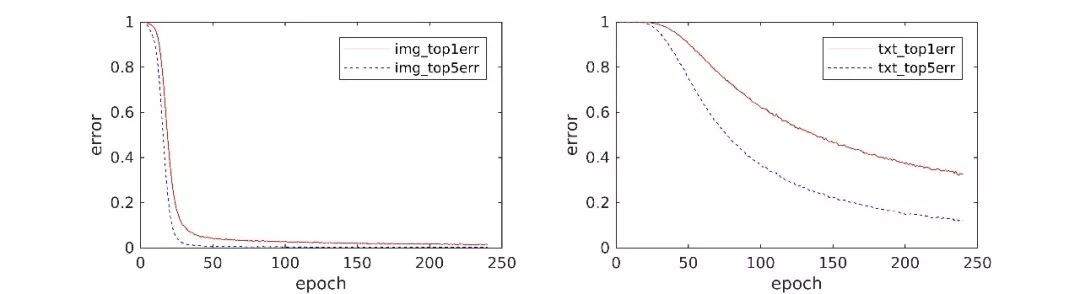
图像分类收敛的快一些。文本慢一些。在 Flickr30k 上,ImageCNN 收敛的快,
TextCNN 是重新开始学的,同时是 5 个训练样本,所以相对慢一些。
5. instance loss 是无监督的么?
instance loss 的假设是无监督的,因为我们没有用到额外的信息 (类别标注等等)。而是用了 “每张图就是一类” 这种信息。
6. 使用其他无监督方法,比如 kmeans 先聚类,能不能达到类似 instance loss 的结果?
我们尝试使用预训练 ResNet50 提取 pool5 特征,分别聚了 3000 和 10000 个类。
(聚类很慢,虽然开了多线程,聚 10000 个类花了 1 个多小时,当中还怕内存不足,死机。大家请慎重。)
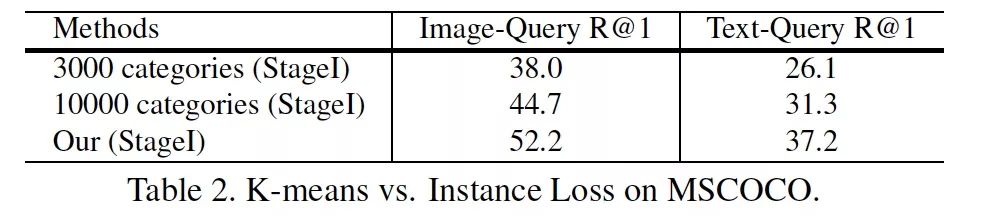
在 MSCOCO 采用 instance loss 的结果更好一些。我们认为聚类其实没有解决,黑狗 / 灰狗 / 两条狗都是 狗,可能会忽略图像细节的问题。
7. 比结果的时候比较难。
因为大家的网络都不太相同(不公平),甚至 train/test 划分也不同(很多之前的论文都不注明,直接拿来比)。
所以在做表格的时候,我们尽量将所有方法都列了出来。注明不同 split。
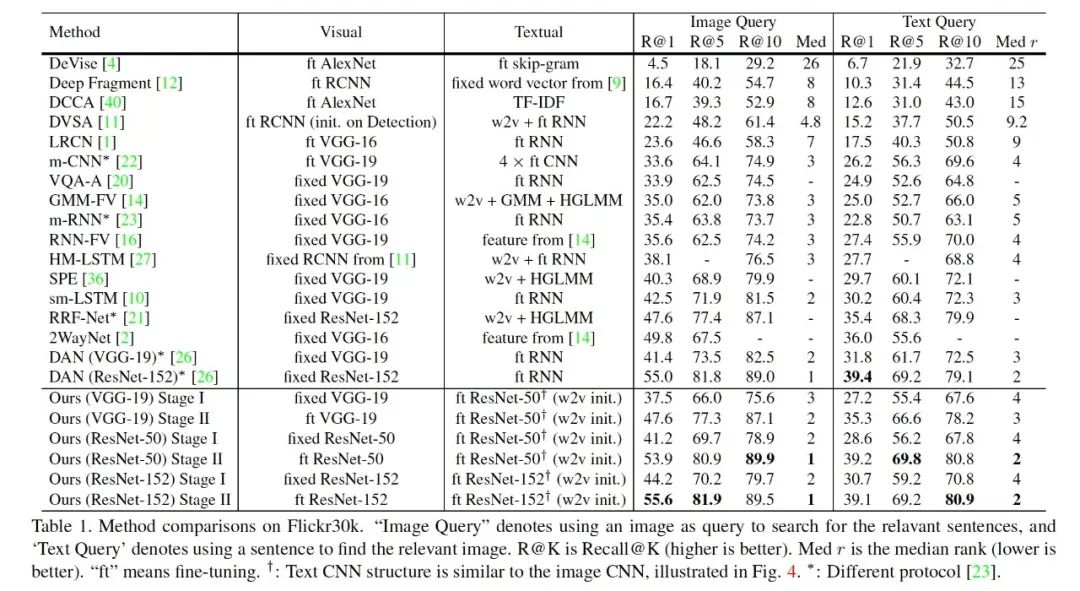
尽量 VGG-19 和 VGG-19 来比, ResNet-152 和 ResNet-152 比。欢迎大家详见论文。
和我们这篇论文相关的,很多是鲁老师的工作,真的推荐大家去看。
Multimodal convolutional neural networks for matching image and sentence(http://suo.im/1OSnaO )
Convolutional Neural Network Architectures for Matching Natural Language Sentences(http://suo.im/RfcoU )
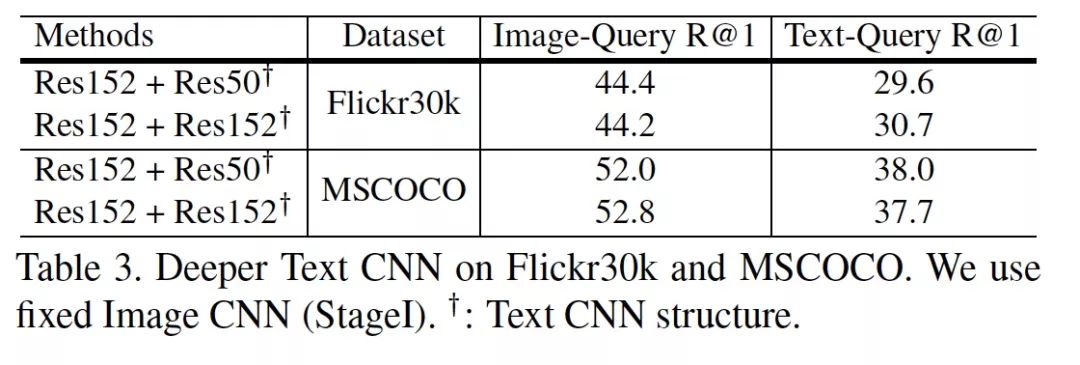
8. 更深的 TextCNN 一定更好么?
这个问题是 Reviewer 提出的。
相关论文是 Do Convolutional Networks need to be Deep for Text Classification ?
确实,在我们额外的实验中也发现了这一点。在两个较大的数据集上,将文本那一路的 Res50 提升到 Res152 并没有显著提升。
9. 一些 trick(在其他任务可能不 work)
因为看过 bidirectional LSTM 一个自然的想法就是 bidirectional CNN,我自己尝试了,发现不 work。插曲:当时在 ICML 上遇到 fb CNN 翻译的 poster,问了,他们说,当然可以用啊,只是他们也没有试之类的。
本文中使用的 Position Shift 就是把 CNN 输入的文本,随机前面空几个位置。类似图像 jitter 的操作吧。还是有明显提升的。详见论文。
比较靠谱的数据增强 可能是用同义词替换句子中一些词。虽然当时下载了 libre office 的词库,但是最后还是没有用。最后采用的是 word2vec 来初始化 CNN 的第一个 conv 层。某种程度上也含有了近义词的效果。(相近词,word vector 也相近)
可能数据集中每一类的样本比较均衡(基本都是 1+5 个),也是一个我们效果好的原因。不容易过拟合一些 “人多” 的类。
Results
TextCNN 有没有学出不同词,不同的重要程度?(文章附录)
我们尝试了从句子中移除一些词,看移除哪些对匹配 score 影响最大。

一些图文互搜结果(文章附录)
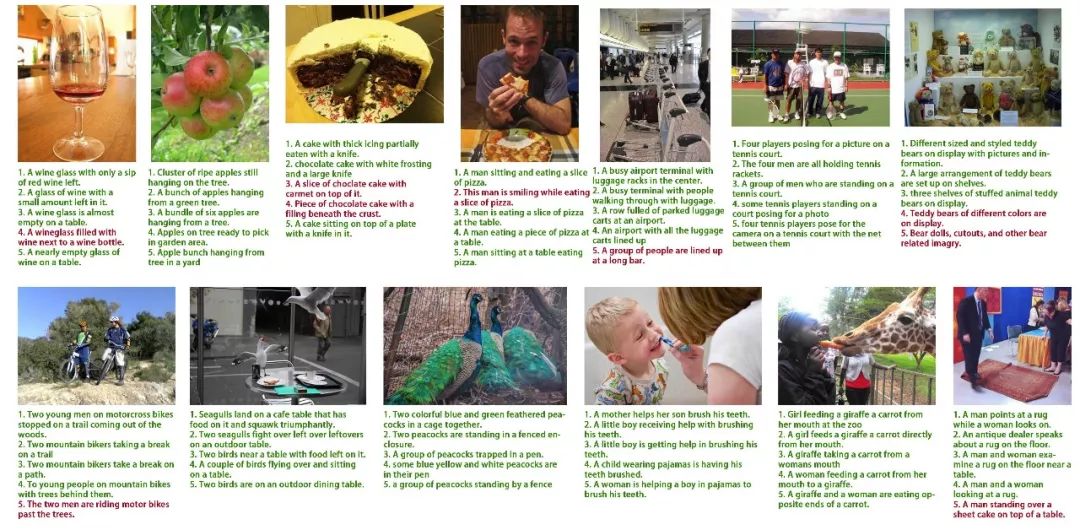

自然语言找行人

细粒度的结果

论文中可能细节说得还不是很清楚,欢迎看代码 / 交流。

NLP 工程师入门实践班
三大模块,五大应用,知识点全覆盖;
海外博士讲师,丰富项目分享经验;
理论 + 实践,带你实战典型行业应用;
专业答疑社群,结交志同道合伙伴。
▼▼▼

新人福利
关注 AI 研习社(okweiwu),回复 1 领取
【超过 1000G 神经网络 / AI / 大数据,教程,论文】
CNN 中千奇百怪的卷积方式大汇总
▼▼▼




