CNN图像风格迁移的原理及TensorFlow实现

向AI转型的程序员都关注了这个号👇👇👇
大数据挖掘DT数据分析 公众号: datadw
本文全部代码 地址
在公众号 datadw 里 回复 风格迁移 即可获取。
图像风格迁移最近两年比较火,看起来也比较有趣,所以这两天闲暇时候看了一些文章了解了下其中的原理,特来分享,如果你也对图像风格迁移感兴趣,不妨来看一看这篇文章。
本篇博文要介绍的是2016年的CVPR论文,该文章用CNN网络来做图像风格迁移。
“ Image Style Transfer Using Convolutional Neural Networks”
论文地址
http://www.cv-foundation.org/openaccess/content_cvpr_2016/papers/Gatys_Image_Style_Transfer_CVPR_2016_paper.pdf
在开始介绍文章算法之前,先看看什么是图像风格迁移?如下图:A是待转换的图像,小的矩形图像是风格图像,B是转换后的图像。

因此要完成图像的风格转换,需要输入一张待转换的图像和一张风格图像,在文中这两张图像在提取特征之前都会resize到相同的尺寸。另外文章的CNN主网络采用的是19层的VGG。接下来详细介绍本文的算法。

Fgiure1介绍了后面要用到的一个很重要的观点(主要根据Figure1最下面的content reconstructions 结果):网络的高层特征一般是关于输入图像的物体和布局等信息,低层特征一般表达输入图像的像素信息。也就是说在提取content特征时,不同层的表达效果是不一样的,本文在后面提取图像的content特征时采用高层特征。另一个点,从Figure1最上面的style reconstructions可以看出,不同层的特征表达有不同的视觉效果,因此在后面提取style feature map的时候采用的是多层特征的融合,这样风格表达会更加丰富。

Figure5表示对于提取图像的content信息时采用高层或低层特征的效果对比。可以看出从Conv2_2提取的特征会更多地保留原图的细节信息。

Figure2是本文算法的核心。先大概讲一下Figure2中最上面的右边的公式是网络训练的总的loss,这个loss包含congtent和style两部分,且都有系数来控制权重,接下来会详细介绍这个loss是怎么计算得到的。
这里我为了书写方便用a表示Figure2中的a箭头,p表示p箭头,x表示x箭头。Figure2的左边,a表示风格图像(style image),a作为VGG网络的输入,这样VGG的每个卷积层都可以得到很多feature map,用Al表示,l表示层,因为输入是风格图像,所以这些Al可以称为style representation。这里每一层的特征Al都将被保存下来,可以看Figure2左边每个卷积层的右边都有一个箭头指向生成的feature map。Figure2的右边,p表示输入的待转换的图像(content image),同样作为VGG网络的输入,经过多个卷积和pool层,每层都会生成很多feature map,用Pl表示,并称之为content representation。这里只保存conv4层的feature map,可以看Figure2右边的conv4层的左边有一个箭头指向生成的feature map。至于为什么要采用高层信息,前面在介绍Figure1的时候已经解释了。Figure2的中间,x表示生成的随机白噪声图像,同样作为VGG网络的输入,这样每个卷积层都可以计算出style features Gl和content fetures Fl。这里的content features FI是每个卷积层的feature map,style features Gl是根据Fl利用Gram矩阵计算得到的,具体公式如下:

这里的l表示层,i和j表示该层的第i个feature map和第j个feature map,k表示feature map的第k个元素,因此这个公式就是对两个feature map求内积。为什么会引入Gram矩阵呢?其实就是为了表达图像的纹理特征(content representation)。有一种说法是图像的纹理特征和位置是没有关系的,Gram矩阵这种求两个feature map内积的结果也是和位置没有关系的,因此可以用来度量纹理特征。后来看的一些图像风格迁移的文章也挺多是对如何描述纹理相似方面入手。
前面说过总的loss包含content的loss和style的loss。style的loss的计算公式如下图:

其中El的公式如下:
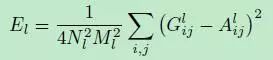
style的loss是这样计算的:x的每一层的Gl都会和a的每一层的Al一起计算均方差EL,然后由这个EL根据权重w计算得到Lstyle(如Figure2最下面的左边公式),权重w用来表达各层特征的重要性,这个损失就是用来描述风格的差异。
content的loss的计算公式如下图:

content的loss是这样计算的:x的conv4层的Fl和p的conv4的Pl计算均方差Lcontent,就是content的loss。
Figure2的最下面是关于x的更新公式,其实就是对总的loss求导,然后乘以步长,得到的就是更新的大小。因此x就不断在Figure2的中间这个网络中循环更新,直到达到好的效果。

Figure6是关于初始化的比较。在文中(Figure2)是采用随机生成一个白噪声图像来初始化的,在文中作者也对比了其他初始化方法,比如用style image初始化或用content image进行初始化。结果表明不同的初始化方式对最终的结果没有太大的影响。每次随机初始化都会生成不同的结果,如Figure6中的C有4张。但是用style image或content image初始化生成的结果是固定的。
总结:
这篇文章介绍了用CNN网络做图像风格转换,将图像风格转换变成基于CNN网络寻找最优的content和style匹配问题。文章的一个关键点就是在一个CNN网络中将content representation和style representation很好地区分开。这篇文章提出了用Gram矩阵来描述图像的纹理,但是对于为什么Gram矩阵可以描述图像纹理并没有详细说明。总的来说这个算法比较有历史意义,后续有不少改进算法是基于这个算法的。
我们主要介绍基于TensorFlow的程序实现,为了实现以下程序,你需要安装 TensorFlow, Numpy, Scipy, 以及下载 VGG-19 model。
我们设置了一个 image resize 函数,这样可以处理任意size的 input image,而且我们尝试利用 L-BFGS 优化算法替代之前的 Adam 优化算法,对卷积层以及pooling层函数做了修改。
本文全部代码 地址
在公众号 datadw 里 回复 风格迁移 即可获取。
算法结果展示:





人工智能大数据与深度学习
搜索添加微信公众号:weic2c

长按图片,识别二维码,点关注
大数据挖掘DT数据分析
搜索添加微信公众号:datadw
教你机器学习,教你数据挖掘

长按图片,识别二维码,点关注

