学界 | Fashion-MNIST:替代MNIST手写数字集的图像数据集
机器之心转载
公众号:PaperWeekly
作者:肖涵
FashionMNIST 是一个替代 MNIST 手写数字集 [1] 的图像数据集。 它是由 Zalando(一家德国的时尚科技公司)旗下的研究部门提供。其涵盖了来自 10 种类别的共 7 万个不同商品的正面图片。
FashionMNIST 的大小、格式和训练集 / 测试集划分与原始的 MNIST 完全一致。60000/10000 的训练测试数据划分,28x28 的灰度图片。你可以直接用它来测试你的机器学习和深度学习算法性能,且不需要改动任何的代码。
这个数据集的样子大致如下(每个类别占三行):


1. 为什么要做这个数据集?
经典的 MNIST 数据集 [1] 包含了大量的手写数字。十几年来,来自机器学习、机器视觉、人工智能、深度学习领域的研究员们把这个数据集作为衡量算法的基准之一。你会在很多的会议,期刊的论文中发现这个数据集的身影。实际上,MNIST 数据集已经成为算法作者的必测的数据集之一。有人曾调侃道:"如果一个算法在 MNIST 不 work,那么它就根本没法用;而如果它在 MNIST 上 work,它在其他数据上也可能不 work"。
Fashion-MNIST 的目的是要成为 MNIST 数据集的一个直接替代品。作为算法作者,你不需要修改任何的代码,就可以直接使用这个数据集。Fashion-MNIST 的图片大小,训练、测试样本数及类别数与经典 MNIST 完全相同。
写给专业的机器学习研究者
我们是认真的。取代 MNIST 数据集的原因由如下几个:
MNIST 太简单了,很多算法在测试集上的性能已经达到 99.6%!不妨看看我们基于 scikit-learn 上的评测 [2] 和这段代码 [3]。大多数 MNIST 只需要一个像素就可以区分开;
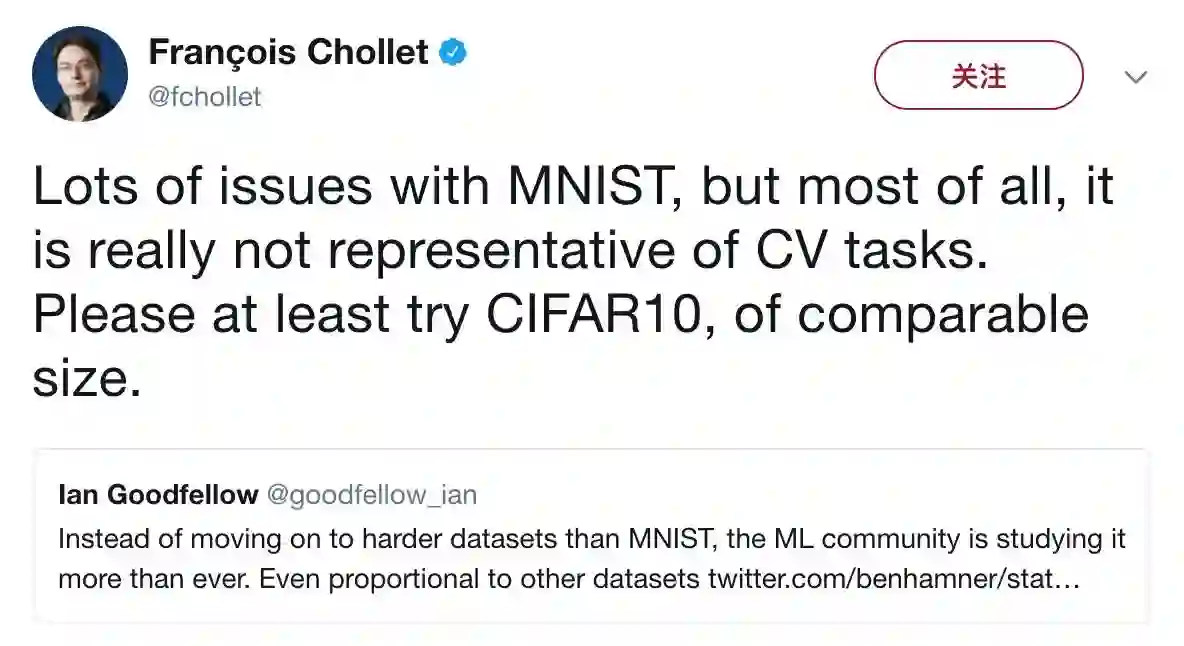
MNIST 被用烂了。参考下图,Ian Goodfellow 希望人们不要再用 MNIST 了;

MNIST 数字识别的任务不代表现代机器学习。如下图,在 MNIST 上的想法没法迁移到真正的机器视觉问题上。
2. 获取数据
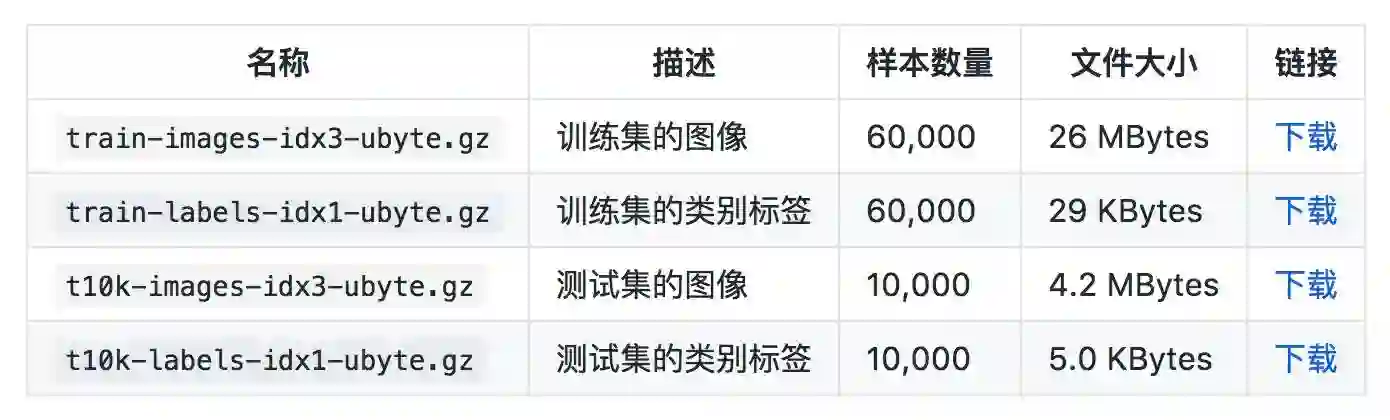
你可以使用以下链接下载这个数据集。Fashion-MNIST 的数据集的存储方式和命名与经典 MNIST 数据集 [1] 完全一致。
点击「阅读原文」获取下载链接
或者,你可以直接克隆这个代码库。数据集就放在 data/fashion 下。这个代码库还包含了一些用于评测和可视化的脚本。

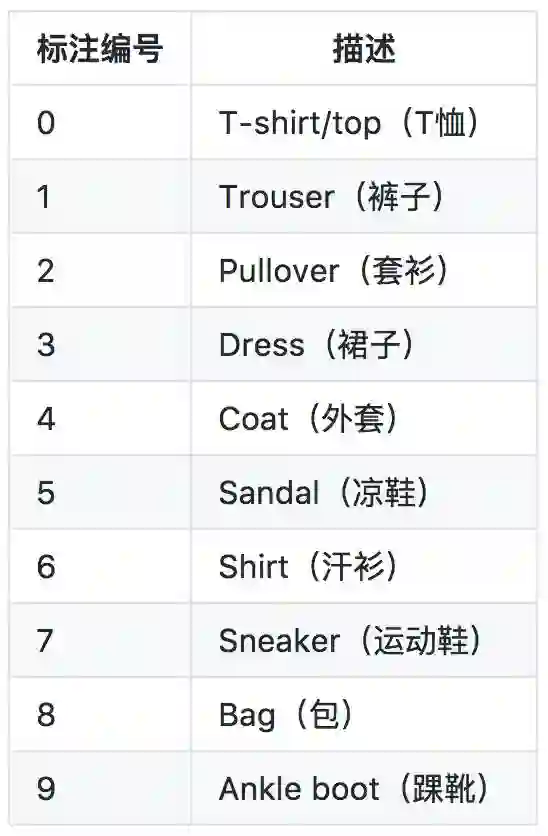
类别标注
每个训练和测试样本都按照以下类别进行了标注:
3. 如何载入数据?
使用 Python(需要安装 NumPy)
你可以直接使用 utils/mnist_reader:

使用 Tensorflow

使用其他的语言
作为机器学习领域里最常使用的数据集,人们用各种语言为 MNIST 开发了很多载入工具。有一些方法需要先解压数据文件。注意,我们并没有测试过所有的载入方法,载入方法获取方式详见文末。
C
C++
Java
Python
Scala
Go
C#
NodeJS
Swift
R
Matlab
Ruby
4. 评测
我们使用 scikit-learn 做了一套自动评测系统。它涵盖了除深度学习之外的 125 种经典机器学习模型(包含不同的参数)。你可以在这里以互动的方式查看结果 [2]。
你可以运行 benchmark/runner.py 对结果进行重现。而我们更推荐的方法是使用 Dockerfile 打包部署后以 Container 的方式运行。
我们欢迎你提交自己的模型评测,请使用 Github 新建一个 Issue。如果你提交自己的模型,请先确保这个模型没有在这个列表 [2] 中被测试过。

5. 数据可视化
t-SNE 在 Fashion-MNIST(左侧)和经典 MNIST 上的可视化(右侧)

PCA 在 Fashion-MNIST(左侧)和经典 MNIST 上的可视化(右侧)

6. 在论文中引用 Fashion-MNIST
如果你在你的研究工作中使用了这个数据集,欢迎你引用这篇论文:
Fashion-MNIST: a Novel Image Dataset for Benchmarking Machine Learning Algorithms. Han Xiao, Kashif Rasul, Roland Vollgraf. arXiv: TBA
这篇论文将在 Mon, 28 Aug 2017 00:00:00 GMT 发表在 arXiv 上。
[1] 经典 MNIST 数据集:
http://yann.lecun.com/exdb/mnist/
[2] 基于 scikit-learn 的评测:
http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/
[3] MNIST 测试代码:
https://gist.github.com/dgrtwo/aaef94ecc6a60cd50322c0054cc04478
欢迎点击「阅读原文」查看数据集完整说明文档和作者论文:
Fashion-MNIST: a Novel Image Dataset for Benchmarking Machine Learning Algorithms
关于作者:
肖涵,德国 Zalando 旗下研究部门资深科学家,德国慕尼黑工业大学计算机博士,研究方向为深度学习在产品搜索中的应用。
关于 PaperWeekly:
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。
本文为机器之心转载,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com





