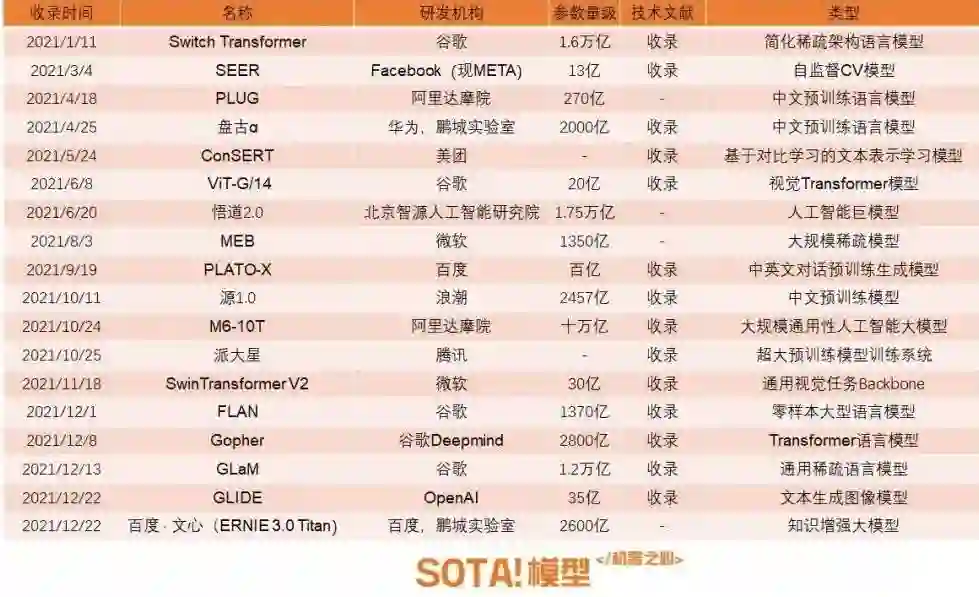
盘古α, Gopher, 派大星, GLIDE...18个中美大厂去年搞的大模型工作我们试着总结回顾了一下
壬寅虎年正月初二起,机器之心 SOTA!模型启动「虎卷er行动」连续五天解锁 1套五十道「年度大题」+ 4套「年度回顾」复习资料,帮助各位老伙计快速温故知新、了解过去一年的重要AI技术工作为目标。所有题目均已在正月初二公开,所有「年度大题」答案均藏在「虎卷er」的「年度回顾」复习资料。








-
提出了一种大规模分布式模型训练方法加速巨量预训练模型训练速度。 -
搭建一套高效的训练数据挖掘流程,持续从海量的互联网挖掘5TB的高质量文本。 -
提出了一种校准方法和标签扩充的方法,解决预训练数据资label数据分布不均匀的问题,明显提升零样本和少样本领域预训练模型效果。



-
提出后规范化(Post Normalization)技术 与可缩放(Scaled)cosine注意力提升大视觉模型的稳定性; -
提出log空间连续位置偏置 技术进行低分辨率预训练模型向高分辨率模型迁移。 -
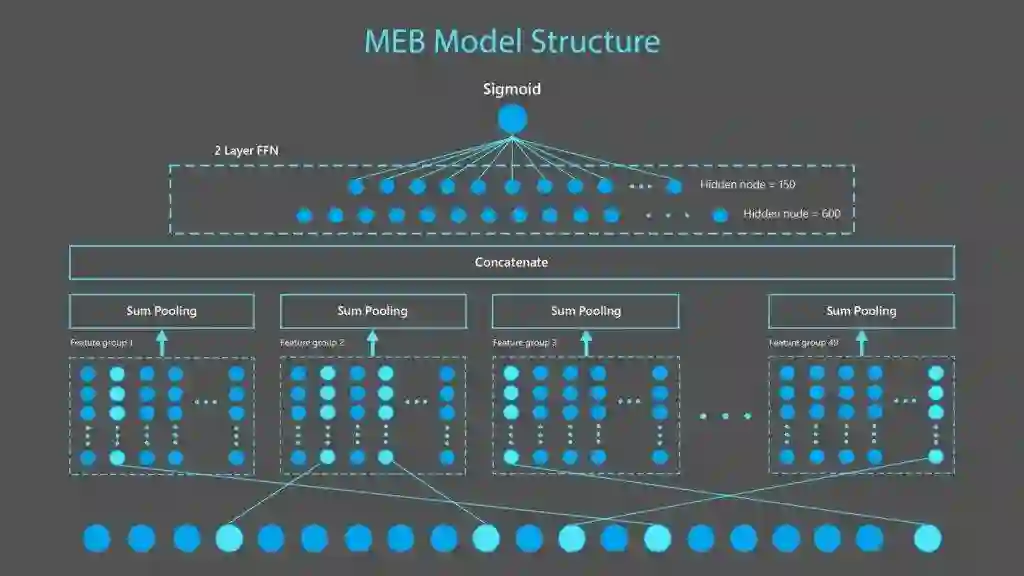
共享了至关重要的实现细节 ,它可以大幅节省GPU显存占用以使得大视觉模型训练变得可行。





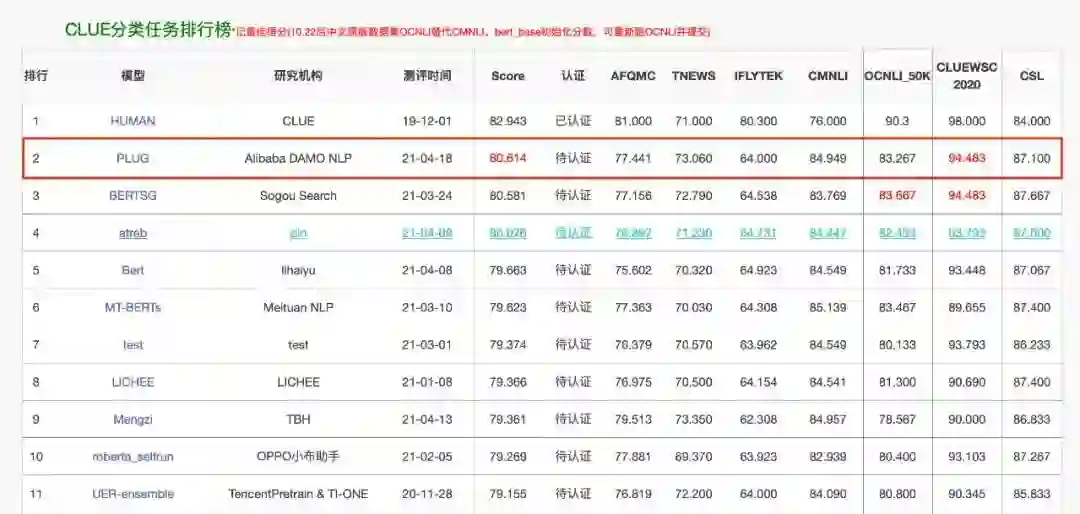
在SOTA!模型推出的「虎卷er行动」中,我们基于2021年度国际AI顶会「Best Papers」、重要SOTA工作,形成总计五十道年度大题。具体分布如下:
-
「Best Papers」:共 7 题
-
「大牛组的工作」:共 12 题
-
「大模型」:共 19 题
-
「刷爆基准的SOTA工作」:共 12 题


登录查看更多
相关内容

Arxiv
0+阅读 · 2022年4月20日
Arxiv
0+阅读 · 2022年4月19日
Arxiv
0+阅读 · 2022年4月15日




相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2022年4月20日
Arxiv
0+阅读 · 2022年4月19日
Arxiv
0+阅读 · 2022年4月15日