稀疏大模型简述:从MoE、Sparse Attention到GLaM

文 | 唐工
源 | 知乎
Sparsity, ..., is another important algorithmic advance that can greatly improve efficiency.
稀疏性,是(神经架构搜索)之外另一个重要的算法进步,可以大大提高效率。
The use of sparsity in models is ... very high potential payoff in terms of computational efficiency, and we are only scratching the surface ...
在模型中使用稀疏性在计算效率方面具有非常高的潜在回报,我们仅仅触及皮毛。
稀疏性(Sparsity),指的是模型具有非常大的容量,但只有模型的用于给定的任务、样本或标记的某些部分被激活。这样,能够显著增加模型容量和能力,而不必成比例增加计算量。
-
2017年,谷歌引入了 稀疏门控的专家混合层(Sparsely-Gated Mixture-of-Experts Layer,MoE),该层在各种转换基准测试中显示出更好的结果,同时使用的计算比以前最先进的密集 LSTM 模型少10倍。 -
2021年,谷歌的 Switch Transformers 将 MoE 风格的架构与 Transformer 模型架构相结合,与密集的 T5-Base Transformer 模型相比,训练时间和效率提高了7倍。 -
2021年,谷歌的 GLaM 模型表明,Transformer 和 MoE 风格的层可以组合在一起生成一个模型,在29个基准测试中平均超过GPT-3模型的精度,而使用3倍少的能耗进行训练和2倍少的计算进行推理。
另外,稀疏性的概念,也可以应用于降低核心 Transformer 架构中注意力机制的成本(ETC 模型、BigBird 模型等)。
稀疏模型简介:部分激活的超大模型
稀疏门控 MoE:超大型神经网络的条件计算
The capacity of a neural network to absorb information is limited by its number of parameters.
神经网络吸收信息的能力,受限于其参数的数量。
专家混合模型(Mixture-of-Experts layer,MoE),这种模型可以被认为是具有不同的子模型(或专家),每个子模型专门用于不同的输入。每一层中的专家由门控网络控制,该网络根据输入数据激活专家。对于每个标记(通常是一个单词或单词的一部分),门控网络选择最合适的专家来处理数据。
稀疏门控专家混合模型(Sparsely-Gated MoE),旨在实现条件计算(Conditional computation)在理论上的承诺,即神经网络的某些部分以每个样本为基础进行激活,作为一种显著增加模型容量和能力而不必成比例增加计算量的方法。
稀疏门控 MoE,由多达数千个专家组成,每个专家都是一个简单的前馈(feed-forward)神经网络,以及一个可训练的门控网络,该网络选择专家的稀疏组合(sparse combination)来处理每个输入样本。网络的所有部分都通过反向传播联合训练。
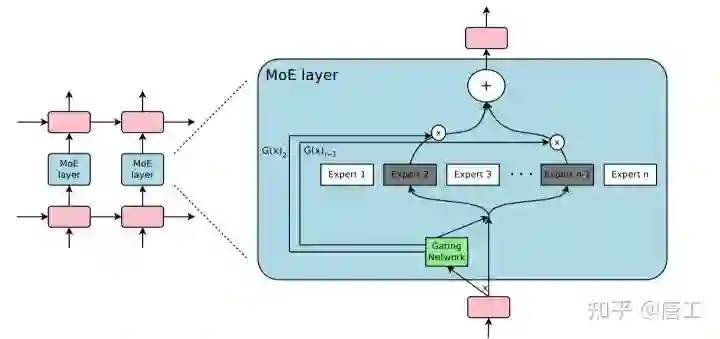
嵌入在循环(recurrent)语言模型中的专家混合 (Mixture of Experts,MoE) 层。在这种情况下,稀疏门控函数选择两个专家来执行计算。它们的输出由门控网络的输出调制。
稀疏门控 MoE,实现了模型容量超过1000倍的改进,并且在现代 GPU 集群的计算效率损失很小。
Switch Transformer:通过简单高效的稀疏性扩展到万亿参数模型
Mixture of Experts (MoE) ... a sparsely-activated model -- with outrageous numbers of parameters -- but a constant computational cost.
专家混合模型(MoE),...,一个稀疏激活的模型 - 具有惊人的参数数量 - 但计算成本恒定。
Switch Transformer,旨在解决 MoE 的复杂性、通信成本和训练不稳定性而导致的难以被广泛采用的问题。
Switch Transformer,简化了 MoE 路由算法,设计了直观的改进模型,同时降低了通信和计算成本。
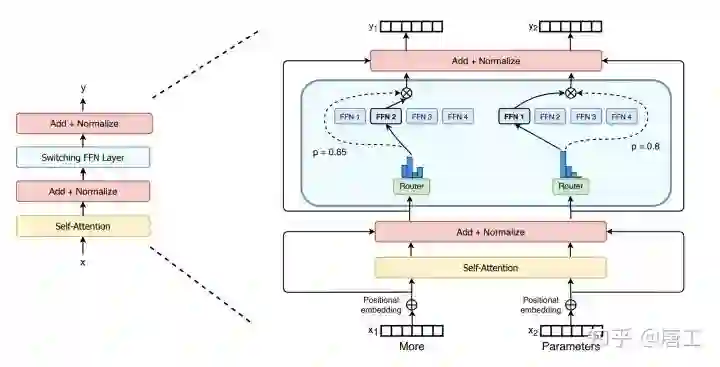
Switch Transformer 编码器块的示意图。将 Transformer 中的密集前馈网络 (FFN) 层替换为稀疏 Switch FFN 层(浅蓝色)。该层独立地对序列中的标记进行操作。两个标记在四个 FFN 专家之间路由(实线),其中 Router 独立路由每个标记。Switch FFN 层返回所选 FFN 的输出乘以 Router 门控值(虚线)。
Switch 层的好处有三方面:
-
减少了路由器计算,因为只将标记路由给单个专家。 -
每个专家的批量大小(专家容量)至少可以减半,因为每个标记只被路由到单个专家。 -
简化路由实现,降低通信成本。
每个专家处理由容量因子调制的固定批量大小的标记。每个标记被路由到具有最高路由概率的专家,但每个专家都有一个固定的批量大小 (total tokens / num experts) × capacity factor。
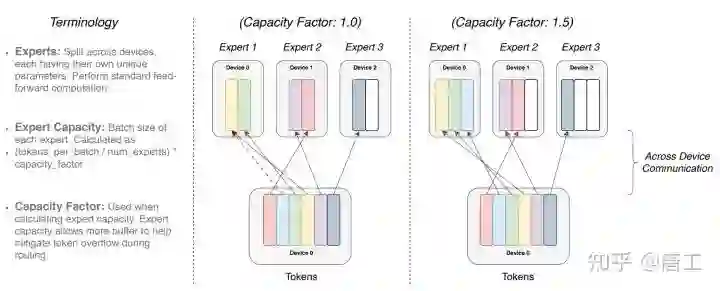
具有不同专家容量因子(capacity factor)的标记路由示例。如果标记分配不均,则某些专家将溢出(由红色虚线表示),导致这些标记不被该层处理。更大的容量因子缓解了这种溢出问题,但也增加了计算和通信成本(由填充的白色/空槽描述)。
GLaM 模型:更有效的上下文学习
Is it possible to train and use large language models more efficiently?
是否有可能更有效地训练和使用大型语言模型?
大型语言模型(例如,GPT-3)具有许多重要的能力,例如在一系列广泛的任务中执行少样本学习few-shot learning,包括只有很少或根本没有训练样本的阅读理解和问答。仅仅使用更多的参数就可以使其执行得更好,但训练这些大型模型却是极其计算密集的。
GLaM (Generalist Language Model)模型,旨在解决训练大型密集模型(比如 GPT-3需要大量的计算资源的问题。GLaM 模型是一簇通用语言模型,由于其稀疏性,可以 (在计算和能耗方面) 有效地进行训练和提供服务,并且在多个少样本学习任务上取得了更好的表现。
GLaM 模型使用稀疏激活的 MoE 架构来扩展模型容量,完整版总共有 32 个 MoE 层,在每个 MoE 层有 64 个专家,每个专家都是具有相同架构但权重参数不同的前馈网络。与密集的变体相比,训练成本大大减少。在推理期间,GLaM 对于每个标记预测仅激活 97B( 1.2T 的 8% )参数的子网络。
GLaM 将每隔一个 Transformer 层的单个前馈网络(人工神经网络的最简单层,蓝框中的"Feedforward 或 FFN")替换为 MoE 层。其中每个输入标记都被动态地路由到64个专家网络中的选定的两个,以进行预测。标记的最终学习表示形式将是两位专家输出的加权组合。
尽管此 MoE 层相比 Transformer 层的单个前馈网络具有更多参数,但专家被稀疏激活,这意味着对于给定的输入标记,仅使用两个专家,从而在限制计算的同时为模型提供更多容量。在训练期间,每个 MoE 层的_门控网络_都经过训练,以使用其输入为每个标记激活最佳两个专家,然后将其用于推理。对于 E 个专家的 MoE 层,这实质上提供了_E_×(E-1) 个不同前馈网络组合的集合(而不是像经典 Transformer 架构中那样的一个),从而提高了计算灵活性。
标记的最终学习表示形式将是两位专家输出的加权组合。这允许不同的专家在不同类型的输入上激活。为了能够扩展到更大的模型,GLaM 架构中的每个专家都可以(使用GSPMD编译器后端扩展)跨多个计算设备。
...It consumes only 1/3 of the energy used to train GPT-3 and requires half of the computation flops for inference...
...它只消耗 GPT-3训练所需能耗的1/3,并且只需要一半的浮点运算进行推理...
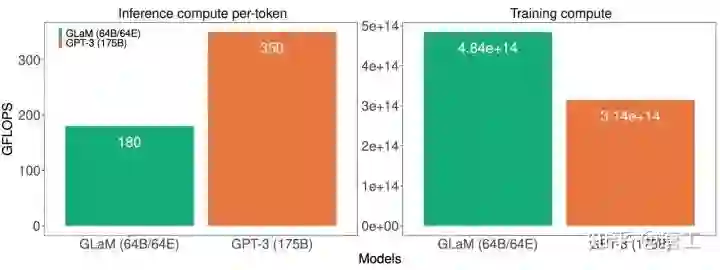
计算成本对比,1.2T 参数的稀疏激活模型 GLaM 和 175B 参数的稠密模型 GPT-3 模型,包括每个标记的推理(左)和训练(右)。
GLaM 在训练期间使用更多的计算,因为它在更多的标记上进行训练,但在推理过程中使用的计算要少得多。虽然 GLaM 在训练期间使用更多的计算,但由于 GSPMD 驱动的更有效的软件实现和 TPUv4 的优势,它比其他模型使用更少的功率进行训练。
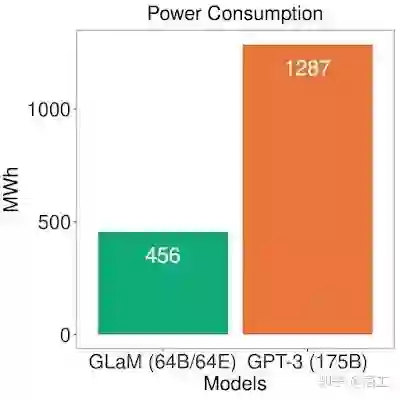
稀疏注意力机制:构建用于更长序列的 Transformer
Transformer 的问题
Transformer 的关键创新之处在于引入了自注意力机制,该机制计算输入序列中所有位置对的相似性得分,并且可以对输入序列的每个标记并行计算,避免了 RNN 的顺序依赖性。
然而,现有的 Transformer 模型及其衍生模型的一个局限性是,完全自注意力机制的计算和内存需求与输入序列长度成二次(quadratic)关系,这限制了输入序列的长度。
两个自然的问题出现了:
-
能否使用稀疏模型实现二次全 Transformer 的实证优势,同时让计算和内存需求的扩展与输入序列长度成 线性关系(ETC 模型)? -
有没有可能从理论上证明,这些 线性 Transformer(BigBird 模型)保持了二次全 Transformer 的 表现力和灵活性?
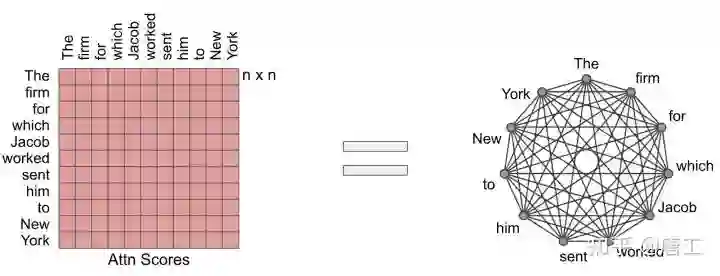
注意力作为图
把注意力机制想象成一个有向图(标记由节点表示,相似度评分由边表示)是很有用的。在这个观点中,完全注意力模型就是一个完全图(complete graph)。
这个方法背后的核心思想是仔细地设计稀疏图,这样只需要计算线性数量的相似性得分。
ETC:在 Transformer 中编码长的结构化输入
ETC(Extended Transformer Construction),是一种扩展 Transformer 结构的稀疏注意力(sparse attention)的新方法,它利用结构信息(structural information)限制计算出的相似性得分对的数目。这就将对输入长度的二次依赖降低为线性。
ETC 实现了注意力的线性缩放,使其可以显著缩放输入长度,主要源自全局-局部注意力(global-local attention)机制。其中,对 Transformer 的输入分为两部分:
-
全局输入(global input),其中标记具有无限制的注意力; -
长输入(long input),其中标记只能注意全局输入或局部相邻输入。
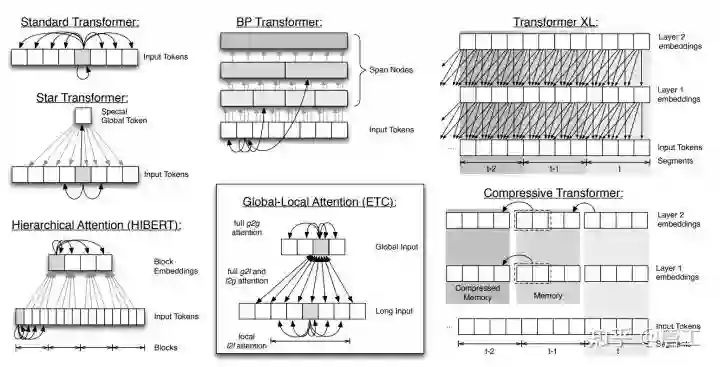
上图是ETC 模型对长输入的扩展注意力机制的说明。
Big Bird: 用于更长序列的 Transformer
BigBird,是将 ETC 扩展到更一般的场景的另一种稀疏注意力机制,在这些场景中,源数据中存在的关于结构的必备领域知识可能无法获得。此外,还从理论上证明了稀疏注意力机制保持了二次型全 Transformer 的表达能力和灵活性。
BigBird 模型中的稀疏注意力包括三个主要部分:
-
一组注意输入序列的所有部分的全局标记 -
所有标记注意一组相邻的局部标记 -
所有标记注意一组随机标记
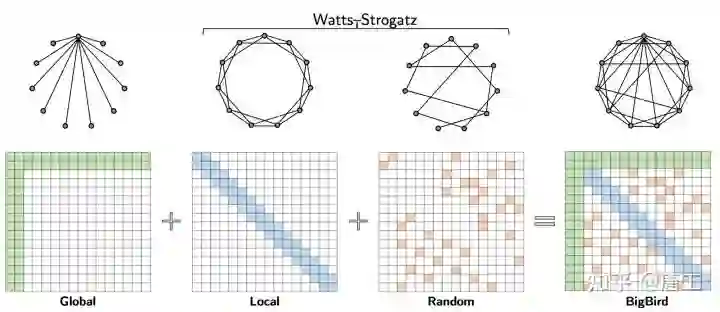
BigBird 稀疏注意力模型由(注意输入序列的所有部分的)全局标记、局部标记和一组随机标记组成。从理论上讲,这可以解释为在 Watts-Strogatz 图上增加了很少的全局标记
为什么稀疏注意力足以接近二次注意力:
A crucial observation is that there is an inherent tension between how few similarity scores one computes and the flow of information between different nodes (i.e., the ability of one token to influence each other).
一个重要的观察结果是,在计算的相似性得分如何的少,和不同节点间的信息流(即,一个标记相互影响的能力)之间存在一种内在的张力关系。
全局标记作为信息流的管道,证明了使用全局标记的稀疏注意力机制可以和全注意模型一样强大。
稀疏注意力模型的高效实现
大规模采用稀疏注意力的一个主要障碍,是稀疏操作在现代硬件中效率相当低。
由于现代硬件加速器(如 GPU 和 TPU)擅长使用合并内存操作(一次加载连续字节块) ,因此由滑动窗口(用于局部注意力)或随机元素查询(随机注意力)引起的小型零星查找是不高效的。
相反,将稀疏的局部注意力和随机注意力转换成密集的张量运算,以充分利用现代单指令、多数据(single instruction, multiple data),SIMD)硬件。
-
首先“阻塞(blockify)”注意力机制,以更好地利用 GPU/TPU,它们被设计为在 块上运行。 -
然后,通过一系列简单的矩阵运算,如重塑、滚动和聚集,将稀疏注意机制计算转化为密集的张量积。
稀疏注意力机制的高效实现示意图。稀疏窗口的注意力是如何有效地计算使用滚动和重塑,而没有小的零星查找。
结论
... carefully designed sparse attention can be as expressive and flexible as the original full attention model. Along with theoretical guarantees, ... a very efficient implementation allows us to scale to much longer inputs. 完全注意力模型可以看作是一个完全图 ... 精心设计的稀疏注意力和原始的全注意模型一样具有表达性和灵活性。除了理论上的保证之外,非常高效的实现使我们能够扩展到更长的输入。
因此我们将看到更大容量和更强能力的模型,但不必担心计算量的显著增长。
后台回复关键词【入群】
加入卖萌屋NLP、CV与搜推广求职讨论群
后台回复关键词【顶会】
获取ACL、CIKM等各大顶会论文集!
![]()
 后台回复关键词【
后台回复关键词【