中科大&京东最新成果:让AI像真人一样演讲,手势打得惟妙惟肖
丰色 发自 凹非寺
量子位 | 公众号 QbitAI
人类在说话时会自然而然地产生肢体动作,以此来增强演讲效果。

现在,来自中科大和京东的研究人员,给AI也配备了这样的功能——
随便丢给它一段任意类型的演讲音频,它就能比划出相应的手势:
配合得非常自然有没有?
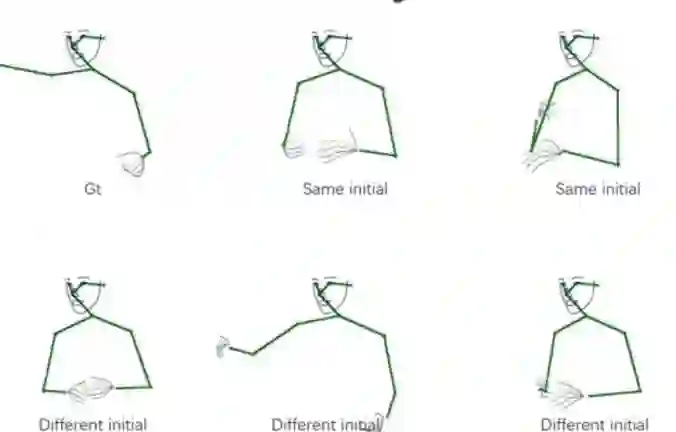
对于同一个音频,它还能生成多种不一样的姿势:
采用“双流”架构
由于每个人的习惯并不相同等原因,演讲和肢体动作之间并没有一套固定的对应关系,这也导致完成语音生成姿势这一任务有点困难。

大多数现有方法都是以某些风格为条件,以一种确定性的方式将语音映射为相应肢体动作,结果嘛,也就不是特别理想。
受语言学研究的启发,本文作者将语音动作的分解为两个互补的部分:姿势模式(pose modes)和节奏动力(rhythmic dynamics),提出了一种新颖的“speech2gesture”模型——FreeMo。
FreeMo采用“双流”架构,一个分支用于主要的姿势生成,另一个分支用于“打节奏”,也就是给主要姿势施加小幅度的节奏动作(rhythmic motion),让最终姿势更丰富和自然。
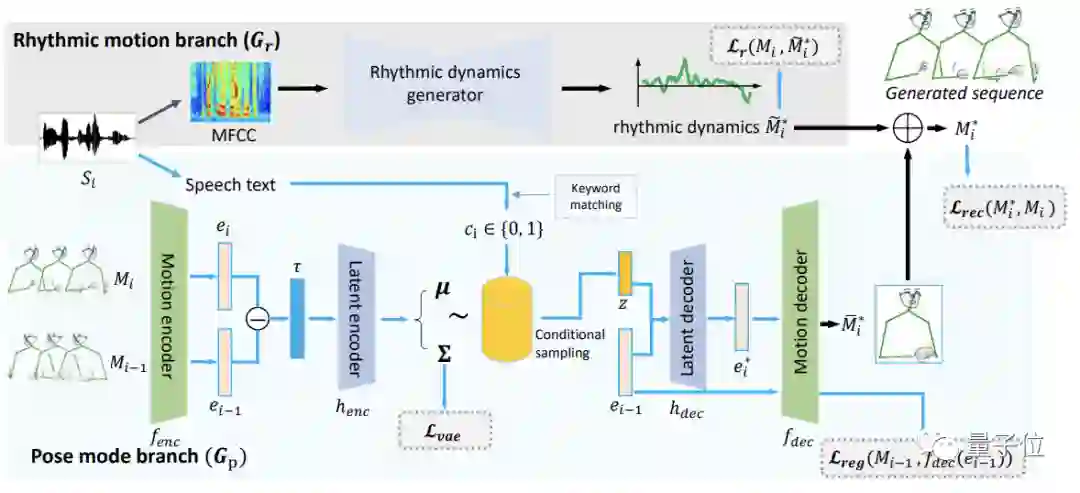
前面说过,演讲者的姿势主要是习惯性的,没有常规语义,因此,作者也就没有对姿势生成的形式进行特别约束,而是引入条件采样在潜空间学习各种姿势。
为了便于处理,输入的音频会被分成很短的片段,并提取出语音特征参数MFCC和演讲文本。
主要姿势通过对演讲文本进行关键字匹配生成。
语音特征参数MFCC则用于节奏动作的生成。
节奏动作生成器采用卷积网络构成,具体过程如图所示:
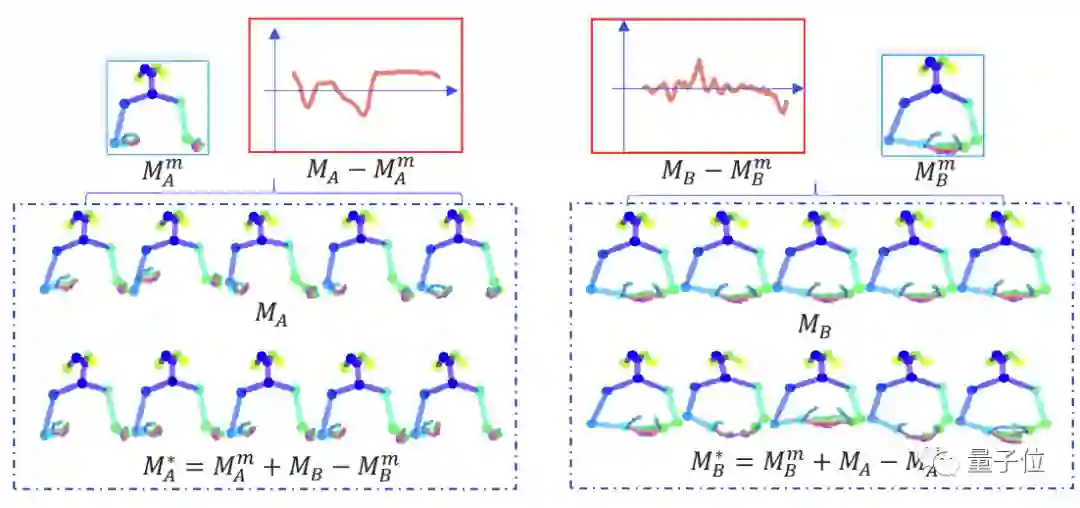
MA和MB是训练集中随机抽取的两个动作序列。
红色框表示动作序列平均姿势的偏移量。通过交换俩个序列的偏移量,模型就可以在不影响主要姿势的情况下进行“节奏”控制。
更具多样性、更自然、同步性更高
FreeMo的训练和测试视频包括专门的Speech2Gesture数据集,里面有很多电视台主持人的节目。
不过这些视频受环境干扰严重(比如观众的喝彩声),以及主持人可能行动有限,因此作者还引入了一些TED演讲视频和Youtube视频用作训练和测试。

对比的SOTA模型包括:
采用RNN的Audio to Body Dynamics (Audio2Body)
采用卷积网络的Speech2Gesture (S2G)
Speech Drives Template (Tmpt,配备了一组姿势模板)
Mix StAGE(可以为每一个演讲者生成一套风格)
Trimodal-Context (TriCon,同样为RNN,输入包括音频、文本和speaker)
衡量指标一共有三个:
(1)语音和动作之间的同步性;
(2)动作的多样性;
(3)与演讲者的真实动作相比得出的质量水平。
结果是FreeMo在这三个指标上都超越5个SOTA模型获得了最好的成绩。
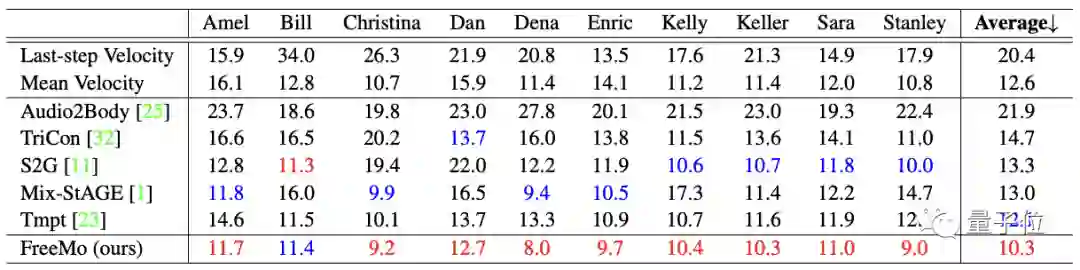
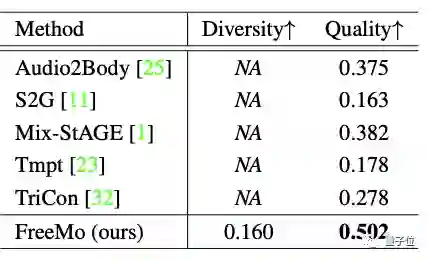
ps. 由于5个SOTA模型在本质上都是学习的确定性映射,因此不具备多样性。
一些更直观的质量对比:

最左上角为真实演讲者的动作,可以看到FreeMo的表现最好(Audio2Body也还不错)。
作者介绍

一作为Xu Jing,来自中科大。
通讯作者为京东AI平台与研究部AI研究院副院长,京东集团技术副总裁,IEEE Fellow梅涛。
剩余3位作者分别位来自京东AI的研究员Zhang Wei、白亚龙以及中科大的孙启彬教授。
论文地址:
https://arxiv.org/abs/2203.02291
代码已开源:
https://github.com/TheTempAccount/Co-Speech-Motion-Generation
— 完 —
「人工智能」、「智能汽车」微信社群邀你加入!
欢迎关注人工智能、智能汽车的小伙伴们加入我们,与AI从业者交流、切磋,不错过最新行业发展&技术进展。
ps.加好友请务必备注您的姓名-公司-职位哦~

点这里👇关注我,记得标星哦~
一键三连「分享」、「点赞」和「在看」
科技前沿进展日日相见~




