哈工大&京东提出:计算机视觉新任务!从“能说会道”到“察言观色”!
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
在京东探索研究院ViDA-MAN数字人获ACM MM 2021最佳Demo奖后,近日,京东探索研究院又联合哈尔滨工业大学,对标Talking Head Generation,弥补双人沟通时倾听这一行为建模的空白,提出了一个新任务——Listening Head Generation和一个新的对话型视频数据集——ViCo。
论文标题:Responsive Listening Head Generation: A Benchmark Dataset and Baseline
论文链接:https://arxiv.org/abs/2112.13548
项目链接:https://project.mhzhou.com/rld

01
项目背景
沟通是每个人在日常生活中最常见的活动之一。在面对面的交流中,双方依次在讲者和听者之间转换角色,以有效地交换信息。讲者会以言语向听者传递信息,而听者则主要通过非语言的行为向讲者提供实时反馈,如点头、微笑、摇头等。
尽管在实践中经常使用静态图像、重复帧或预置动画来表示听者,但它们往往是僵硬的,不足以对讲者做出适当的反应。而根据社会心理学和人类学的研究,倾听是一种特定功能和条件的行为,是可以从训练数据中推断出可学习的模式的。在国外关于Active Listening是医生或者教师等职业必备的培训内容。
在这篇论文中,作者认为听众表达观点的常见模式是可以被观察到的:
对称和循环运动被用来表示 "是"、"不是 "或类似的信号
窄的线性动作与对方讲话中的强调音节相配合
宽的线性动作在对方讲话的停顿中出现
在人类面对面的互动中,甚至连听众眨眼的时间都被视为交流信号。
而听者动作的这些模式主要受两个信号的影响:听者的态度和说话者的信号。
其中,听者的不同态度会导致不同的面部表情,例如,"同意 "的态度是指 "点头 "和 "接受","不相信 "的态度则是指 "头部倾斜 "和 "皱眉 "的组合。

同时,倾听行为在很大程度上受到说话人动作和音频信号的影响。例如,听者的动作流可能与讲者的讲话和动作有节奏地协调。这些心理学和伦理学的研究促使作者提出一种数据驱动的方法来为面对面交流的倾听行为建模。
02
聆听态数字人任务定义
文中作者首先回顾了目前以说话人为中心的合成方面的相关研究任务,包括:
Speech to Gesture. 学习音频信号和说话人姿势之间的映射
Speech to Lip Generation. 使给定视频输入的嘴唇运动与音频同步
Talking Head Generation. 从静止的图像和音频片段中生成一个生动的带有面部动画的特定说话人的视频

作者认为这些工作只关注说话者的角色,而忽略了听者这一不可或缺的对应角色。为此,文中提出了一个新的任务:Listening Head Generation,该任务旨在根据讲者的音视频和听者的身份信息,合成一个听者的视频,其中听者的适当反应被期望与输入的谈话视频相协调。类似video-to-video translation,但是建模过程中由于说话人的信号是连续的,要求listening head的建模也是时序的且需要实时响应说话人状态。
为了解决这个问题,文中构建了一个高质量的说话者-听众视频对话数据集——ViCo,通过捕捉两个人在同一屏幕上包含正面的公共对话的高清视频数据。该数据严格遵循一个视频片段只包含唯一识别的听者和说话者的原则,并要求听者对说话者有回应性的动作/表情反馈。

总的来说,ViCo数据集包含了483个视频片段,其中有76个听众对67个演讲者做出了回应。与MEAD和VoxCeleb2等以说话者为中心的数据集相比,ViCo数据集可同时应用于talking head以及listening head的建模,具有更广的应用范围。

与该数据集一起,文中还提出了一种listening head生成的基线方法:
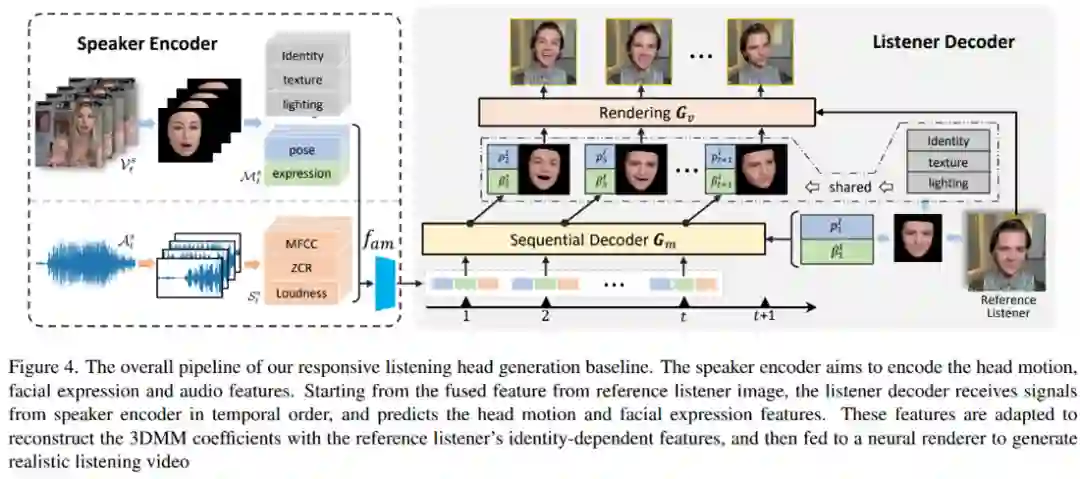
03
生成结果展示
以下截取了论文中的一些实验结果展示:
1) 对比模型生成的听者、随机运动的听者与随机从数据集中采样听者的结果

2) 固定讲者和音频,对比生成的不同态度的听者

3) 论文中方法所生成的听者多样性

ICCV和CVPR 2021论文和代码下载
后台回复:CVPR2021,即可下载CVPR 2021论文和代码开源的论文合集
后台回复:ICCV2021,即可下载ICCV 2021论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
CVer-Transformer交流群成立
扫描下方二维码,或者添加微信:CVer6666,即可添加CVer小助手微信,便可申请加入CVer-Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。
一定要备注:研究方向+地点+学校/公司+昵称(如Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信: CVer6666,进交流群
CVer学术交流群(知识星球)来了!想要了解最新最快最好的CV/DL/ML论文速递、优质开源项目、学习教程和实战训练等资料,欢迎扫描下方二维码,加入CVer学术交流群,已汇集数千人!
▲扫码进群
▲点击上方卡片,关注CVer公众号
整理不易,请点赞和在看