【DL】规范化:你确定了解我吗?

Batch Normalization(以下简称 BN)出自 2015 年的一篇论文《Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift》,是最近几年来 DL 领域中非常重要的成功,并且已经被广泛证明其有效性和重要性。本篇文章将对此进行详细介绍,帮助大家更加深入的理解 BN。
此外,也会简单介绍下 BN 的一些改进算法,比如 Layer Norm、Instance Norm、Group Norm等。
除此之外,还会介绍一篇 MIT 对 BN 进行讨论分析的论文,以帮助大家更好的了解 BN。
1.Normalization
先看下基本概念。
Normalization 英翻为规范化、标准化、归一化。
维基百科中给出:
-
min-max normailzation(常简称为 normailzation):
-
Mean normalization:
-
Standardization (Z-score Normalization):
我们这里的 Normalization 是指第三种——标准化。
深度学习中的 Normalization 根据规范化操作涉及的对象不同可以大致分为两大类,一类是对 l 层的激活后的输出值进行标准化,Batch Norm、Layer Norm、Instance Norm、Group Norm 就属于这一类;另外一类是对神经元连接边的权重进行规范化操作,Weight Norm 就属于这一类。
举一个规范化中比较经典的例子,下图左边为原图,右图为归一化的结果,可以增强图像的表达:

2.Internal Covariate Shift
从论文的标题可以看到:BN 是用来减少 “Internal Covariate Shift” 来加速网络的训练。
那么,什么是 Internal Covariate Shift 呢?
论文指出:神经网络在更新参数后各层输入的分布会发生变化,从而给训练带来困难。这种现象被称为内部协变转移(Internal Covariate Shift,以下简称 ICS)。
更形象一点来说,如果网络在传播过程中,数据分布稍微发生些变化,便会不断累积从而产生梯度消失和梯度爆炸的问题。
ICS 会带来什么样的危害呢?主要有以下两点:
-
首先,在训练过程中,每一层网路计算结果的分布都在发生变化,这使得后一层网络需要不停的适应这种分布变化,这便会降低网络的收敛速度; -
其次,在训练过程中,模型容易陷入激活函数的饱和区,导致梯度变小,降低参数的更新速度。
为了解决这个问题,我们会采用较小的学习率和特定的权重初始化(比如,前面介绍的初始化)。
但参数初始化的方式非常依赖激活函数,并不能给出通用的解决方案。而 Google 的同学在 2015 年给出了一个非常优雅的解决方法——Batch Normalization。
3.Batch Normalization
3.1 Base
BN 翻译过来就是批标准化:
-
批是指一批数据,通常为 mini-batch; -
标准化则是服从均值为 0、方差为 1 的正态分布。
BN 的核心思想在于使得每一层神经网络的输入保持相同的分布。
目前有两种插入 Norm 操作的地方,一种是 GN 论文中提出的,在激活函数之前进行 Norm;还有一种是后续研究提出的,放在激活函数之后进行,并且研究表明,放在激活函数之后的效果更好。但不论哪种,其规范化的目的都是一样的。
BN 的优点有哪些什么呢?
-
首先,由于神经网络的分布相同,所以可以使用更大的学习率,从而加速模型的收敛; -
其次,我们不需要在去精心设计权值的初始化; -
再者,我们也不需要用 Dropout,或者说可以使用较小的 Dropout; -
然后,也不需要使用 L2 或者 weight decay; -
最后,也不需要使用 LRN(Local response normalization)。
可以说 BN 是一个相当强大的深度学习杀手锏了。
3.2 Algorithm
BN 的计算方式很简单,给定 d 维的输入 ,我们会对「特征的每一个维度」进行规范化:
我们来看下算法的具体实现方式:

-
输入的是一个 Batch 数据,和两个可学习参数 ; -
首先计算 mini-batch 的均值和方差; -
然后计算 normalize,分母中的 是为了防止除 0; -
最后利用 affine transform 来对 x 进行缩放和偏移,从而增强模型的表达能力,使得模型更加灵活、选择性更多,利用可学习参数将数据分布的改变权交给模型。
3.3 Code
为了更形象的了解到 BN 的作用,我们通过代码来直观感受一下:
我们先来看下精心设计的初始化的效果(relu 激活函数用 kaiming 初始化):
class MLP(nn.Module):
def __init__(self, neural_num, layers=100):
super(MLP, self).__init__()
self.linears = nn.ModuleList(
[nn.Linear(neural_num, neural_num, bias=False) for i in range(layers)])
self.bns = nn.ModuleList([nn.BatchNorm1d(neural_num) for i in range(layers)])
self.neural_num = neural_num
def forward(self, x):
for i, linear in enumerate(self.linears):
x = linear(x)
x = torch.relu(x)
if torch.isnan(x.std()):
print("output is nan in {} layers".format(i))
break
print("layers:{}, std:{}".format(i, x.std().item()))
return x
def initialize(self):
for m in self.modules():
if isinstance(m, nn.Linear):
nn.init.kaiming_normal_(m.weight.data)
neural_nums = 256
layer_nums = 100
batch_size = 16
net = MLP(neural_nums, layer_nums)
net.initialize()
inputs = torch.randn((batch_size, neural_nums)) # normal: mean=0, std=1
output = net(inputs)
layers:0, std:0.8313311338424683
layers:1, std:0.8171090483665466
layers:2, std:0.7833468317985535
...
layers:37, std:0.36964893341064453
layers:38, std:0.3796547055244446
layers:39, std:0.4119926393032074
...
layers:97, std:0.9331600069999695
layers:98, std:0.9478716850280762
layers:99, std:0.8747168183326721
可以看到不会出现梯度爆炸或消失的问题。
我们再来看下不进行初始化,而使用 BN 的效果,首先尝试下放在激活函数之前:
class MLP(nn.Module):
def __init__(self, neural_num, layers=100):
super(MLP, self).__init__()
self.linears = nn.ModuleList(
[nn.Linear(neural_num, neural_num, bias=False) for i in range(layers)])
self.bns = nn.ModuleList([nn.BatchNorm1d(neural_num) for i in range(layers)])
self.neural_num = neural_num
def forward(self, x):
for (i, linear), bn in zip(enumerate(self.linears), self.bns):
x = linear(x)
x = bn(x) # 放在激活函数之前
x = torch.relu(x)
if torch.isnan(x.std()):
print("output is nan in {} layers".format(i))
break
print("layers:{}, std:{}".format(i, x.std().item()))
return x
neural_nums = 256
layer_nums = 100
batch_size = 16
net = MLP(neural_nums, layer_nums)
inputs = torch.randn((batch_size, neural_nums)) # normal: mean=0, std=1
output = net(inputs)
layers:0, std:0.578612744808197
layers:1, std:0.5762764811515808
layers:2, std:0.5789310932159424
...
layers:37, std:0.5788312554359436
layers:38, std:0.5814399123191833
layers:39, std:0.5776118040084839
...
layers:97, std:0.5784409642219543
layers:98, std:0.5822523236274719
layers:99, std:0.5745156407356262
基本上是在 0.57~0.59 之间浮动。
3.4 Pytorch
Pytorch 中 实现了三种 BN,分别为 BatchNorm1d、BatchNorm2d 和 BatchNorm3d,都继承了 _BatchNorm 这个基类。
_BatchNorm 有多个重要参数:
class _BatchNorm(_NormBase):
def __init__(self, num_features, eps=1e-5, momentum=0.1, affine=True,
track_running_stats=True):
...
-
num_features 为特征个数(很重要,待会儿介绍); -
eps 为分母中修正项 ; -
momentum 用于指数加权平均估计当前的均值和方差; -
affine 为是否使用 affine transform,默认是使用的; -
track_running_stats 表示训练或测试的状态。
_BatchNorm 具有四个主要的属性:
-
running_mean 为均值; -
running_var 为方差; -
weight 为 affine transform 中的 gamma; -
bias 为 affine transform 中的 beta。
BN 在训练和测试过程中,其均值和方差的计算方式是不同的。测试过程中采用的是基于训练时估计的统计值,而在训练过程中则是采用指数加权平均计算:
BN1d、BN2d、BN3d 的主要区别在于其特征维度,其输入为:
batch_size 为样本数量,feature_size 为每个样本的特征数量,(n)d_feature 为一个特征的维度。下图展示了三种 BN 的区别。
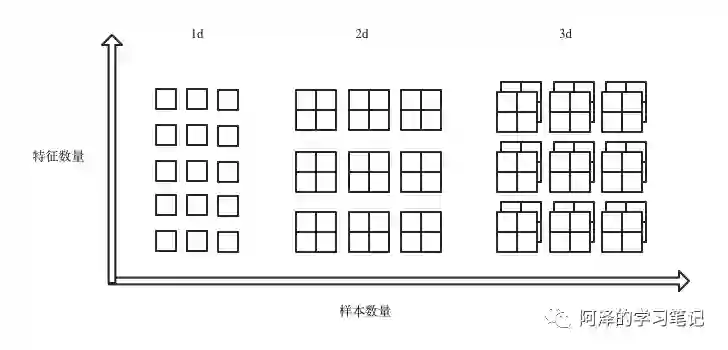
所以三者的输入为:
-
BatchNorm1d:输入输出 shape 为(N, C)或则(N, C, L); -
BatchNorm2d:输入输出 shape 为(N, C,H, W); -
BatchNorm3d:输入输出 shape 为(N, C,D, H, W)。
回过头看下上面 BN 的公式:
也就是说我们是针对 batch 中的特征每个维度进行计算的,如红框部分:
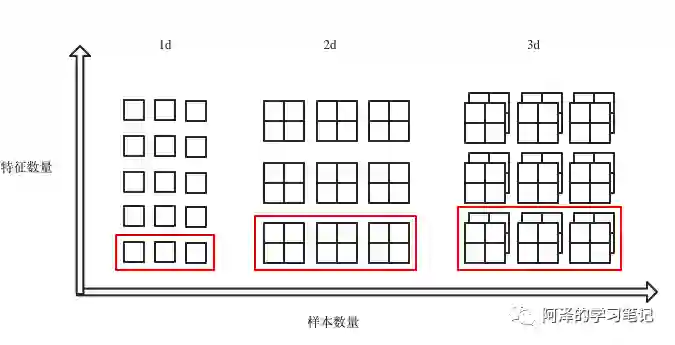
4.Other Normalization
目前常见的 Normalization 有 Batch Norm(BN)、Layer Norm(LN)、Instance Norm(IN)和 Group Norm(GN)。
这四种 Norm 的方式都是标准化和 affine transform,他们的区别在于标准化时均值和方差有所不同。
4.1 Layer Norm
我们知道 BN 是在针对特征的每个维度求当前 batch 的均值和方差,此时便会出现两个问题:
-
当 batch 较小时不具备统计意义,而加大的 batch 又收到硬件的影响; -
BN 适用于 DNN、CNN 之类固定深度的神经网络,而对于 RNN 这类 sequence 长度不一致的神经网络来说,会出现 sequence 长度不同的情况,如下图所示:
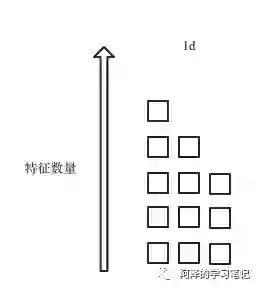
解决的方法很简单,直接竖着来,针对样本进行规范化,如下图所示,
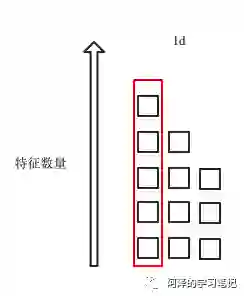
值得注意的是:
-
此时不在会有 running_mean 和 running_var,因为不再需要通过统计信息获取均值和方差。 -
也由共享参数变为逐神经元的参数(RNN 有 n 个神经元,则有 2n 个参数)。
来看一下 LayerNorm 的参数:
class LayerNorm(Module):
def __init__(self, normalized_shape, eps=1e-5, elementwise_affine=True):
-
normalized_shape 为该层特征形状; -
eps 为分母修正项; -
elementwise_affine 为逐元素 affine transform 的开关状态。
4.2 Instance Norm
在图像生成任务中,以风格迁移为例(如下图所示),不同的图像具有不同的模式,如果我们不能将 batch 的数据混为一谈去计算均值和方差。

于是学者提出了逐 Instance(Channel) 计算均值和方差(图像中每个 Channel 数据一般都非常多,所以适合计算统计量)。
IN 的计算方式是针对每一个通道去计算均值和方差,如下图红框:
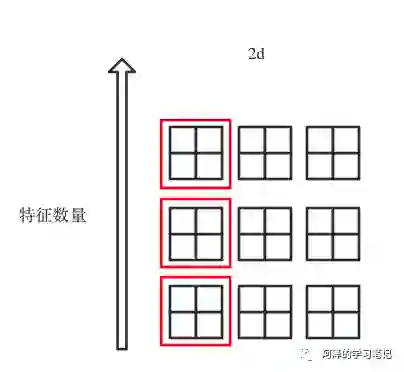
看一下 Instance Norm 的参数:
class _InstanceNorm(_NormBase):
def __init__(self, num_features, eps=1e-5, momentum=0.1, affine=False,
track_running_stats=False):
...
4.3 Group Norm
GN 主要是针对 batch 过小而导致统计值不准的缺点进行优化。
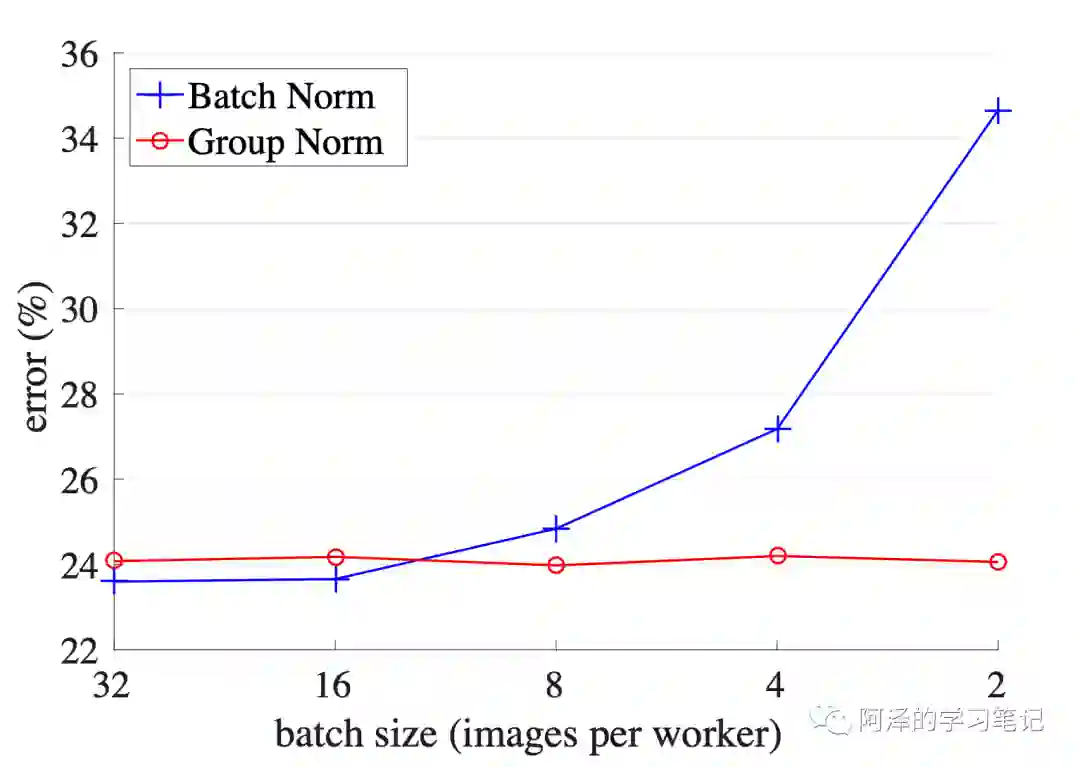
在大型任务中,计算力不足以支撑起很大的 batch size,此时的 batch size 可能只有 2、4,在这种情况下 BN 的效果会非常差。
下图展示了 ResNet 在 BN 和 GN 的作用下随着 BatchSize 变化时的性能变化情况
GN 的解决思路在于「数据不够,通道来凑」。其计算方式如下图所示:
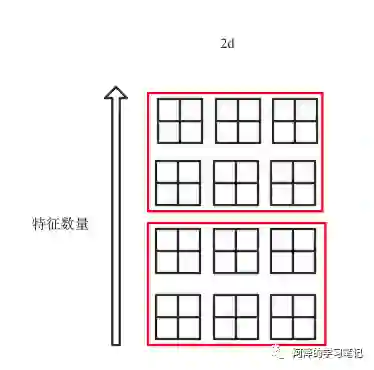
此时值得注意的是:
-
不再有 running_mean 和 running_var -
gamma 和 beta 为逐通道的。
看下 GN 的参数:
class GroupNorm(Module):
def __init__(self, num_groups, num_channels, eps=1e-5, affine=True):
....
-
num_groups 为分组数; -
num_channels 为一个分组的通道数,分组数*通道数=特征数
4.4 Weight Norm
不同于前面介绍的四种针对数据进行 Norm 的方式,Weight Norm 是针对权值进行规范化的。
BN 在进行归一化的过程中是用 batch 进行统计去估计全局信息,此时便会引入噪声。而 WN 则没有这个问题,因此 WN 除了可以应用于 MLP、CNN 外,还可以应用于 RNN、生成网络、强化学习等对噪声敏感的学习中。
我们知道,目标函数的曲率会极大的影响神经网络的优化难度,然而一个目标函数的曲率并是对重参数是变化的,因此可以采取相同模型中多种等效的重参数方法来使得目标函数的优化空间的曲率更加的平滑。
WN 的其核心思想在于将参数 w 进行重参数表示,解藕成欧式范式 g 和方向向量 v:
g 为标量控制大小,v 为与 w 相同维度的向量, 控制方向。
反向传播过程中则是对 v 和 g 进行求偏导。
实验证明,这种解藕有助于加速网络的收敛速度。
5.Discuss BN Again
我们再来讨论一下 BN。这里引用魏秀参老师 2016 年的见解:
❝说到底,BN 的提出还是为了克服深度神经网络难以训练的弊病。其实 BN 背后的 insight 非常简单,只是在文章中被 Google 复杂化了。
文章的title除了BN这样一个关键词,还有一个便是“ICS”。大家都知道在统计机器学习中的一个经典假设是“源空间(source domain)和目标空间(target domain)的数据分布(distribution)是一致的”。如果不一致,那么就出现了新的机器学习问题,如,transfer learning/domain adaptation等。而covariate shift就是分布不一致假设之下的一个分支问题,它是指源空间和目标空间的条件概率是一致的,但是其边缘概率不同,即:对所有 ,但是 . 大家细想便会发现,的确,对于神经网络的各层输出,由于它们经过了层内操作作用,其分布显然与各层对应的输入信号分布不同,而且差异会随着网络深度增大而增大,可是它们所能“指示”的样本标记(label)仍然是不变的,这便符合了covariate shift的定义。由于是对层间信号的分析,也即是“internal”的来由。
那么好,为什么前面我说 Google 将其复杂化了。其实如果严格按照解决 covariate shift 的路子来做的话,大概就是上 “importance weight” 之类的机器学习方法。可是这里 Google 仅仅说“通过 mini-batch 来规范化某些层/所有层的输入,从而可以固定每层输入信号的均值与方差”就可以解决问题。如果 covariate shift 可以用这么简单的方法解决,那前人对其的研究也真真是白做了。此外,试想,均值方差一致的分布就是同样的分布吗?当然不是。显然,ICS 只是这个问题的“包装纸”嘛,仅仅是一种 high-level demonstration。
❞
MIT 的同学在 NIPS 2018 发表了一篇论文《How Does Batch Normalization Help Optimization?》,该论文阐述了 BN 优化训练的并不是因为缓解了 ICS,而是对目标函数空间增加了平滑约束,从而使得利用更大的学习率获得更好的局部优解。
首先作者做了一个有无 BN 的实验:
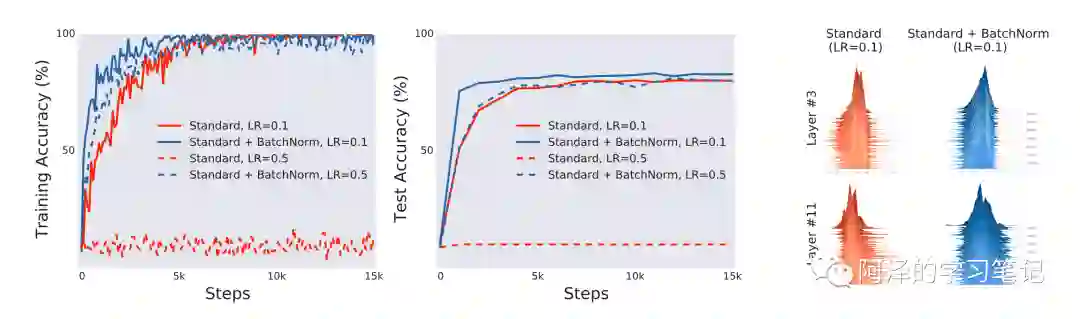
从上面左图可以看到 BN 收敛速度更快、准确率更高。而右图则说明 Standard 的参数均值不位于 0,而 BN 的参数都位于 0,这便是 ICS 的来源。
做过以上观察,作者提出了两个问题:
-
BN 的作用是否与控制 ICS 有关? -
BN 是否可以消除 ICS?
首先来看第一个问题。
如果 BN 的作用与控制 ICS 有关,那么如果在 BN 后人为的制造 ICS 则可以破坏 BN 的作用。
于是作者在 BN 后加入了随机噪声,从而使得网络中出现 ICS,下图为实验结果:
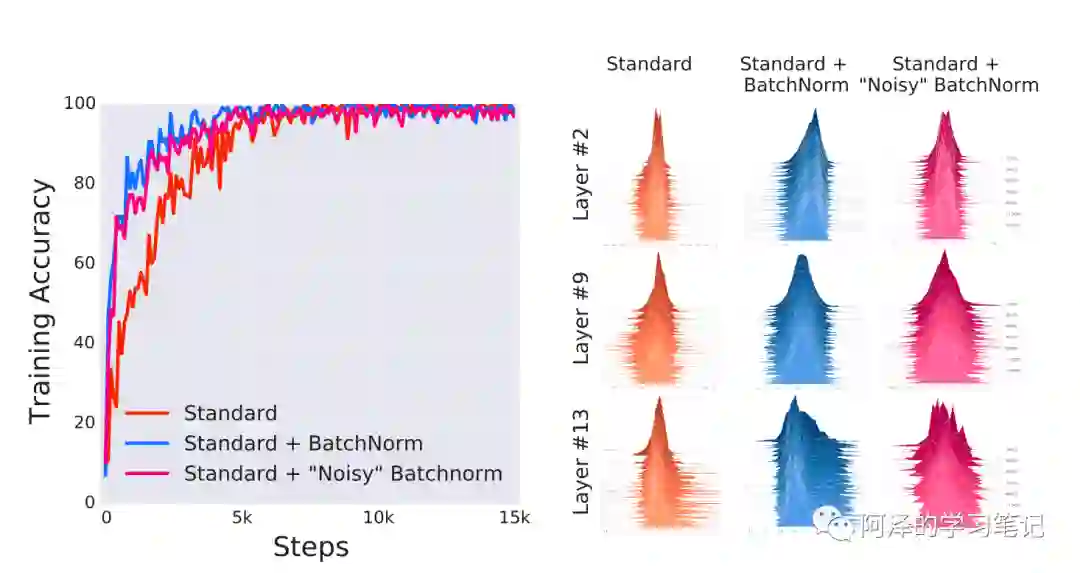
实验结果表明虽然加入了随机噪声的 BN 的 ICS 问题更加严重,但是它的性能是要优于没有使用 BN 的普通网络的。
然后我们再来看第二个问题。
作者首先给出 ICS 的定义。
「定义」:假设 为损失函数, 为 t 时的参数值, 是在 t 时刻的输入特征和标签值,ICS 定义为在时间 t 时,第 i 个隐层节点的两个变量的距离 ,其中:
有两个度量指标,一个是欧氏距离,值越小说明 ICS 越小,另一个是相似度指标 cos 值,值越接近 1 说明 ICS 越小。实验结果如下图所示:
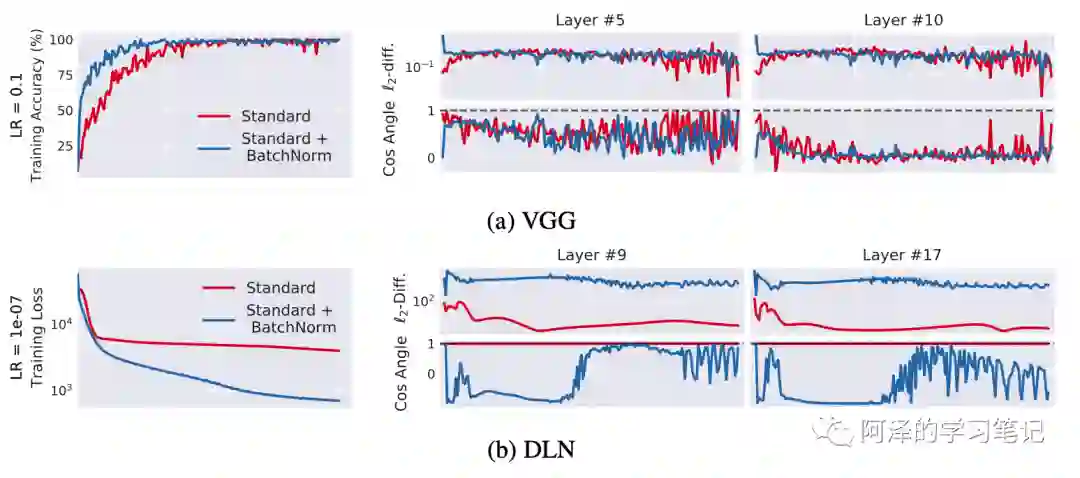
可以看到 BN 可以加快模型收敛并取得更好的效果,但 BN 并不能减少 ICS,反而还会有一定程度上的增加。
也就是说,BN 无法作用与 ICS,也无法减少 ICS,那么 BN 的是因为什么而提升性能的呢?
作者指出,BN 和 ResNet 的作用类似,都使得 loss landscape 变得更加光滑了:
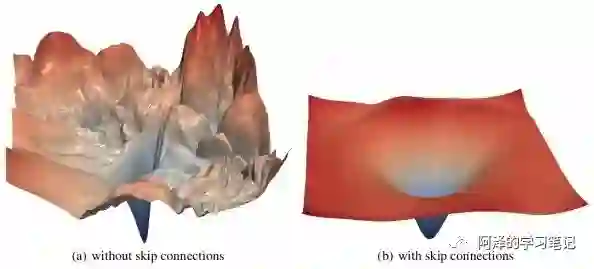
不光滑的 loss landscape 不利于训练,所以需要设计好的学习率和初始值。
下图为实验结果:
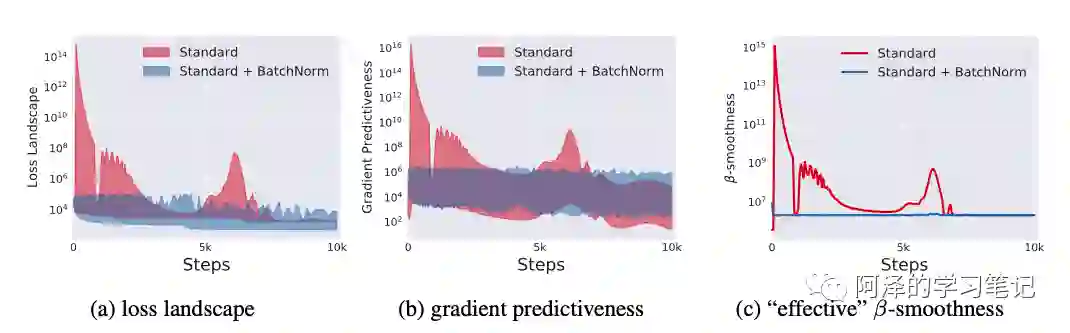
既然了解到了 BN 的作用归结于 loss landscape,下一步自然就是以平滑 loss landscape 为准则来设计一个比 BN 更先进的算法。
于是作者使用了 ,利用 后数据就不服从高斯分布了,ICS 现象也更加严重,但是结果更好:
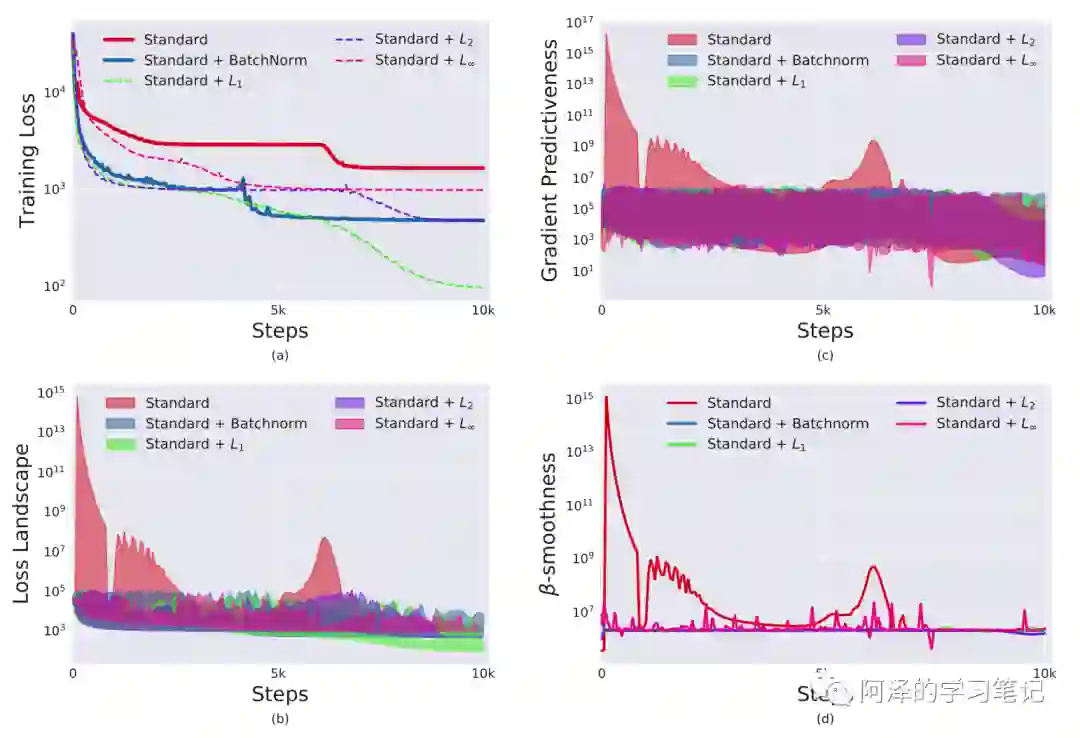
6.Conclusion
BN 是深度学习调参中非常好用的策略之一,有效的避免了梯度爆炸和梯度消失的问题。针对 BN 一些不适用的场景,研究学者也提出了 LN、IN、GN、WN 进行补充。
此外,MIT 的同学还对 BN 进行了详细的分析,指出 BN 具有良好表现的原因不在于控制或者减少 ICS,而是提供了更光滑的 loss landscape。
7.Reference
-
Ioffe S, Szegedy C. Batch normalization: Accelerating deep network training by reducing internal covariate shift[J]. arXiv preprint arXiv:1502.03167, 2015. -
《wiki/Feature scaling》 -
《深度学习中的Normalization模型》 -
《详解深度学习中的Normalization,BN/LN/WN》 -
《Batch Normalization原理与实战》 -
《深度学习中 Batch Normalization为什么效果好?》 -
Ba, Jimmy Lei, Jamie Ryan Kiros, and Geoffrey E. Hinton. "Layer normalization." arXiv preprint arXiv:1607.06450 (2016). -
Ulyanov, Dmitry, Andrea Vedaldi, and Victor Lempitsky. "Instance normalization: The missing ingredient for fast stylization." arXiv preprint arXiv:1607.08022 (2016). -
Wu Y, He K. Group normalization[C]//Proceedings of the European conference on computer vision (ECCV). 2018: 3-19. -
Salimans T, Kingma D P. Weight normalization: A simple reparameterization to accelerate training of deep neural networks[C]//Advances in neural information processing systems. 2016: 901-909. -
Santurkar S, Tsipras D, Ilyas A, et al. How does batch normalization help optimization?[C]//Advances in Neural Information Processing Systems. 2018: 2483-2493.
推荐阅读
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧🙏


