MIT黑科技:无需视觉输入,立体声音频+摄像机元数据即可实现移动车辆定位
选自 arXiv
声音在物体定位中会起到非常重要的作用,人们甚至可以利用自身对声音的感知来定位视线范围内的物体。在本文中,来自 MIT 计算机科学与人工智能实验室、MIT-IBM 沃森人工智能实验室团队的研究者提出了一套利用无标记的视听数据来自监督学习的算法,仅依靠立体音频和摄像机元数据就可以在视觉参考坐标系中定位移动的车辆。
论文:https://arxiv.org/pdf/1910.11760.pdf
项目链接:http://sound-track.csail.mit.edu/
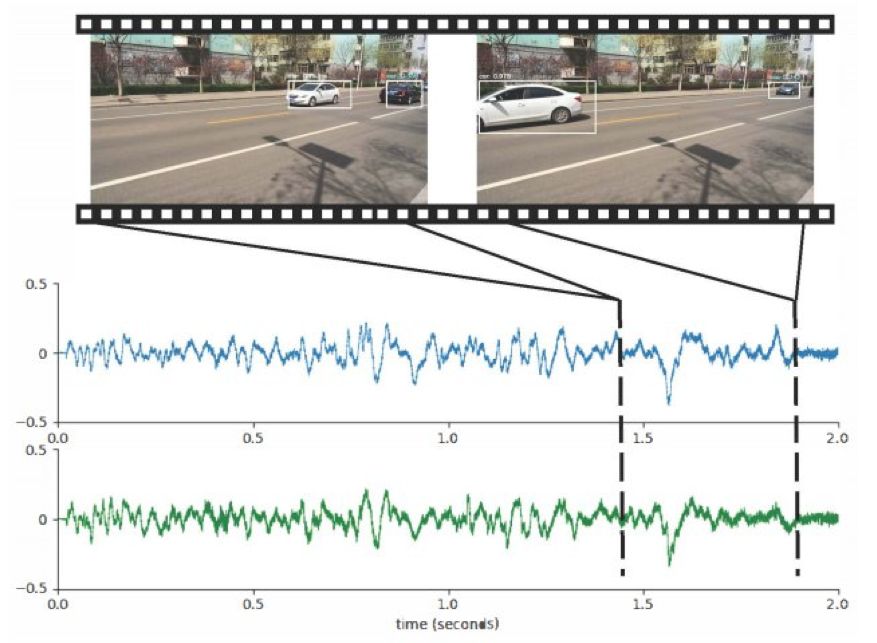
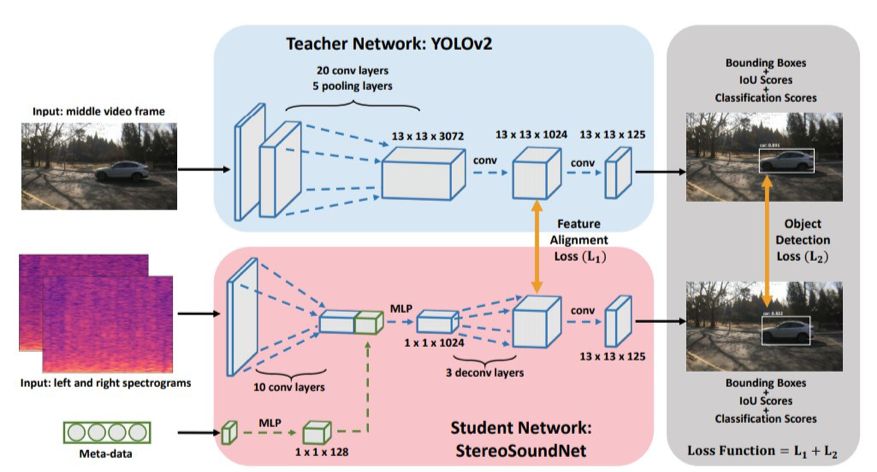
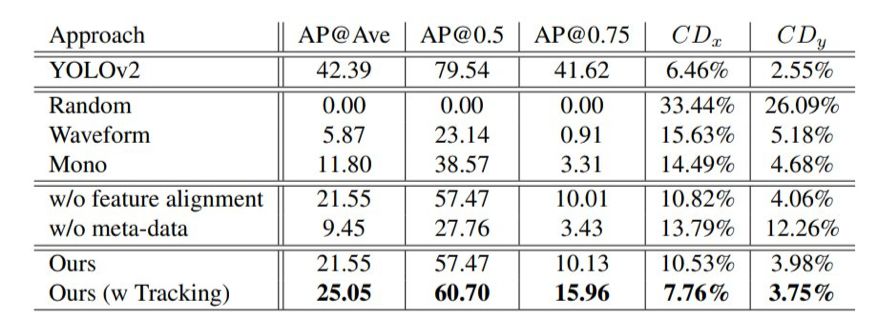
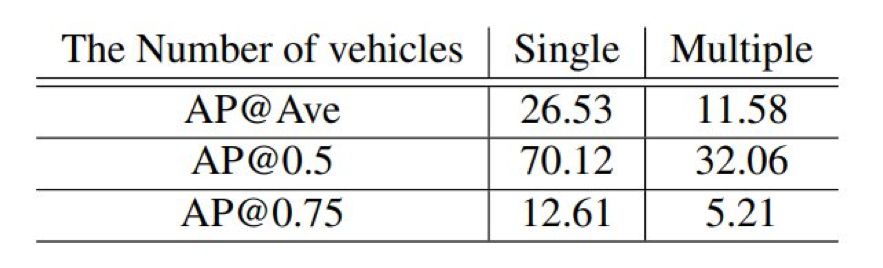
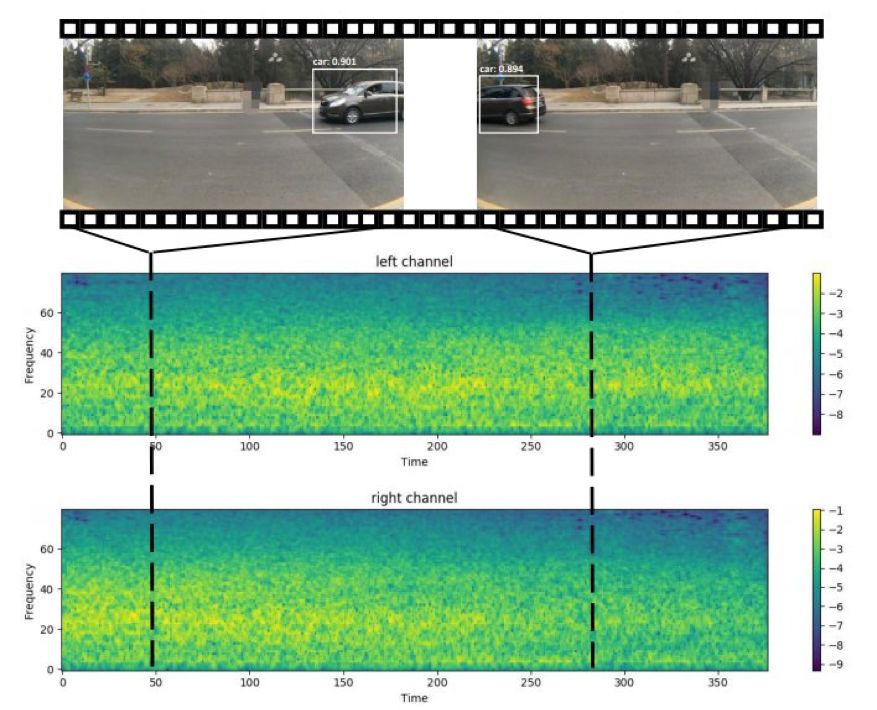

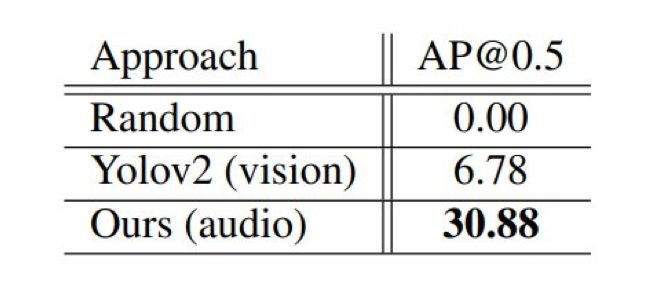

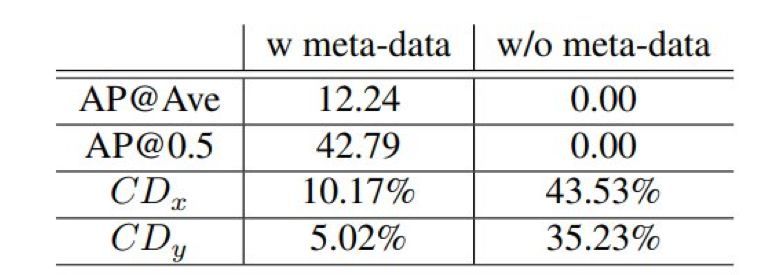

登录查看更多
相关内容

专知会员服务
24+阅读 · 2020年4月4日
Arxiv
5+阅读 · 2019年2月25日
Arxiv
4+阅读 · 2018年4月13日


相关VIP内容
专知会员服务
24+阅读 · 2020年4月4日
相关资讯
相关论文
Arxiv
5+阅读 · 2019年2月25日
Arxiv
4+阅读 · 2018年4月13日