透过新视角理解深度学习中的泛化


文 / Google Research 团队 Hanie Sedghi 和哈佛大学 Preetum Nakkiran
如何理解泛化是深度学习领域尚未解决的基础问题之一。为什么使用有限训练数据集优化模型能使模型在预留测试集上取得良好表现?这一问题距今已有 50 多年的丰富历史,并在机器学习中得到广泛研究。如今有许多数学工具可以用来帮助研究人员了解某些模型的泛化能力。但遗憾的是,现有的大多数理论都无法应用到现代深度网络中,这些理论在现实环境中显得既空泛又不可预测。而理论和实践之间的差距 在过度参数化模型中尤为巨大,这类模型在理论上能够拟合训练集,但在实践中却不能做到。
丰富历史
https://courses.engr.illinois.edu/ece544na/fa2014/vapnik71.pdf
数学工具
https://papers.nips.cc/paper/1996/file/fb2fcd534b0ff3bbed73cc51df620323-Paper.pdf
过度参数化
https://www.pnas.org/content/pnas/116/32/15849.full.pdf
在《Deep Bootstrap 框架:拥有出色的在线学习能力即是拥有出色的泛化能力》(The Deep Bootstrap Framework: Good Online Learners are Good Offline Generalizers)(收录于 ICLR 2021)这篇论文中,我们提出了一个解决此问题的新框架,该框架能够将泛化与在线优化领域联系起来。在通常情况下,模型会在有限的样本集上进行训练,而这些样本会在多个训练周期中被重复使用。但就在线优化而言,模型可以访问无限的样本流,并且可以在处理样本流的同时进行迭代更新。在这项研究中,我们发现,能使用无限数据快速训练的模型,它们在有限数据上同样具有良好的泛化表现。二者之间的这种关联为设计实践提供了新思路,同时也为从理论角度理解泛化找到了方向。
《Deep Bootstrap 框架:拥有出色的在线学习能力即是拥有出色的泛化能力》
https://arxiv.org/abs/2010.08127


Deep Bootstrap 框架的主要思路是将训练数据有限的现实情况与数据无限的“理想情况”进行比较。它们的定义如下:
现实情况(N、T):使用来自一个分布的 N 个训练样本训练模型;在 T 个小批量随机梯度下降 (SGD) 步骤中,照常在多个训练周期中重复使用这 N 个样本。这相当于针对经验损失(训练数据的损失)运行 SGD 算法,这是监督学习中的标准训练程序。
理想情况(T):在 T 个步骤中训练同一个模型,但在每个 SGD 步骤中使用来自分布的新样本。也就是说,我们运行相同的训练代码(相同的优化器、学习速率、批次大小等),但在每个训练周期中采用全新的训练样本集,而不是重复使用相同的样本。理想情况下,对于一个几乎达到无限的“训练集”而言,其训练误差和测试误差之间相差无几。
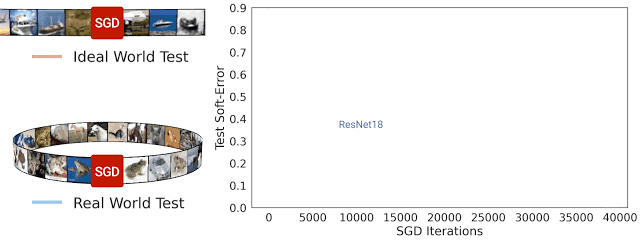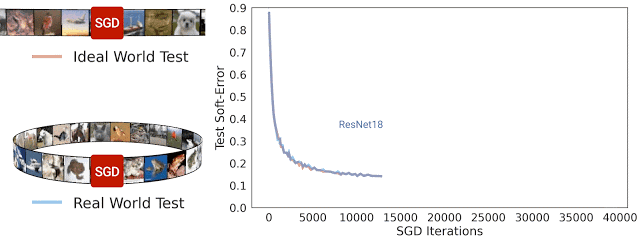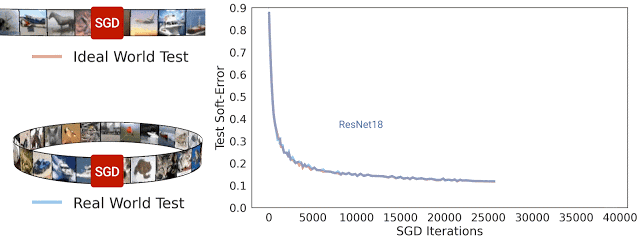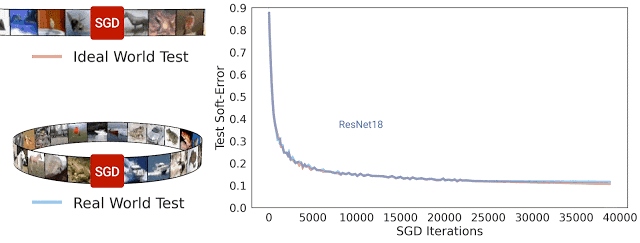
在 SGD 迭代期间 ResNet-18 架构理想情况及现实情况的测试软误差。可以看到,两种误差非常相近
一般而言,我们认为现实情况和理想情况不会有任何关联,因为在现实世界中用于模型处理的来自分布的示例数量是有限的,而在理想世界中模型处理的示例数量是无限的。但在实践中,我们发现现实情况模型和理想情况模型之间的测试误差非常相近。
为了将此观察结果量化,我们通过创建一个名为 CIFAR-5m 的数据集模拟了一种理想情况。我们使用 CIFAR-10 训练了一个生成模型,然后利用该模型生成约六百万个图像。选择生成这么多图像的目的是为了使此数据集对于模型而言具有“近乎无限性”,从而避免模型重复采样相同的数据。也就是说,在理想情况下,模型面对的是一组全新的样本。
CIFAR-5m
https://github.com/preetum/cifar5m
生成模型
https://arxiv.org/abs/2006.11239

来自 CIFAR-5m 的样本
下图给出了几种模型的测试误差,对比了它们在现实情况(如重复使用数据)和理想情况(使用“全新”数据)中使用 CIFAR-5m 数据训练的表现。蓝色实线展示了 ResNet 模型在现实情况下使用标准 CIFAR-10 超参数针对 50000 个样本训练 100 个周期的表现。蓝色虚线展示了同样的模型在理想情况下使用五百万个样本一次性训练完毕的表现。出人意料的是,现实情况和理想情况下的测试误差非常接近,在某种程度上模型并不会受到样本是重复使用还是全新的影响。
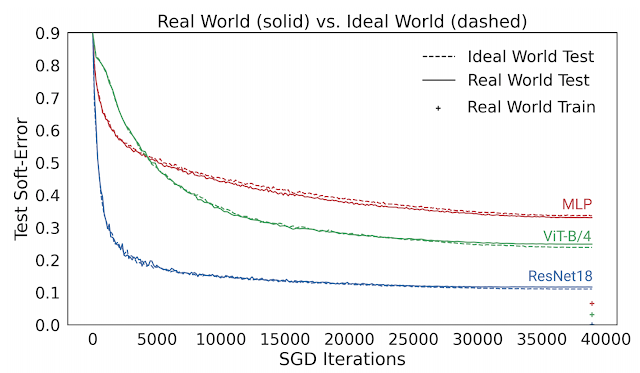
现实情况下的模型使用 50000 个样本训练 100 个周期,理想情况下的模型使用五百万个样本训练一个周期。图中的线展示了测试误差以及 SGD 步骤的执行次数
这个结果也适用于其他架构,如多层感知架构(红线)、视觉 Transformer(绿线),以及许多其他架构、优化器、数据分布和样本大小设置。从这些实验中,我们得出了一个关于泛化的新观点,即能使用无限数据快速优化的模型,同样能使用有限数据进行良好的泛化。例如,ResNet 模型使用有限数据进行泛化的能力要优于 MLP 模型,其原因在于 ResNet 模型使用无限数据进行优化的速度更快。
多层感知
https://www.iro.umontreal.ca/~vincentp/ift3395/lectures/backprop_old.pdf
我们从中得出一个重要的观察结果,即直到现实情况开始收敛前,现实情况和理想情况下的模型在所有时刻的测试误差都非常接近(训练误差 < 1%)。因此,我们可以通过研究模型在理想情况下的行为来理解它们在现实情况下的表现。
也就是说,模型的泛化可以通过研究其在两种框架下的优化表现来理解:
1. 在线优化:其用于在理想情况下观察测试误差的减小速度
2. 离线优化:其用于在现实情况下观察训练误差的收敛速度
因此,研究泛化时,我们可以相应地研究上述两个方面,它们仅涉及优化问题,因此在概念上较为简单。通过这项观察,我们发现出色的模型和训练程序均符合两个条件:(1) 能在理想情况下快速优化;(2) 在现实情况下的优化速度较慢。
所有深度学习设计方案都能通过了解它们在这两方面的表现来进行评估。例如,一些改进,比如卷积、残差连接和预训练等,其主要作用是加速理想情况的优化,而另一些改进,比如正则化和数据增强等,其主要作用则是减慢现实情况的优化。
预训练
https://papers.nips.cc/paper/2015/file/7137debd45ae4d0ab9aa953017286b20-Paper.pdf
正则化
https://jmlr.org/papers/volume15/srivastava14a.old/srivastava14a.pdf
研究人员可以使用 Deep Bootstrap 框架来研究和指导深度学习设计方案。它所依循的原则是:每当我们做出影响现实情况泛化能力的更改时(架构、学习速率等),我们都应考虑它对以下两方面带来的影响:(1) 理想情况的测试误差优化(越快越好)以及 (2) 现实情况的训练误差优化(越慢越好)。
例如, 预训练在实践中通常用于促进小数据体系中的模型泛化。然而,人们对预训练发生作用的机理知之甚少。我们可以使用 Deep Bootstrap 框架,通过观察预训练对上述两方面形成的影响研究这个问题。我们发现,预训练的主要作用是促进理想情况的优化 (1),即使网络能够“快速学习”在线优化。预训练模型泛化能力的增强几乎总能带来其在理想情况下优化能力的提高。下图比较了使用 CIFAR-10 训练的视觉 Transformers (ViT) 在 ImageNet 上从零开始训练和预训练之间的差别。
ImageNet
http://www.image-net.org/
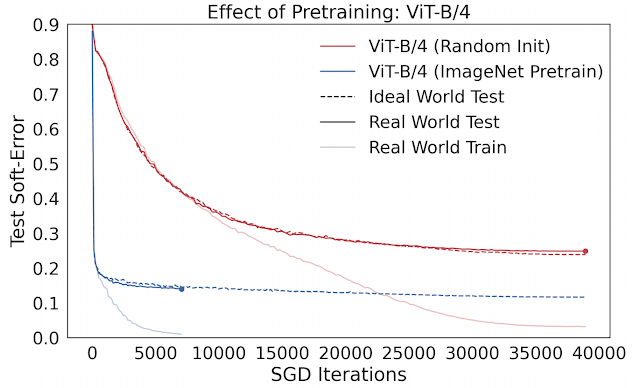
预训练的作用:经过预训练的 ViT 在理想情况下的优化速度更快
我们还可以使用此框架研究数据增强。在理想情况下的数据增强相当于对每个新样本进行一次增强,而不是对同一个样本进行多次增强。此框架意味着好的数据增强均符合两个条件:(1) 不会严重损害理想情况的优化(即增强样本的分布不会过于“失范”),(2) 抑制现实情况的优化速度(以使现实世界花更多时间拟合其训练集)。
数据增强的主要作用通过第二条:延长现实情况的优化时间来实现。关于第一条,一些激进的数据增强 (混合/剪切) 可能会对理想情况造成不良影响,但这种影响与第二条相比不值一提。
Deep Bootstrap 框架为理解深度学习的泛化和经验现象提供了一个新角度。我们非常期待能够在未来看到它被用于理解深度学习的其他方面。尤为有趣的是,泛化可以通过纯粹的优化方面的考量来描述, 这在理论上和许多主流方法相悖。至关重要的是,我们需同时考虑在线优化和离线优化,单独考虑二者中的任何一个都是不够的,它们共同决定了泛化能力。
主流方法
http://www.offconvex.org/2019/06/03/trajectories/
Deep Bootstrap 框架还揭晓了为什么深度学习对于许多设计方案都异常稳健,原因是许多中架构、损失函数、优化器、标准化和激活函数都具有良好的泛化能力。这个框架揭示了一个普适定律:基本上任何具有良好在线优化表现的设计方案,其都能在离线状态下有良好的泛化表现。
最后,现代神经网络既可能过参数化(如使用小型数据任务训练的大型网络),也可能欠参数化(如 OpenAI GPT-3、Google T5 或 Facebook ResNeXt WSL)。而 Deep Bootstrap 框架表明,在线优化是在这两种模式中取得成功的关键因素。
感谢我们的合著者 Behnam Neyshabur 对论文的巨大贡献以及对于博文的宝贵反馈。感谢 Boaz Barak、Chenyang Yuan 和 Chiyuan Zhang 对于博文及论文的有益评论。

点击“阅读原文”访问 TensorFlow 官网



