学界 | 信息论视角下的深度学习简述,形式化的泛化误差分析
选自arXiv
机器之心编译
参与:刘天赐、路
本论文从信息论的角度简要概述了深度学习,试图解决这两个问题:(1) 深度神经网络为什么比浅层网络的泛化能力好?(2) 是否在所有场景下,更深层的神经网络的效果都更好?
论文:An Information-Theoretic View for Deep Learning

论文链接:https://arxiv.org/abs/1804.09060
摘要:深度学习改变了计算机视觉、自然语言处理和语音识别领域。但还有两个依然模糊的关键问题:(1) 深度神经网络为什么比浅层网络的泛化能力好?(2) 是否在所有场景下,更深层的神经网络的效果都更好?具体而言,令 L 表示某一深度神经网络中的卷积层和池化层层数,n 表示训练样本量,我们可推导出此网络的期望泛化误差上界:

其中,σ>0 为常量,依赖于损失函数; 0<η<1 为另一常量,依赖于每个卷积或池化层上的信息损失(information loss);I(S,W) 为训练样本 S 和输出假设 W 间的互信息。据此上界可以得出:(1) 随着神经网络中卷积层和池化层个数 L 的增加,期望泛化误差呈指数下降至 0。带有严格信息损失的层(如卷积层),可以降低深度学习算法的泛化误差;这回答了上文中的第一个问题。但是,(2) 算法的期望泛化误差为 0 并不意味着测试误差或 E[R(W)] 很小,因为随着层数增加,用于拟合数据的信息发生损失时,E[R_S(W)] 会增大。这表明「神经网络越深越好」的说法仅在测试误差或 E[R_S(W)] 较小的条件下成立。(3) 我们进一步展示了深度学习算法满足稳定性的弱概念;随着 L 的增加,深度学习算法的样本复杂度会降低。
我们研究了统计学习的标准框架,其中 Z 表示示例空间(instance space),W 表示假设空间(hypothesis space),n 元组 S = (Z_1, Z_2, ..., Z_n) 表示训练样本,所有元素 Z_i 为从未知分布 D 中抽样得到的独立同分布样本。学习算法 A : S → W 可以理解为从训练样本空间 Z^n 到假设空间 W 上的随机映射。利用马尔科夫核 P_W|S 来描述学习算法 A:给定训练样本 S,算法根据条件分布 P_W|S 从 W 中抽取一个假设。
我们引入损失函数 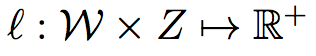
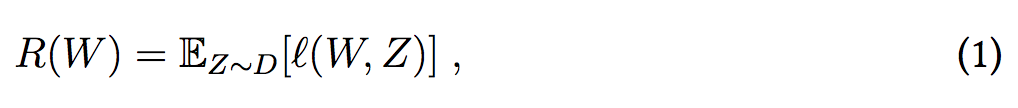
将经验风险(empirical risk)定义为:
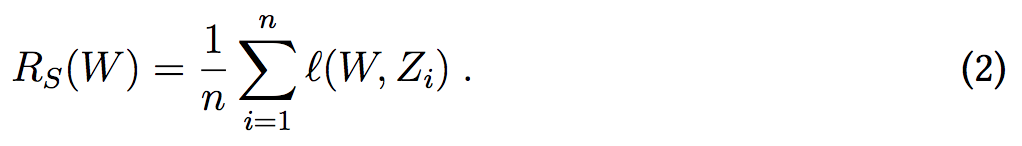
对学习算法 A,我们定义泛化误差:
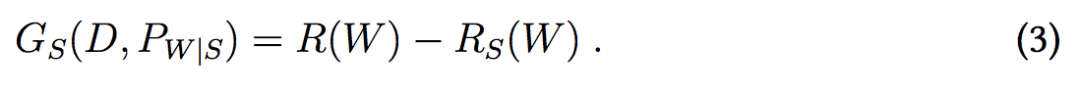
泛化误差很小表示学得的假设在训练数据集和测试数据集上表现接近。
在本文中,我们研究了深度学习算法的期望泛化误差,如下:
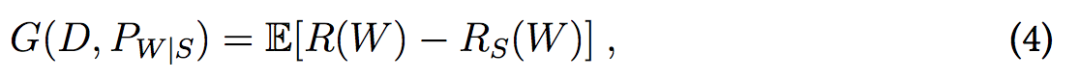
该期望在联合分布 P_W,S = D^n × P_W|S 上。
我们可得到以下分解:
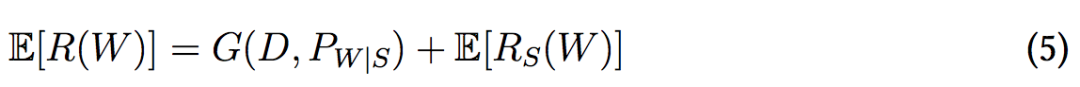
等式右侧第一项为期望泛化误差,第二项则反映了在期望的角度下,学得假设对训练样本的拟合程度。
在设计学习算法时,我们希望期望风险的期望 E[R(W)] 越小越好。但通常,很难同时令期望泛化误差 G(D,P_W|S) 和期望经验风险 E[R_S(W)] 都很小:如果某个模型对训练样本的拟合过于好,则它在测试数据上的泛化能力就可能很差,这就是「偏差-方差权衡问题」(Domingos, 2000)。惊人的是,根据实证经验,深度学习算法能够很好地同时最小化 G(D, P_W|S) 和 E[R_S(W)]。深度网络的深层架构能够有效地紧凑表征高变函数(highly-varying function),进而令 E[R_S(W)] 很小。但关于期望泛化误差 G(D, P_W|S) 能够保持很小的原因的理论研究依然不明确。
在本文中,我们从信息论角度出发研究深度学习算法的期望泛化误差。我们证明了随着层数增加,期望泛化误差 G(D, P_W|S) 会呈指数下降至 0。在定理 2 中,我们证明了:

其中,L 是深度神经网络中的信息损失层层数;0<η<1 为另一常量,依赖于每个卷积层和池化层上的信息损失;σ>0 为常量,依赖于损失函数;n 为训练样本 S 的样本量大小;I(S, W) 为输入训练样本 S 和输出假设 W 间的互信息。
此结论来自于两个和信息论相关的重要结果。第一个结果是来自于 Ahlswede 和 Gács 1976 年提出的强数据处理不等式(Strong Data Processing Inequalities,SDPI):对于马尔科夫链 U → V → W,如果在映射 V → W 中存在信息损失,则 I(U, V ) ≤ ηI(U, W),其中 η<1,为非负信息损失因子。第二个结果来自于 (Russo and Zou 2015, Xu and Raginsky 2017):对于某个学习算法,输入和输出间的互信息决定了该学习算法的泛化误差。
我们的结果与「偏差-方差权衡问题」并不冲突。尽管随着信息损失层层数增加,期望泛化误差呈指数下降至 0;但由于信息损失不利于拟合训练样本,因此期望经验风险 𝔼[R_S(W)] 会有所增加。这意味着,在设计深度学习算法时,需要更多地关注信息损失和训练误差之间的平衡。
利用输入和输出间的互信息来限制期望泛化误差的范围具有一个好处,它几乎依赖于学习算法的所有方面:数据分布、假设类的复杂度,以及学习算法本身的性质;而证明 PAC 可学习性的传统框架 (Mohri et al. 2012) 则只覆盖了其中一部分方面。如基于 VC 维 (Vapnik 2013)、覆盖数 (Zhang 2002),Rademacher (Bartlett and Mendelson 2002, Bartlett et al. 2005, Liu et al. 2017)、PAC-Bayes (Langford and Shawe-Taylor 2003)、算法稳定性 (Liu et al. 2017, Bousquet and Elissee 2002) 以及稳健性 (Xu and Mannor 2012) 的框架。
本文其余部分组织结构如下:在第二部分,我们在 DNN 和马尔科夫链之间建立了联系;第三部分利用强数据处理不等式推导出深度神经网络中的中间特征表征和输出之间的互信息变化;第四部分给出了主要研究结果:DNN 中基于深度 L 的指数极泛化误差上界;第五部分为主要定理的证明;第 6 部分是总结。
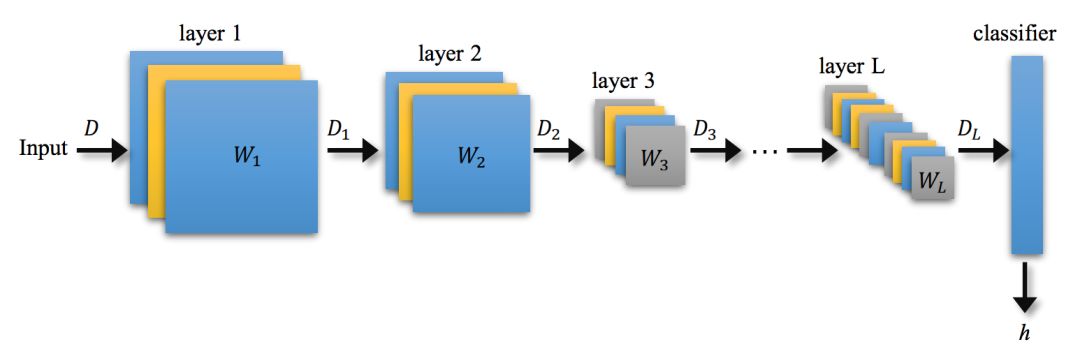
图 1:包含 L 个隐藏层的深度神经网络的层级特征图。
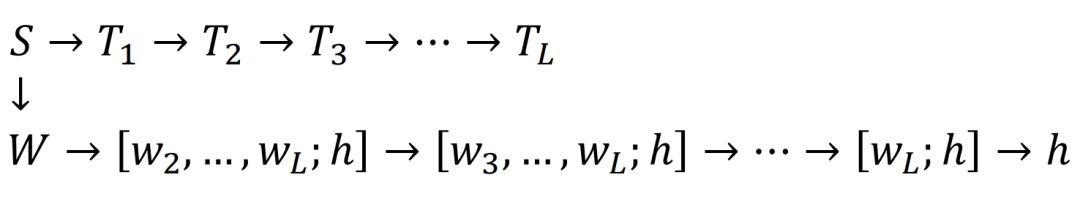
图 2:深度神经网络的特征图构成了一个马尔科夫链。
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com

