【NSR特别专题】香港科技大学杨强:多任务学习概述

编者按:《国家科学评论》于2018年1月发表“机器学习”特别专题,由周志华教授组织并撰写文章。专题内容还包括对AAAI前主席Tom Dietterich的访谈,徐宗本院士、杨强教授、朱军博士、李航博士、张坤博士和Bernhard Scholkopf等人的精彩文章。本文是香港科技大学杨强教授和张宇助理教授对多任务学习的系统性梳理和介绍。本文是对张宇、杨强所写的《多任务学习概述》的全文翻译。
多任务学习概述
作者:张宇, 杨强
翻译:宋平,雷智文,刘市祺
校译:叶奎
摘要
多任务学习(Multi-Task Learning,MTL)是机器学习中一个非常有前景的方向,旨在通过利用多个相关的学习任务之间的有效信息来提升它们的性能。在本文中,我们对MTL进行了综述,首先给出MTL的定义。然后介绍几种不同类型的MTL,包括多任务监督学习,多任务非监督学习,多任务半监督学习,多任务主动学习,多任务强化学习,多任务在线学习和多任务多视角学习。对于每种类型都会介绍其典型的MTL模型。还介绍了可加速多任务学习的并行和分布式MTL模型。在许多领域(包括计算机视觉,生物信息学,健康信息学,语音,自然语言处理,网络应用和普适计算)都通过使用MTL来提升性能,本文对一些有代表性的工作也进行了综述。最后,本文对最近MTL相关的理论分析进行了介绍。
关键词:多任务学习
1 引言
机器学习(利用历史数据学习有效信息,再用这些有效信息来帮助分析未来数据)通常需要大量有标签数据来训练一个性能良好的学习器。深度学习是机器学习中一个典型的学习器,它是有许多隐含层和大量参数的神经网络。这种模型通常需要大量的数据样本才能学习到准确的参数。然而,在一些场合,比如医疗图像分析,由于需要大量的人力标注数据,所以数据量无法满足要求。在这种情况下,利用从相关学习任务中得到的有用信息,从而缓解数据稀疏性问题的MTL方法是一种不错的选择。
MTL是机器学习中一个非常有前景的方向,旨在通过利用包含在多个学习任务中的有效信息来为每一个任务学习到一个更准确的模型。MTL基于这样的假设:在所有任务中,至少它们中的某个子集是有相关性的,联合学习多个任务,在经验上和理论上均可发现比单独学习每个任务都有更好的表现。基于任务的性质,MTL可以被分为以下几类:多任务监督学习、多任务非监督学习、多任务半监督学习、多任务主动学习、多任务强化学习、多任务在线学习。在多任务监督学习中,每个任务可以是分类任务也可以是回归任务,都是通过给定一个包含训练数据样本和对应标签的训练数据集来预测未知数据样本的标签。在多任务非监督学习中,单个任务一般是聚类问题,其旨在从只包含有训练数据样本的训练数据集中发现有用的模式。在多任务半监督学习中,单个任务与多任务监督学习中的任务类似,区别在于训练集中既有带标签数据也有无标签的数据。在多任务主动学习中,每个任务利用无标签数据辅助有标签数据学习,与多任务半监督学习类似但使用的方法不同,多任务主动学习是从无标签数据样本中挑选样本然后主动查询他们的标签。在多任务强化学习中,每个任务旨在选择动作以最大化累积奖励。在多任务在线学习中,每个任务处理序列数据。在多任务多视角学习中,每个任务处理多视角数据(多组特征描述一个样本)。
MTL可以被看成一种机器模仿人类学习活动的方法,因为当任务相关时人们通常把一个任务中获得的知识迁移到另一个任务,反之亦然。以我们自己的经验为例,打壁球和打网球是相辅相成的。与人类学习类似,从一个任务中获得的经验可以用到其他相关任务中,所以同时学习多个任务是有益的。
MTL与在机器学习中其他方法类似,比如迁移学习[2],多标签学习[3]和多输出回归,但有其不同的特点。比如,与MTL类似的迁移学习,也是侧重于把从一个任务学到的知识迁移到另一个任务中,区别在于迁移学习希望使用一个或多个任务帮助目标任务,而MTL中的多个任务彼此互相帮助。当多任务监督学习中的不同任务共享训练数据时,就变成了多标签学习或多输出回归。在这种情况下,MTL可以视为多标签学习和多输出回归的扩展。
在本文中,我们对MTL进行了综述。首先,我们定义MTL;然后基于每个学习任务的性质,我们讨论不同类型的MTL,包括多任务监督学习、多任务非监督学习、多任务半监督学习、多任务主动学习、多任务强化学习、多任务在线学习、多任务多视角学习。对于每种类型都会介绍其典型的MTL模型。当任务数量巨大或不同任务的数据分布于不同设备时,并行和分布式MTL变得必不可少,本文介绍了几种该类型的模型。作为一个有前景的学习范式,MTL已经应用于许多领域,比如包括计算机视觉、生物信息学,健康信息学、语音、自然语言处理、网络应用和普适计算,本文对有代表性的应用也进行了综述。最后,本文综述了MTL的理论,以加深我们对其的理解。
本文剩余部分结构如下。“MTL”部分介绍了MTL的定义。“多任务监督学习”部分到“到任务多视角学习”部分综述了不同类型的MTL,包括多任务监督学习、多任务非监督学习、多任务半监督学习、多任务主动学习、多任务强化学习、多任务在线学习、多任务多视角学习。“并行与分布式MTL”部分介绍了并行与分布式MTL模型。“MTL的应用”部分展示了MTL是如何帮助其他领域的。“理论分析”部分专注于MTL的理论分析。最后,“结论”部分对全文进行了总结。
2 多任务学习
首先,我们给出多任务学习的定义。
定义1:(多任务学习)给定m个学习任务Ti, i=1,…,m,其中所有学习任务或他们中的一个子集是有相关性但不完全相同,MTL旨在通过利用包含于m个学习任务中的知识来促进每个任务学习。
基于此定义,我们可知在MTL中有两大基本要素。
第一个要素是任务相关性。任务相关性是对不同任务之间如何相关的理解,其将会嵌入到MTL模型的设计中,稍后会介绍到。
第二个要素是任务定义。在机器学习中,学习任务主要包括监督任务(分类和回归任务)、非监督任务(聚类)、半监督任务、主动学习任务、强化学习任务、在线学习任务、多视角学习任务。不同的学习任务产生不同的MTL类型,这也是下面几部分关注的。在以下几部分中,我们会介绍不同类型MTL中的经典模型。
2.1 多任务监督学习
(Multi-Task Supervised Learning, MTSL)
多任务监督学习类型是指MTL中每个任务都是监督学习任务(建立数据样本与标签之间的函数映射模型)。在数学上表示为,假设有m个监督学习任务Ti, i=1…m,每个监督任务对应一个训练数据集D(x,y),其中包含n个数据,每个数据样本x有d维,y是x的标签,所以对于第i个任务Ti,有n个数据样本和标签对。当y处于连续空间中或是等价的实数标量,对应任务就是回归任务,如果y是离散的,比如y=1或-1,则对应的学习任务是分类任务。MTSL旨在从训练集中为m个任务学习到m个能充分近似y的方程f(x)。学习到m个方程后,MTSL使用m个方程分别为m个任务预测未知数据样本的标签。
如之前讨论那样,任务相关性的理解影响了MTSL模型的设计。现有的MTSL模型一般从三个方面反映任务的相关性:特征、参数、样本,对应产生三类MTSL模型:基于特征的MTSL模型,基于参数的MTSL模型,基于样本的MTSL模型。具体而言,基于特征的MTSL模型假设不同任务共享相同或相似的特征表达,可以是原始特征的一个子集或者是原始特征的变换。基于参数的MTSL模型旨在通过模型参数的正则化或先验把任务相关性编码进模型中。基于样本的MTSL模型提出通过对样本加权,利用所有任务的数据样本对每个任务建立一个学习器。接下来我们综述一下三类的代表模型。
2.2 基于特征的MTSL
(Feature-based MTSL)
在此类的所有方法中,MTL模型假设不同任务共享特征表达(由原始特征表达产生)。根据共享特征表达的获得方式不同,我们把MTL模型的构建方法分为三类,包括特征变换方法、特征选择方法、深度学习方法。特征变换方法通过对原始特征进行线性或非线性变换学到共享特征表达。特征选择方法假设共享的特征表达是原始特征的子集。深度学习方法利用深度神经网络学习共享的特征表达,对任务来说其编码于隐含层。
2.3 特征变换方法
(Feature transformation approach)
在此方法中,共享的特征表达由原始特征的线性或非线性变换得到。一个典型模型是多层前馈神经网络,如图1所示。此例中,多层前馈神经网络包括一个输入层,一个隐层,一个输出层。输入层有d个单元,分别从m个任务中接收数据样本作为输入,其中一个单元作为一个特征。隐含层包括多个非线性激活单元,接收输入层变换后的输出,该变换取决于输入层和隐层的连接权重。作为原始特征的变换,隐层的输出是所有任务共享的特征表达。隐层的输出首先经过隐层和输出层之间的连接权重变换,然后送入输出层,输出层有m个单元,每个单元对应一个任务。

图1:只有一个输入层,隐层和输出层的多任务前馈神经网络
与基于神经网络的多层前馈神经网络不同,多任务特征学习(MTFL)方法[5,6]和多任务稀疏编码方法(MTSC)[7]建立在正则化框架之下,首先变换样本数据x’=Ux,然后学习线性方程f(x)=Ax+b.基于此规则,我们可知这两种方法旨在学习一个线性变换U而不是一个像多层前馈神经网络似的非线性变换。不仅如此,MTFL和MTSC方法彼此也不同。比如,在MTFL方法中,U假定为正交矩阵,参数矩阵A=(a1,a2,,,am)经过L21正则化后是行稀疏的;然而MTSC方法中U是过完备的,即U中列数远大于行数,且A经过L1正则化后是稀疏的。
2.4 特征选择方法
(Feature selection approach)
特征选择方法旨在选择一个原始特征的子集作为不同任务间共享的特征表达。有两种方法进行多任务特征选择。第一种方法是基于对W=(w1,w2,…wm)的正则化,其中f(x)=Wx+b定义了任务Ti的线性学习方程。另一个方法是基于W的稀疏性概率先验。接下来我们详细介绍这两种方法。

2.5 深度学习方法
(Deep-learning approach)
与特征变换方法里的多层前馈神经网络模型相似,深度学习方法的基本模型包括高级的神经网络模型比如卷积神经网络和递归神经网络。然而,与多层前馈神经网络只有少量的隐含层(比如2-3层)不同,深度学习方法包括有数十或数百层隐含层的神经网络。不仅如此,与多层前馈神经网络类似,本类中大多数深度学习模型[18-22]把隐含层的输出看作共享的特征表达。与他们的方法不同,[23]中提出的交叉缝网络(cross-stitch network)把两个任务隐藏的特征表达构建为一个更强大的隐藏特征表达。比如,为两个任务给定两个有相同网络结构的深度神经网络A和B,xijA和xijB表示A,B网络包含在第i隐层第j单元的隐含特征,对xijA和xijB的交叉缝操作可以定义为:

其中x‘ijA和x’ijB表示两个任务经过联合学习后新的隐藏特征。矩阵S和两个网络的参数通过BP算法学习得到,因此该方法比直接共享隐层更灵活。
2.6 基于参数的MTSL
基于参数的MTSL使用模型参数关联不同任务的学习。根据不同任务的模型参数的关联方式我们将其分为5种方法,包括低秩方法,任务聚类方法,任务联系学习算法,脏方法(dirty approach)和多级方法。其中低秩方法处理因为假定任务彼此相关而使参数矩阵W很可能低秩的情况。任务聚类方法旨在把任务分为几个集群,每一集群中的任务使用相同或相似的模型参数。任务联系学习算法直接从数据中学习成对数据的关系。脏方法假定W矩阵分解为两个分量矩阵,每一个都经过稀疏方法正则化。作为脏方法的泛化,多级方法分解参数矩阵为两个以上的分量矩阵来建模所有任务之间的复杂关系。下面我们分别介绍这几种方法。
2.7 低秩法(Low-rank approach)

2.8 任务聚类方法
(Task-clustering approach)
任务聚类方法应用数据聚类算法的思想,将任务分成几个集群,每一个集群中的任务都有相似的模型参数。
第一个任务聚类算法是在[28]提出的,该算法剥离了任务聚类方法和模型的学习过程。具体来说,其首先根据模型参数将任务进行聚类,其中每个任务的模型参数是在单任务模式下独自学习到的,然后将该集群中任务的训练数据集中起来,为该任务集群中所有任务学习一个更精确的学习器。这种两步法可能不是最优的,原因在于从单任务环境下学习到的模型参数可能不准确,使得任务聚类步骤的结果不好。所以,后续研究的目标是同时确定任务集群和学习模型参数。
[29]中提出了基于混合高斯模型的模型参数的聚类任务(即连接隐藏层和输出层的权重)其结构类似于多层神经网络的多任务贝叶斯神经网络,如图1所示,[30]中使用狄利克雷过程(Dirichlet process)(广泛应用于贝叶斯学习中,用于数据聚类)用来做基于模型参数{wi}的任务聚类。

2.9 任务关系学习方法
(Task-relation learning approach)
在这种方法中,任务关系反映任务的相关性,任务关系包括任务相似性和协方差等等,这里仅举几例。
在早期的研究中,任务关系是通过模型假设[36,37]或者先验信息[38-41]定义的。但是这两种途径都既不理想,也不实际,因为模型假设很难在现实世界的应用中证实,并且先验信息很难获得。更先进的学习任务关系的方法是从数据中提取,这是本节的重点内容。
[42]提出一个多任务的高斯过程,用其定义一个先验函数fij,函数值与xij相关,写作f∼N(0,Σ),其中f =(f 11,….,f m nm)。矩阵Σ的元素对应于fij和f pq之间的协方差,定义为σ(fij,fpq)=ωipk(xij,xpq),其中k(·,·)定义为核函数,ωip为任务Ti和Tp之间的协方差。然后,给定f,基于标签的高斯似然函数,边缘似然函数有了具体的解析形式,可以用来学习Ω,任务协方差可以反映任务的相关性,其中(i,p)为ωip的元素。为了在使用贝叶斯平均时达到更好的性能,[43]中用多任务泛化的t过程代替了在Ω上的逆Wishart先验。
[44,45]提出了一种称为多任务相关学习方法(MTRL)的正则化模型,用于替代W W∼MN(0,I,Ω)的矩阵变量广义正态先验,其中MN(M,A,B)表示M为均值,A为行方差,B为列方差下的矩阵正态分布。该先验与正则化器tr(WΩ-1WT)相关,正则化器中PSD任务方差Ω需要满足条件tr(Ω)≤1。MTRL方法在[46]中被推广到多任务提升(multi-task boosting)中,在[47]中被推广到多标签学习(multi-label learning)中,采用的方法是将每个标签都看作是一个任务,在[48]中MRTL被扩展成能够学习稀疏任务关系。[49]提出了一种类似于MRTL的方法,这种方法给W 加上W∼MN(0,Ω1,Ω2)的先验,并且能够学习Ω1和Ω2之间的稀疏逆。由于MRTL方法中用到的先验,W^TW服从Wishart分布,即W(0,Ω),所以在[50]中,通过研究高阶先验(WTW)t ∼ W(0,Ω)(t为正整数),MTRL方法的得到了进一步推广。[51]通过将Ω假设为Ω-1=(Im-A)(Im-A)T的参数形式,提出了一种与MRTL中所用到的类似的正则化器,其中A为该文章中定义的不对称任务关系。与上述依靠全局学习模型的方法不同,局部学习方法,如k近邻(KNN)分类器在[ 52 ]中被用于MTL方法,学习函数定义为F(xij)=Σ(p,q)∈NK(I,J)σip S(xij,X pq)ypq,其中Nk(i,j)表示任务的集合和xi的k个最近邻实例指标,s(·,·)定义了实例之间的相似度,σip代表任务Tp与Ti之间的相似度。通过使σip不断靠近σpi,[52]提出一种正则化器||Σ-ΣT||2F来学习任务之间的相似度,其中,对于任意i≠p,σip需要满足σii≥0且|σip|≤σii
2.10 脏方法(Dirty approach)
脏方法假设参数矩阵W分解为W = U + V,其中U和V分别捕获任务相关性的不同部分。在这种方法中,不同模型的目标函数可以被联合用于减少对所有任务及两个正则器g(U)和h(V)的训练损失,其中两个正则化器是分别对应U和V。因此,该方法衍生出的方法的不同之处在于对g(U)和h(V)的选择方式不同。

表一:脏方法g(U)和h(V)的不同选择方法
这里我们介绍五种不同选择方法,如[53–57]所示。也就是表1中选择g(U)和h(V)的五种不同方法。根据表1,我们可以看到,[53,56]中关于g(U)的处理是分别通过l∞,1范数和l2,1范数使U低稀疏化。[54,55]中关于g(U)的选择是分别通过将迹范数作为正则化器和约束条件使U变成低秩的。与这些方法不同的是,[57]中通过Frobenius范数惩罚g(U)的复杂度,然后基于融合lasso正则器在不同任务中对特征进行聚类。对于V,h(V)可以通过l1范数对其进行稀疏化,这一点在[53,54]讨论过,也可以通过l2,1对其进行列稀疏化,这一点在[55,56]中讨论过。[57]中通过平方Frobenius范数来惩罚V的复杂度。
在分解过程中,U主要识别任务之间的关联性,类似与特征选择方法或低秩方法,而V能够通过稀疏性捕获噪声或偏差数据。U和V的结合可以使学习器更加强大。
2.11 多层次方法(Multi-level approach)
作为脏方法的推广,多层次方法分解参数矩阵W为h个分量矩阵{Wi}h i= 1,其中W=Σhi=1Wi,h大于等于2。下面,我们将展示多层次分解是如何帮助建模复杂的任务结构。
在任务聚类方法中,不同的任务集群通常没有重叠,这可能会限制最终学习器的表达能力。在[58]中,列举出了所有可能的任务集群,得到2^m-1个任务集群,它们组织成根结点为虚结点的树结构,树的父子关系是子集关系。这个树有2^m个结点,每一个对应一层,因此索引t既表示树中的一个结点,也表示对应层。为了处理有如此多节点的树,作者做了一个假设:如果集群无用,那么它所有的超级组(superset)都无用,这意味着如果树中一个结点无用,那么其所有子节点都无用。基于此假设,基于平方的Lp1范数的正则化项可设计为:
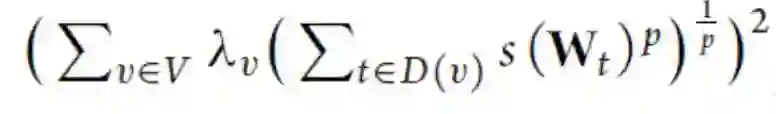
其中V表示树的结点集,_v是结点v的正则化参数,D(v)表示v的子节点。S(W_t)使用[36]提出的正则化项迫使W_t中不同列趋向其均值。不像[58]中每层包含任务的子集,[34]中提出的一个多层任务集群方法是基于结构性稀疏正则化项来
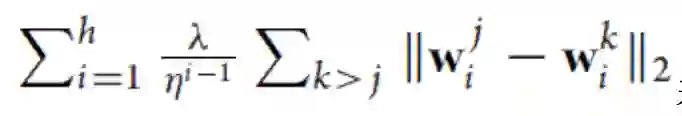
聚类所有任务。
在[59]中,每一个分量矩阵被假定为是同时稀疏和行稀疏的,但是稀疏比例不同,这与连续分量矩阵更相似。为此,可以构建一个正则化项:
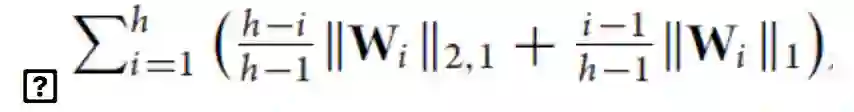
不像前面提到的方法那样不同的分量矩阵没有直接联系,在[60]中,在连续层中分量矩阵之间有直接的联系,任务之间复杂的级联/树结构可以从数据中学到。具体而言,在[34]的多层任务集群方法基础上,[60]提出了一个等式约束:
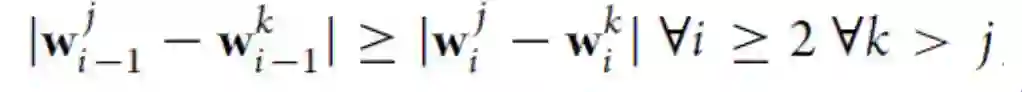
使其变为树形结构。
与脏方法的专注于识别噪声和异常值相比,多层方法能够建模更复杂的的任务结构,比如复杂任务集群和树形结构。
2.12 基于实例的MTSL
(Instance-based MTSL)
在本类中只有少数工作像[61]中提出的多任务分布匹配方法有代表性。具体而言,它首先估计每个样本是来自自己任务的概率和来自所有任务的混合集的概率之间的比例。在使用softmax方程确定比例后,这个方法使用该比例来决定样本权重,然后从所有任务的加权样本中为每个任务学习模型参数。
2.13 小结
基于特征的MTSL可以为不同任务学习一个共同的特征表达,更适合于原始特征表达的信息和区分性不足的场合,如计算机视觉、自然语言处理和语音方向。然而,基于特征的MTSL很容易的受与其他任务无关的异常任务影响,这是因为其难以从与其他任务无关的异常任务中学到共同的特征表达。给定一个好的特征表达,基于参数的MTSL可以学习到更准确的模型参数,而且通过模型参数的鲁棒表达可以对异常任务更鲁棒。因此基于特征的MTSL与基于参数的MTSL互补。基于实例的MTSL也是现在与其他两类方法同时正在研究探索的。
总之,MTSL类型方法是MTL研究中最重要的一类,因为它为其他类型方法的研究搭建了舞台。在MTL现有的研究中,大约90%的工作研究MTSL类型,在MTSL类型中,多大部分人关注于基于特征和基于参数的MTSL方法。
3 多任务非监督学习
不像多任务监督学习中每个样本数据都有标签,在多任务非监督学习中,第i个任务的训练集Di只包括Ni个没有标签的数据样本,多任务非监督学习就是从Di中挖掘信息。典型的非监督学习任务包括聚类,降维,流形学习,可视化等,多任务非监督学习主要关注多任务聚类。聚类就是把一组数据分为几组,每组有相似的样本,因此多任务聚类旨在利用不同数据集中的有用信息在多个数据集上聚类。
多任务聚类方向的研究不多,在[62]中,提出了两个多任务聚类方法。这两个方法将MTSL类型中的MTFL和MTRL方法[5,44]扩展到了聚类场景,在提出的两个多任务聚类方法中的方程式几乎与MTFL和MTRL中的一模一样,唯一的区别在于标签被当做需要从数据中学习的未知集群指标。
3.1 多任务半监督学习
在许多应用中,数据通常需要大量的人力来标记,从而导致标记的数据数量不够多。但是在许多情况下,未标记数据很充足。因此在这种情况下,未标记数据也被用来提高监督学习的性能,这就产生了半监督学习。半监督学习的训练集混合了标记数据和未标记数据。在多任务的半监督学习里面的目标和半监督学习是相同的,也是利用未标记的数据来帮助提高监督学习的性能。然而不同的是,不同的监督任务共享有用的信息以互相帮助。
根据每个任务的性质,多任务半监督学习可以被分为两类:多任务半监督分类和多任务半监督回归。对于多任务半监督分类,在(63,34)中,基于松弛狄利克雷过程提出了一种遵循任务聚类的方法来完成多任务聚类,而在每个任务中,使用随机游走(random walk)来挖掘包含在未标记数据里面的有用信息。与(63,64)不同,(65)提出半监督多任务回归问题,在(65)中每个任务都符合高斯过程,未标记数据被定义为核函数,并且所有任务中的高斯过程共享核参数先验。
3.2 多任务主动学习
多任务主动学习的类型与多任务半监督学习几乎是相同的,每个任务都有少量的标记样本和大量的未标记样本,然而,不同于多任务半监督学习利用未标记数据中包含的信息,在多任务主动学习中,每个任务选择富含信息的未标记数据向“神谕”查询来主动获得标签,因此未标记数据选择的标准是多任务主动学习的重点(66-68)。
具体来说,[66]中提出了两个标准以确保选择的未标记数据对所有任务而不仅仅是其中一个都富含信息。与[66]不同,在[67]中每个任务的学习器都是一个有监督的隐狄利克雷分配模型(spervised latent Dirichlet allpcation model),未标记数据选择的标准是减少预期错误。 此外,文献[68]提出了一种选择策略,即基于迹范数正则化器的低秩MTL模型的学习风险与类似于多臂赌博机(multi-armed bandits)的置信界限之间的权衡。
3.3 多任务强化学习
受到行为心理学的启发,强化学习研究如何在环境中采取行动以获得最多的累积奖励,并且在许多实际应用中显示了良好的性能,例如在作为代表性的Alpha Go应用中,Alpha Go在围棋游戏中击败了人类。 当环境相似时,不同的强化学习任务可以使用类似的策略来作出决定,这就是多任务强化学习的动机[69-73]。
具体来说,在[69]中,每个强化学习任务都是通过马尔科夫决策过程(MDP)建模的,并且所有任务中,不同马尔科夫决策过程通过分层贝叶斯无限混合模型(hierarchical Baysain infinate mixture)彼此相关。 在[70]中,每个任务都是通过区域化策略来表征的,同时,狄利克雷过程被用在聚类任务中。 在[71]中,每个任务的强化学习模型是高斯过程时间差值价值函数模型(Gaussian process temporal difference value function),层次贝叶斯模型将不同任务的价值函数关联起来。[72]中假设不同任务中的值函数共享稀疏参数,并将带有L2,1正则化[8]的多任务特征选择方法和MTFL方法[5]应用于同时学习所有的价值函数。[73]提出了一种演员-模拟方法(actor-mimic method),它是深度强化学习和模型压缩技术的结合,它的提出是用于学习多任务的策略网络。
3.4 多任务在线学习
当多个任务中的训练数据按顺序进入模型时,传统的MTL模型不能解决这个问题,但是多任务在线学习能够完成这项工作,一些代表性工作[74-79]所示。
具体而言,在[74,75]中,假定不同任务具有共同目标,全局损失函数,联合各个任务的损失函数,任务之间的关系度量,以及使用正范数的全局损失函数,一些MTL在线算法被提出。 在[76]中,所提出的MTL在线算法通过对所有任务采取的动作施加约束来建模任务关系。 在[77]中,针对多任务分类问题,提出了MTL在线算法,该算法采用感知器作为基本模型,并基于任务之间的共享几何结构来衡量任务关系。在 [78]中,提出了一种用于多任务高斯过程的贝叶斯在线算法,该过程在任务中共享核参数。[79]中为了使用MTRL方法[44],提出了一个在线算法,它同时更新模型参数和协方差。
3.5 多任务多视角学习
在计算机视觉问题等一些应用中,每个数据点可以用不同的特征表达表示来描述。以图像数据为例,它的特征提取方法包括SIFT和小波等。在这种情况下,每个特征表达被称为视角,因此提出多视角学习来处理这种具有多个视角的数据,它是机器学习中的一种学习范式。与监督学习类似,每个多视数据点通常与标签对应。多视角学习旨在利用包含在多个视角中的有用信息来进一步提高监督学习(可以被视为一个单视图学习范式)的性能。作为多视角学习的多任务扩展,多任务多视角学习[80,81]希望通过利用包含在相关任务的有用信息解决多视角学习问题,进而改善每个多视角学习问题的性能。具体而言,在[80]中,提出了第一个多任务多视角分类器,它利用了任务之间共享的公共视角的任务相关性和每个任务视角的视角一致性。在[81]中,每个任务中的不同视角对未标注的数据达成共识,因此可以学习不同的任务,其方法是利用如[38]中的先验信息或者像MTRL方法那样学习任务相关性。
3.6 并行和分布式MTL
当任务数量很大时,如果我们直接应用多任务学习器,计算复杂度可能很高。如今,由于出现了多CPU或多GPU架构,所以计算机的计算能力非常强大。所以我们可以利用这些强大的计算工具来设计并行MTL算法来加速训练过程。在[82]中,设计了一种并行MTL方法来解决MTRL模型的子问题[44],这也发生在许多属于任务相关性学习方法中的正则化方法中。具体而言,针对所有任务,该方法利用FISTA算法设计可分解的替代函数,该替代函数可以并行化以加速学习过程。此外,在[82]中研究了三种损失函数,包括转折点损失(hinge),不灵敏损失和平方损失,这些损失使得这个并行方法适用于MTSL中的分类和回归问题。
在某些情况下,针对不同任务的训练数据可能存储于不同的机器中,这使得传统的MTL模型难以工作,即使所有的训练数据都可以移动到一台机器上,也会产生额外的传输和存储成本。更好的选择是设计分布式MTL模型,这样可以直接操作分布在多台机器上的数据。[83]提出了一个基于无偏拉索模型(debiased lasso model)的分布式算法,通过一台机器学习一项任务的方式,该算法具有高效的通信能力。
4 MTL的应用
包括计算机视觉,生物信息学,健康信息学,语音,自然语言处理,网络应用以及普适计算等多个领域使用MTL来提高各自应用的性能。 在本节中,我们将回顾一些相关的工作。
4.1 计算机视觉
MTL在计算机视觉中的应用可以分为两类,包括基于图像的和基于视频的应用。
基于图像的MTL应用包括两子类:人脸图像和非人脸图像。具体来说,基于人脸图像的MTL应用包括人脸验证[84],个性化年龄估计[85],多线索人脸识别[86],头部姿势估计[22,87],人脸轮廓检测[18]以及人脸图像旋转[88]。基于非人脸图像的MTL的应用包括目标分类[86],图像分割[89,90],识别脑成像预测器[91],显著性检测[92],行为识别[93],场景分类[94], 多属性预测[95],多摄像头行人重识别[96],以及即时预测[97]。
基于视频的MTL应用包括视频追踪[98-100]和缩略图选择[19]。
4.2 生物信息学和健康信息学
MTL在生物信息学和健康信息学中的应用包括生物体建模[101],对治疗靶点反应的机制鉴定[102],跨平台siRNA功效预测[103],通过多种群的关联分析检测致病性遗传标记[104],个性化脑机接口构建[105],MHC-I结合预测[106],剪接位点预测[106],蛋白亚细胞定位预测[107],阿尔茨海默病评估量表认知亚量表[108],认知预测阿尔茨海默病神经影像学测量结果[109],阿尔茨海默病进展预后的纵向表型标记[110],疾病基因优先[111],基于自然图像的生物学图像分析[20],生存分析[ 112]和多重遗传预测[113]。
4.3 语音和自然语言处理
MTL在语音中的应用包括语音合成[114,115]和那些用于自然语言处理的应用包括6个NLP任务的联合学习(即部分语音标记,分块,命名实体识别,语义角色标注,语言建模和语义相关词),多模态情感分类[117],多模态对话状态跟踪[21],机器翻译[118],句法分析[118]和微博分析[119,120]。
4.4 网络应用
基于MTL的Web应用程序包括网络搜索[121],网络搜索排序[122],多模态协同滤波[123],行为定位[124],以及广告显示[125]中的转换最大化。
4.5 普适计算
MTL在普适计算中的应用包括股票预测[126],多设备定位[127],机器人逆动力学问题[128,129],旅途道路成本估计[130],道路旅行时间预测[131]和交通标志识别[132]。
4.6 理论分析
学习论是机器学习的一个领域,其研究包括MTL模型在内的学习模型的理论方面。接下来,我们将介绍一些有代表性的工作。
MTL的理论分析主要聚焦在推导MTL模型的泛化边界上。 众所周知,MTL模型在未知的测试数据的泛化性能是MTL和机器学习中主要关心的问题。然而,由于底层数据分布难以建模,泛化性能无法计算,取而代之,泛化边界用于估计泛化性能的上界。
[133]首次推导了一般性MTL的泛化上界。然后,有许多研究分析了不同MTL方法的泛化上界,包括例如 [7,134]的特征变换方法,[135]的特征选择方法,[24,135-138]的低秩方法,[136]的任务关系学习方法,[138]的肮脏算法。
5 结论
在本文中,我们对MTL(MTL)进行了概述。 首先,我们给出了一个MTL的定义。此后,本文介绍了不同类型的MTL,包括多任务监督学习,多任务非监督学习,多任务半监督学习,多任务主动学习,多任务强化学习,多任务在线学习和多任务多视角学习。对于每种MTL方法,我们介绍了其有代表性的模型。然后讨论了并行和分布式MTL模型,这两个模型可以帮助加快MTL学习过程。 最后,我们回顾了MTL在各个领域的应用,并介绍了MTL的理论分析。
近些年,深度学习在许多应用中已经广泛应用,并且有一些专门为MTL设计的深度模型。 几乎所有的深度模型都会在不同任务中共享隐含层;在相似任务中,这种任务间共享知识的方式非常有用,但是当不符合这个假设时候,性能将急剧下降。我们认为多任务深度模型的未来发展方向是设计更多灵活的架构,它可以兼容不同的任务之间的差异甚至异常任务。进一步来说,深度学习,任务聚类和多层次的方法缺乏理论基础,需要更多的分析来指导这些方法的研究。
赞助
本工作由中国国家基础研究计划(973项目)(2014CB340304),香港CERG项目(16211214,16209715和16244616),中国国家自然科学基金(61473087和61673202),江苏省自然科学基金(BK20141340)支持。
《国家科学评论》(National Science Review, NSR)是我国第一份英文版自然科学综述性学术期刊,定位于全方位、多角度反映中外科学研究的重要成就,深度解读重大科技事件、重要科技政策,旨在展示世界(尤其是我国)前沿研究和热点研究的最新进展和代表性成果,引领学科发展,促进学术交流。NSR的报道范围涵盖数理科学、化学科学、生命科学、地球科学、材料科学、信息科学等六大领域。基于科睿唯安发布的2016年度的期刊引证报告(Journal Citation Reports,JCR),NSR的最新影响因子达到8.843,稳居全球多学科综合类期刊的第五名(8%,Q1)。NSR发表的所有论文全文可以在线免费阅读和下载。
本文经《National Science Review》(NSR,《国家科学评论》英文版)授权翻译,“机器学习”专题的更多翻译文章将陆续刊出。


📚往期文章推荐

🔗中科院王飞跃:第三轴心时代的智能产业,创立发展智能科技的新“直道”
🔗2018年度国家科技奖提名公示,信息科学组获47项提名(附提名项目)
🔗【NSR特别专题】周志华:机器学习的挑战和影响:Thomas Dietterich访谈「全文翻译」

德先生公众号 | 往期精选
在公众号会话位置回复以下关键词,查看德先生往期文章!
人工智能|机器崛起|区块链|名人堂
虚拟现实|无人驾驶|智能制造|无人机
科研创新|网络安全|数据时代|人机大战
……
更多精彩文章正在赶来,敬请期待!


点击“阅读原文”,移步求知书店,可查阅选购德先生推荐书籍。


