神经网络中 warmup 策略为什么有效?
加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~
本文选自知乎问答,仅用于学术交流,侵删。
问题:
神经网络中 warmup 策略为什么有效;有什么理论解释么?
https://www.zhihu.com/question/338066667
使用 SGD 训练神经网络时,在初始使用较大学习率而后期切换为较小学习率是一种广为使用的做法,在实践中效果好且最近也有若干文章尝试对其进行了理论解释。
而 warmup 策略则与上述 scheme 有些矛盾。warmup 需要在训练最初使用较小的学习率来启动,并很快切换到大学习率而后进行常见的 decay。那么最开始的这一步 warmup 为什么有效呢?它的本质含义是什么,是否有相关的理论解释?进一步的,能否通过良好的初始化或其他方法来代替 warmup 呢?
专业回答
香侬慧语科技
https://www.zhihu.com/question/338066667/answer/771252708
这个问题目前还没有被充分证明,我们只能从直觉上和已有的一些论文[1,2,3]得到推测:
有助于减缓模型在初始阶段对mini-batch的提前过拟合现象,保持分布的平稳
有助于保持模型深层的稳定性
下面来看一下为什么warmup会有这样的效果。
首先,[1]告诉我们,当我们的mini-batch增大的时候,learning rate也可以成倍增长,即,mini-batch大小乘以k,lr也可以乘以k。这是为什么呢?比如现在模型已经train到第t步,权重为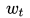
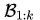
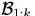
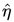
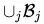
假设我们用的是SGD,那么训k次后我们可以得到:
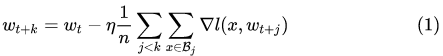
如果我们一次训就可以得到:
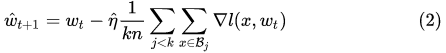
显然,这两个是不一样的。但如果我们假设 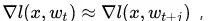
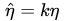
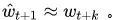
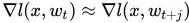
可能不成立呢?[1]告诉我们有两种情况:
在训练的开始阶段,模型权重迅速改变
mini-batch size较小,样本方差较大
第一种情况很好理解,可以认为,刚开始模型对数据的“分布”理解为零,或者是说“均匀分布”(当然这取决于你的初始化);在第一轮训练的时候,每个数据点对模型来说都是新的,模型会很快地进行数据分布修正,如果这时候学习率就很大,极有可能导致开始的时候就对该数据“过拟合”,后面要通过多轮训练才能拉回来,浪费时间。当训练了一段时间(比如两轮、三轮)后,模型已经对每个数据点看过几遍了,或者说对当前的batch而言有了一些正确的先验,较大的学习率就不那么容易会使模型学偏,所以可以适当调大学习率。这个过程就可以看做是warmup。那么为什么之后还要decay呢?当模型训到一定阶段后(比如十个epoch),模型的分布就已经比较固定了,或者说能学到的新东西就比较少了。如果还沿用较大的学习率,就会破坏这种稳定性,用我们通常的话说,就是已经接近loss的local optimal了,为了靠近这个point,我们就要慢慢来。
第二种情况其实和第一种情况是紧密联系的。在训练的过程中,如果有mini-batch内的数据分布方差特别大,这就会导致模型学习剧烈波动,使其学得的权重很不稳定,这在训练初期最为明显,最后期较为缓解(所以我们要对数据进行scale也是这个道理)。
这说明,在上面两种情况下,我们并不能单纯地成倍增长lr 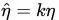
有趣的是,warmup在ResNet[4]中就已经提到了,原文说的是:
We further explore n = 18 that leads to a 110-layer ResNet. In this case, we find that the initial learning rate of 0.1 is slightly too large to start converging . So we use 0.01 to warm up the training until the training error is below 80% (about 400 iterations), and then go back to 0.1 and continue training.
在注释中说的是:
With an initial learning rate of 0.1, it starts converging (<90% error) after several epochs, but still reaches similar accuracy.
这两句话是说,如果一开始就用0.1,虽然会很快收敛,但之后acc还是不会提高(使用了pateaus schedule);如果用了warmup,在收敛后还能有所提高。也就是说,用warmup和不用warmup达到的收敛点,对之后模型能够达到的suboptimal有影响。这说明什么?这说明不用warmup收敛到的点比用warmup收敛到的点更差。这可以从侧面说明,一开始学偏了的权重后面拉都拉不回来……
同时,[2]中也提到:
The main obstacle for scaling up batch is the instability of training with high LR. Hoffer et al. (2017) tried to use less aggressive "square root scaling" of LR with special form of Batch Normalization ("Ghost Batch Normalization") to train Alexnet with B=8K, but still the accuracy (53.93%) was much worse than baseline 58%.
这说明一开始的高lr对深度模型的影响是很显著的。它的不稳定性(instability)也就是上面我们提到的两个点。
[3]通过一些实验告诉我们:
We show that learning rate warmup primarily limits weight changes in the deeper layers and that freezing them achieves similar outcomes as warmup.
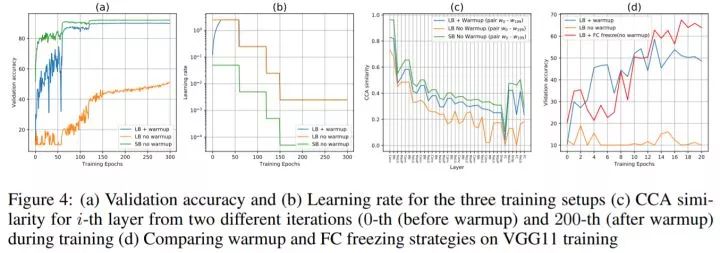
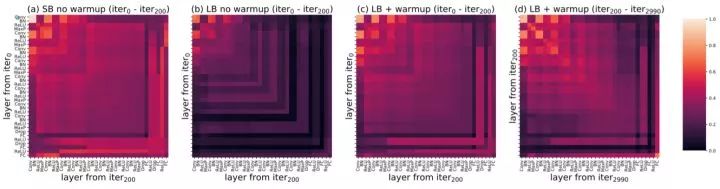
从图二(b,c)可以看到,加了warmup增加了模型最后几层的相似性,这表明warmup可以避免FC层的不稳定的剧烈改变。从图一中可以看到,在有了warmup之后,模型能够学得更稳定。
综上所述,如果来总结一下现在大batch size和大learning rate下的学习率变化和规律的话,可以认为,学习率是呈现“上升——平稳——下降”的规律,这尤其在深层模型和具有多层MLP层的模型中比较显著。如果从模型学习的角度来说,学习率的这种变化对应了模型“平稳——探索——平稳”的学习阶段。
那么你也许会问,为什么早期的神经网络没有warmup?这就回到了之前我们说的两点,与它们对应,早期神经网络的环境是:
网络不够大、不够深
数据集普遍较小,batch size普遍较小
这两点和之前[1]中提到的两点是对应的。网络不够大不够深就意味着模型能够比较容易地把分布拉回来,数据集比较小意味着mini-batch之间的方差可能没有那么大。从而学习率不进行warmup可能不会出现很严重的学习问题。
-End-
*延伸阅读
添加极市小助手微信(ID : cv-mart),备注:研究方向-姓名-学校/公司-城市(如:目标检测-小极-北大-深圳),即可申请加入目标检测、目标跟踪、人脸、工业检测、医学影像、三维&SLAM、图像分割等极市技术交流群,更有每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流,一起来让思想之光照的更远吧~

△长按添加极市小助手

△长按关注极市平台
觉得有用麻烦给个在看啦~





