学界 | 多任务学习概述论文:从定义和方法到应用和原理分析
选自National Science Review
作者:张宇、杨强
机器之心编译
参与:Panda
多任务学习是一个很有前景的机器学习领域,相关的理论和实验研究成果以及应用也在不断涌现。近日,香港科技大学计算机科学与工程系的杨强教授和张宇助理教授在《国家科学评论(National Science Review)》2018 年 1 月份发布的「机器学习」专题期刊中发表了题为《An overview of multi-task learning》的概述论文,对多任务学习的现状进行了系统性的梳理和介绍。机器之心对该论文的主干内容进行了编译介绍,欲更深入了解多任务学习的读者可参阅原论文及论文中列出的相关参考文献。
论文链接:https://academic.oup.com/nsr/article/5/1/30/4101432
多任务学习概述(An overview of multi-task learning)

摘要
多任务学习(MTL)是一个很有前景的机器学习领域,其目标是通过利用多个相关学习任务之间的有用信息来提升它们的表现。我们在本论文中对 MTL 进行了概述。首先我们将介绍 MTL 的定义,然后会介绍多种不同的 MTL 设置,其中包括多任务监督学习、多任务无监督学习、多任务半监督学习、多任务主动学习、多任务强化学习、多任务在线学习和多任务多视角学习。对于每种设置,我们将给出代表性的 MTL 模型。我们还将介绍用于加速学习过程的并行和分布式 MTL 模型。我们也将概览使用 MTL 来提升性能的诸多应用领域(包括计算机视觉、生物信息学、健康信息学、语音、自然语言处理、网络应用和普适计算)和一些代表性的成果。最后我们将介绍近期对 MTL 的理论分析。
引言
利用历史数据中的有用信息来帮助分析未来数据的机器学习,通常需要大量有标签数据才能训练出一个优良的学习器。深度学习模型是一种典型的机器学习模型,因为这类模型是带有很多隐藏层和很多参数的神经网络,所以通常需要数以百万计的数据样本才能学习得到准确的参数。但是,包括医学图像分析在内的一些应用无法满足这种数据要求,因为标注数据需要很多人力劳动。在这些情况下,多任务学习(MTL)可以通过使用来自其它相关学习任务的有用信息来帮助缓解这种数据稀疏问题。
MTL 是机器学习中一个很有前景的领域,其目标是利用多个学习任务中所包含的有用信息来帮助为每个任务学习得到更为准确的学习器。我们假设所有任务(至少其中一部分任务)是相关的,在此基础上,我们在实验和理论上都发现,联合学习多个任务能比单独学习它们得到更好的性能。根据任务的性质,MTL 可以被分类成多种设置,主要包括多任务监督学习、多任务无监督学习、多任务半监督学习、多任务主动学习、多任务强化学习、多任务在线学习和多任务多视角学习。
多任务监督学习任务(可能是分类或回归问题)是根据训练数据集(包含训练数据实例和它们的标签)预测未曾见过的数据的标签。多任务无监督学习任务(可能是聚类问题)是识别仅由数据构成的训练数据集中的有用模式。多任务半监督学习任务与多任务监督学习类似,只是其训练集中不仅包含有标签数据,也包含无标签数据。多任务主动学习任务是利用无标签数据来帮助学习有标签数据,这类似于多任务半监督学习,其差异在于主动学习会选择无标签数据来主动查询它们的标签从而降低标注开销。多任务强化学习任务是选择动作以最大化累积奖励。多任务在线学习任务是处理序列数据。多任务多视角学习任务是处理多视角数据——其中每个数据实例都有多组特征。
MTL 可以看作是让机器模仿人类学习行为的一种方法,因为人类常常将一个任务的知识迁移到另一个相关的任务上。例如,根据作者自身经验,打壁球和打网球的技能可以互相帮助提升。与人类学习类似,(机器)同时学习多个学习任务是很有用的,因为一个任务可以利用另一个相关任务的知识。
MTL 也与机器学习的某些其它领域有关,包括迁移学习、多标签学习和多输出回归,但 MTL 也有自己不同的特点。比如说,类似于 MTL,迁移学习的目标也是将知识从一个任务迁移到另一个任务,但不同之处在于迁移学习希望使用一个或多个任务来帮助另一个目标任务,而 MTL 则是希望多个任务彼此助益。当多任务监督学习的不同任务使用了同样的训练数据时,这就变成了多标签学习或多输出回归。从这个意义上看,MTL 可以被看作是多标签学习和多输出回归的一种泛化。
我们在本论文中对 MTL 进行了概述。我们首先将先给出 MTL 的定义。然后我们将探讨不同的 MTL 设置,其中包括多任务监督学习、多任务无监督学习、多任务半监督学习、多任务主动学习、多任务强化学习、多任务在线学习和多任务多视角学习。对于每种 MTL 设置,我们会介绍代表性的 MTL 模型。当任务数量很多或不同任务的数据位于不同的机器中时,就必需使用并行和分布式 MTL 模型;我们将会介绍几种这样的模型。作为一种大有前景的学习范式,MTL 已经在多个领域得到了应用,其中包括计算机视觉、生物信息学、健康信息学、语音、自然语言处理、网络应用和普适计算;我们将会给出每个领域的一些有代表性的应用。此外,我们也将回顾对 MTL 的理论分析,这能为我们提供对 MTL 的深度理解。
多任务学习
首先,我们给出 MTL 的定义。
定义 1(多任务学习):给定 m 个学习任务,其中所有或一部分任务是相关但并不完全一样的,多任务学习的目标是通过使用这 m 个任务中包含的知识来帮助提升各个任务的性能。
基于这一定义,我们可以看到 MTL 有两个基本因素。
第一个因素是任务的相关性。任务的相关性是基于对不同任务关联方式的理解,这种相关性会被编码进 MTL 模型的设计中。
第二个因素是任务的定义。在机器学习中,学习任务主要包含分类和回归等监督学习任务、聚类等无监督学习任务、半监督学习任务、主动学习任务、强化学习任务、在线学习任务和多视角学习任务。因此不同的学习任务对应于不同的 MTL 设置,这也是后面的章节所关注的重点。在后面的章节中,我们将回顾不同 MTL 设置中的代表性 MTL 模型。
多任务监督学习
多任务监督学习(MTSL)意味着 MTL 中的每个任务都是监督学习任务,其建模了从数据到标签的函数映射。
基于特征的 MTSL
在这一类别中,所有 MTL 模型都假设不同的任务都具有同样的特征表示,这是根据原始特征学习得到的。根据这种共有的特征表示的学习方式,我们进一步将多任务模型分为了三种方法,包括特征变换方法、特征选择方法和深度学习方法。特征变换方法学习到的共有特征是原始特征的线性或非线性变换。特征选择方法假设共有特征是原始特征的一个子集。深度学习方法应用深度神经网络来为多个任务学习共有特征,该表征会被编码在深度神经网络的隐藏层中。
特征变换方法
在这种方法中,共有特征是原始特征的一种线性或非线性变换。
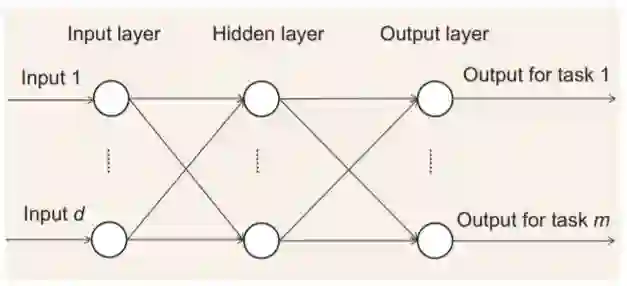
图 1:带有一个输入层、隐藏层和输出层的多任务前向神经网络
特征选择方法
特征选择方法的目标是选择原始特征的一个子集来作为不同任务的共有特征。
深度学习方法
与特征变换方法中的多层前向神经网络模型类似,深度学习方法中的基本模型包括卷积神经网络和循环神经网络等高级神经网络模型。但是,不同于仅有少数隐藏层(比如 2 层或 3 层)的多层前向神经网络,深度学习方法涉及到的神经网络有数十乃至数百个隐藏层。此外,与多层前向神经网络类似,这一类别中的大多数深度学习模型都会将某一隐藏层的输出作为共有特征表征。[23] 中提出的 cross-stitch 网络则与这些深度模型不同,而是会将来自两个任务的隐藏特征组合起来构建更强大的隐藏特征。关于 cross-stitch 网络的示意图参见图 1。
基于参数的 MTSL
基于参数的 MTSL 使用模型参数来关联不同任务的学习。根据不同任务的模型参数的关联方式,我们可将其分成 5 种方法,包括低秩方法、任务聚类方法、任务关系学习方法、脏方法(dirty approach)和多层次方法。具体而言,因为假设任务是相关的,所以参数矩阵 W 很可能是低秩的,这是低秩方法提出的动机。任务聚类方法的目标是将任务分成多个集群,并假设其中每个集群中的所有任务都具有同样的或相似的模型参数。任务关系学习方法是直接从数据中学习任务间的关系。脏方法假设参数矩阵 W 可以分解成两个分量矩阵,其中每个矩阵都由一种稀疏类型进行正则化。多层次方法是脏方法的一种泛化形式,是将参数矩阵分解成两个以上的分量矩阵,从而建模所有任务之间的复杂关系。
低秩方法
相似的任务通常具有相似的模型参数,这使得 W 很可能是低秩的。
任务聚类方法
任务聚类方法是应用数据聚类方法的思想来将任务分成多个簇,其中每个簇中的任务具有相似的模型参数。
任务关系学习方法
这种方法使用任务关系来反映任务相关性,任务关系的例子包括相似度和协方差。
脏方法
脏方法假设参数矩阵 W 可以分解为两个分量矩阵:W = U + V,其中 U 和 V 各自包含了任务相关性的不同部分。在这种方法中,不同模型的目标函数可以被统一成一个目标函数,此目标函数最小化所有任务上的训练集损失以及 U 和 V 的两个正则化项 g(U) 和 h(V)。因此,这种方法的不同类型主要体现在 g(U) 和 h(V) 的选择上,具体可参见表 1。

表 1:脏方法中不同方法的 g(U) 和 h(V) 的选择
多层次方法
多层次方法是脏方法的一种泛化形式。它是将参数矩阵 W 分解成多个(多于两个)分量矩阵。多层次方法有助于建模复杂的任务结构。
基于实例的 MTSL
这一类别的研究很少,其中 [61] 提出的多任务分布匹配方法是其中的代表。具体来说,它首先评估每个实例来自其自己的任务的概率和来自所有任务的混合的概率之比。在确定了此比率之后,这种方法会利用此比率针对每一个任务来加权所有任务的数据,并利用加权的数据来学习每一个任务的模型参数。
讨论
基于特征的 MTSL 可以为不同的任务学习常见的特征表示,而且更适合原始特征信息不多和区分度不大的应用,比如计算机视觉、自然语言处理和语音。但是,基于特征的 MTSL 容易轻易被与其它无关的离群任务(outlier task)影响,因为它难以为彼此无关的任务学习共有特征。在有良好的特征表征时,基于参数的 MTSL 可以学习到更加准确的模型参数,而且它也对离群任务更为鲁棒。因此,基于特征的 MTSL 和基于参数的 MTSL 可以相互补充。基于实例的 MTSL 目前还处于探索阶段,它与其它两种方法并行发展。
总而言之,在 MTL 研究中,MTSL 是最重要的,因为这是其它设置研究的基础。在 MTL 领域已有的研究工作中,有大约 90% 都是关于 MTSL 设置;而在 MTSL 设置中,基于特征和基于参数的 MSTL 得到的关注最多。
多任务无监督学习
不同于每个数据实例都关联了一个标签的多任务监督学习,多任务无监督学习的训练集仅由数据样本构成,其目标是挖掘数据集中所包含的信息。典型的无监督学习任务包括聚类、降维、流形学习(manifold learning)和可视化等,而多任务无监督学习主要关注多任务聚类。聚类是指将一个数据集分成多个簇,其中每簇中都有相似的实例,因此多任务聚类的目的是通过利用不同数据集中包含的有用信息来在多个数据集上同时执行聚类。
多任务半监督学习
在很多应用中,数据通常都需要很多人力来进行标注,这使得有标签数据并不很充足;而在很多情况下,无标签数据则非常丰富。所以在这种情况下,可以使用无标签数据来帮助提升监督学习的表现,这就是半监督学习。半监督学习的训练集由有标签和无标签的数据混合构成。在多任务半监督学习中,目标是一样的,其中无标签数据被用于提升监督学习的表现,而不同的监督学习任务则共享有用的信息来互相帮助。
多任务主动学习
多任务主动学习的设置和多任务半监督学习几乎一样,其中每个任务的训练集中都有少量有标签数据和大量无标签数据。但是不同于多任务半监督学习,在多任务主动学习中,每个任务都会选择部分无标签数据来查询一个 oracle 以主动获取其标签。因此,无标签数据的选择标准是多任务主动学习领域的主要研究重点。
多任务强化学习
受行为心理学的启发,强化学习研究的是如何在环境中采取行动以最大化累积奖励。其在很多应用上都表现出色,在围棋上击败人类的 AlphaGo 就是其中的代表。当环境相似时,不同的强化学习任务可以使用相似的策略来进行决策,因此研究者提出了多任务强化学习。
多任务在线学习
当多个任务的训练数据以序列的形式出现时,传统的 MTL 模型无法处理它们,但多任务在线学习则可以做到。
多任务多视角学习
在计算机视觉等一些应用中,每个数据样本可以使用不同的特征来描述。以图像数据为例,其特征包含 SIFT 和小波(wavelet)等。在这种情况下,一种特征都被称为一个视角(view)。多视角学习就是为处理这样的多视角数据而提出的一种机器学习范式。与监督学习类似,多视角学习中每个数据样本通常都关联了一个标签。多视角学习的目标是利用多个视角中包含的有用信息在监督学习的基础上进一步提升表现。多任务多视角学习是多视角学习向多任务的扩展,其目标是利用多个多视角学习问题,通过使用相关任务中所包含的有用信息来提升每个多视角学习问题的性能。
并行和分布式 MTL
当任务数量很大时,如果我们直接应用一个多任务学习器,那可能就会有很高的计算复杂度。现在计算机使用了多 CPU 和多 GPU 架构,其计算能力非常强大。所以我们可以使用这些强大的计算设备来设计并行 MTL 算法,从而加速训练过程。[82] 中设计了一种并行 MTL 方法来解决 MTRL 模型的一个子问题,这个子问题也会出现在很多属于任务关系学习方法的正则化方法中。具体而言,这种方法利用了 FISTA 算法设计了一种针对所有任务的可分解的代理函数(surrogate function),这个代理函数可以并行化,从而实现学习过程加速。此外,[82] 还研究了三种损失函数(hinge、ε-insensitive 和平方损失),让这种并行方法适用于 MTSL 中的分类和回归问题。
在某些情况中,用于不同任务的训练数据可能存在不同的机器中,这会使传统的 MTL 模型难以工作。如果将所有的训练数据都可转移到一台机器上,这会造成额外的传输和存储成本。设计能够直接处理分布在多台机器上数据的分布式 MTL 模型是更好的选择。[83] 提出了一种基于 debiased lasso 模型的分布式算法,该算法在一台机器上学习一个任务,并实现了高效的通信。
多任务学习的应用
包括计算机视觉、生物信息学、健康信息学、语音、自然语言处理、网络应用和普适计算在内的很多领域都在使用 MTL 来提升各自的应用的性能。
理论分析
学习理论(learning theory)用来研究机器学习的学习模型(包括 MTL 模型)的理论基础。MTL 领域的理论分析主要关注的是 MTL 模型的泛化边界(generalization bound)。众所周知,MTL 的主要关注点是 MTL 在测试数据上的泛化表现。但是因为难以对底层的数据分布建模,所以泛化表现难以直接计算。因此泛化边界被提出来用于提供泛化表现的上界。
[133] 首次为通用 MTL 模型推导出了泛化边界,然后很多研究分析了不同 MTL 方法的泛化边界,包括针对特征变换方法的泛化边界 [7,134]、针对特征选择方法的泛化边界 [135]、针对低秩方法的泛化边界 [24,135–138]、针对任务关系学习方法的泛化边界 [136] 和针对脏方法的泛化边界 [138]。
结论
在本文中,我们对 MTL 进行概述。首先,我们给出 MTL 的定义。在此基础上,我们介绍了多任务监督学习、多任务无监督学习、多任务半监督学习、多任务主动学习、多任务强化学习、多任务在线学习和多任务多视角学习等多种不同的 MTL 设置。对于每种设置,我们介绍了其代表性模型。然后讨论了并行和分布式 MTL 模型,这可以帮助加快学习过程。最后,我们回顾了 MTL 在各个领域的应用,并对 MTL 进行了理论分析。
最近,深度学习在诸多应用领域中广为流行,并且深度学习十分适用于 MTL。几乎所有的深层模型都会为不同的任务共享隐藏层;当各种任务非常相似时,这种在任务之间共享知识的方式非常有用,但是一旦这种假设被违背,模型性能则显著恶化。我们认为,多任务深度模型的未来发展方向是设计更加灵活的架构,可以容纳不相关的任务甚至异常的任务。此外,深度学习,任务聚类和多层次方法缺乏理论基础,需要更多的分析来指导这些方面的研究。

英文原文 2017 年 9 月发表于《国家科学评论》(National Science Review, NSR),原标题为「An overview of multi-task learning」。《国家科学评论》是科学出版社旗下期刊,与牛津大学出版社联合出版。机器之心经《国家科学评论》和牛津大学出版社授权刊发该论文文中文翻译。
原文链接:https://doi.org/10.1093/nsr/nwx105
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:editor@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com


