从KDD 2018最佳论文看Airbnb实时搜索排序中的Embedding技巧

作者丨王喆
单位丨Hulu高级机器学习工程师
研究方向丨计算广告、推荐系统
知乎专栏丨王喆的机器学习笔记
今天我们聊一聊 KDD 2018 的 Best Paper,Airbnb 的一篇极具工程实践价值的文章 Real-time Personalization using Embeddings for Search Ranking at Airbnb。


相信大家已经比较熟悉我选择计算广告和推荐系统相关文章的标准:
工程导向的;
阿里、Facebook、Google 等一线互联网公司出品的;
前沿或者经典的。
Airbnb 这篇文章无疑又是一篇兼具实用性和创新性的工程导向的 paper。文章的作者 Mihajlo 发表这篇文章之前在 Recsys 2017 上做过一个 talk,其中涉及了文章中的大部分内容,我也将结合那次 talk 的 slides [1] 来讲解这个论文。
废话不多说,我们进入文章的内容。
Airbnb 作为全世界最大的短租网站,提供了一个连接房主(host)挂出的短租房(listing)和主要是以旅游为目的的租客(guest/user)的中介平台。这样一个中介平台的交互方式比较简单,guest 输入地点,价位,关键词等等,Airbnb 会给出 listing 的搜索推荐列表:
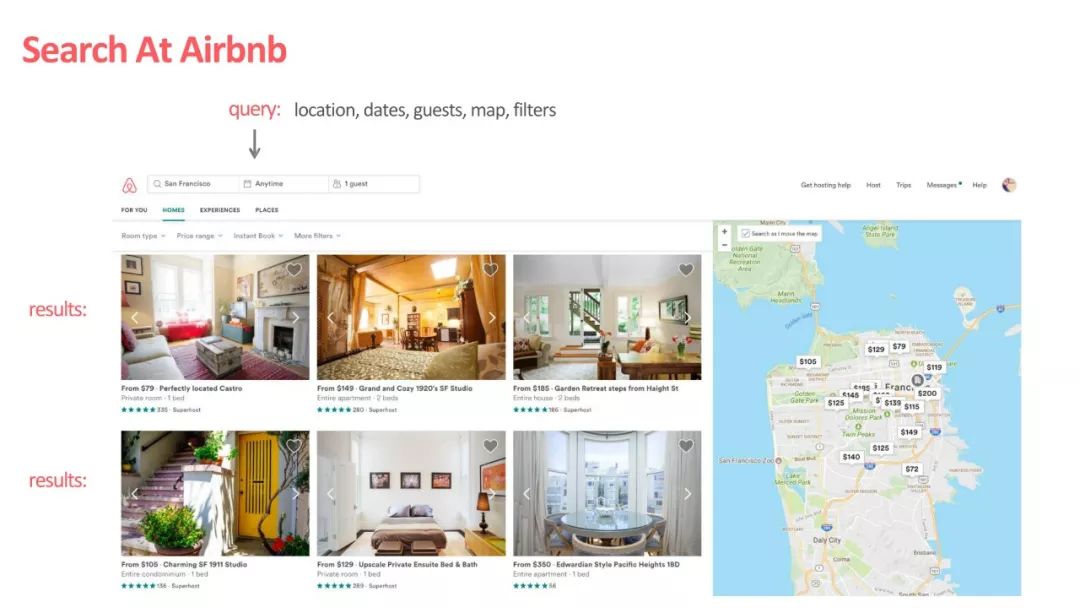
▲ Airbnb的业务场景
容易想见,接下来 guest 和 host 之间的交互方式无非有这样几种:
guest点击listing(click)
guest预定lising(book)
host有可能拒绝guest的预定请求(reject)
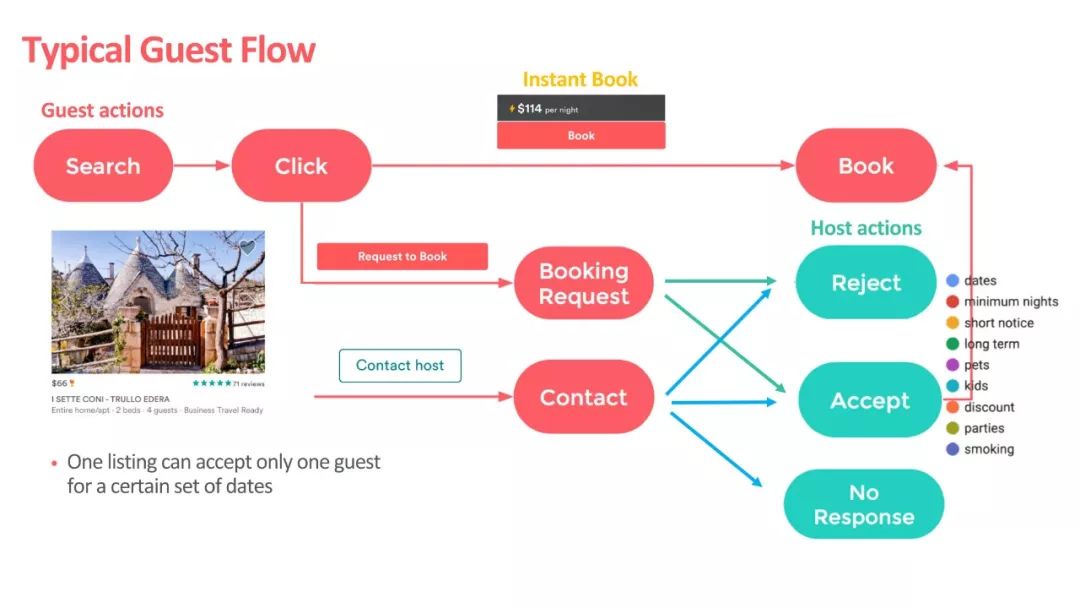
▲ Airbnb的交互方式
基于这样的场景,利用几种交互方式产生的数据,Airbnb 的 search 团队要构建一个 real time 的 ranking model。
为了捕捉到用户 short term 以及 long term 的兴趣,Airbnb 并没有把 user history 的 clicked listing ids 或者 booked listing ids 直接输入 ranking model,而是先对 user 和 listing 进行了embedding,进而利用 embedding 的结果构建出诸多 feature,作为 ranking model 的输入。这篇文章的核心内容就是介绍如何生成 listing 和 user 的embedding。
具体到 embedding 上,文章通过两种方式生成了两种不同的 embedding 分别 capture 用户的 short term 和 long term 的兴趣。
一是通过 click session 数据生成 listing 的 embedding,生成这个 embedding 是为了进行 listing 的相似推荐,以及对用户进行 session 内的实时个性化推荐。
二是通过 booking session 生成 user-type 和 listing-type 的 embedding,目的是捕捉不同 user-type 的 long term 喜好。由于 booking signal 过于稀疏,Airbnb 对同属性的 user 和 listing 进行了聚合,形成了 user-type 和 listing-type 这两个 embedding 的对象。
我们先讨论第一个对 listing 进行 embedding 的方法:
Airbnb 采用了 click session 数据对 listing 进行 embedding,其中 click session 指的是一个用户在一次搜索过程中,点击的 listing 的序列,这个序列需要满足两个条件,一个是只有停留时间超过 30s 的 listing page 才被算作序列中的一个数据点,二是如果用户超过 30 分钟没有动作,那么这个序列会断掉,不再是一个序列。

▲ Click Session的定义和条件
这么做的目的无可厚非,一是清洗噪声点和负反馈信号,二是避免非相关序列的产生。
有了由 clicked listings 组成的 sequence,就像我们在之前专栏文章中讲过的 item2vec 方法一样,我们可以把这个 sequence 当作一个“句子”样本,开始 embedding 的过程。
Airbnb不出意外地选择了 word2vec 的 skip-gram model 作为 embedding 方法的框架。通过修改 word2vec 的 objective 使其靠近 Airbnb 的业务目标。
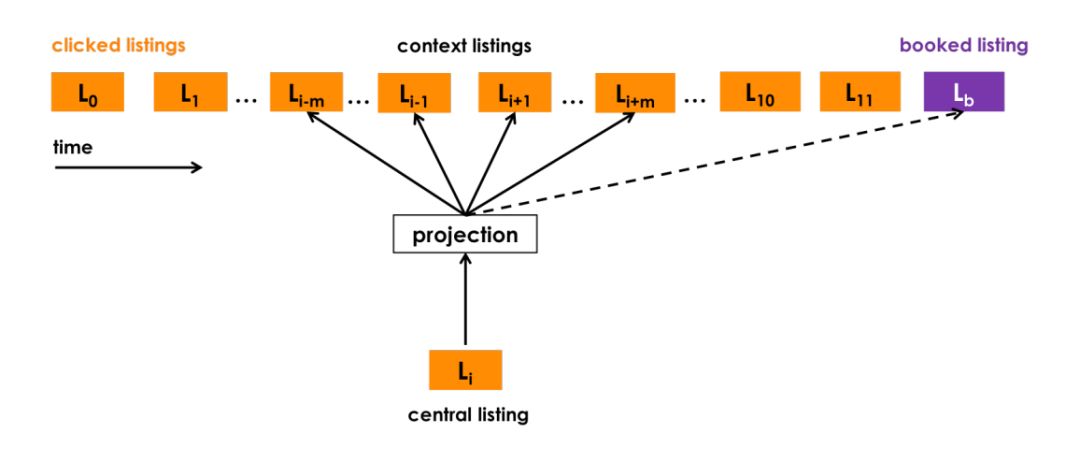
▲ Airbnb的类word2vec embedding方法
我们在之前的专栏文章《万物皆embedding》[2] 中详细介绍了 word2vec 的方法,不清楚的同学还是强烈建议先去弄明白 word2vec 的基本原理,特别是 objective 的形式再继续下面的阅读。
我们假设大家已经具备了基本知识,这里直接列出 word2vec 的 skip-gram model 的 objective 如下:
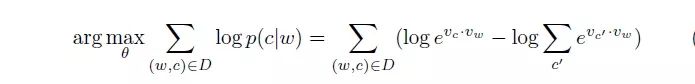
在采用 negative sampling 的训练方式之后,objective 转换成了如下形式:
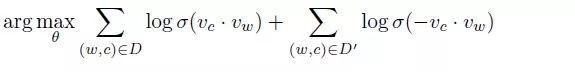
其中 σ 函数代表的就是我们经常见到的 sigmoid 函数,D 是正样本集合,D' 是负样本集合。我们再详细看一下上面 word2vec 这个 objective function,其中前面的部分是正样本的形式,后面的部分是负样本的形式(仅仅多了一个负号)。
为什么原始的 objective 可以转换成上面的形式,其实并不是显然的,感兴趣的同学可以参考这篇文章,Negative-Sampling Word-Embedding Method [3]。这里,我们就以 word2vec 的 objective function 为起点,开始下面的内容。
转移到 Airbnb 这个问题上,正样本很自然的取自 click session sliding window 里的两个 listing,负样本则是在确定 central listing 后随机从语料库(这里就是 listing 的集合)中选取一个 listing 作为负样本。
因此,Airbnb 初始的 objective function 几乎与 word2vec 的 objective 一模一样,形式如下:
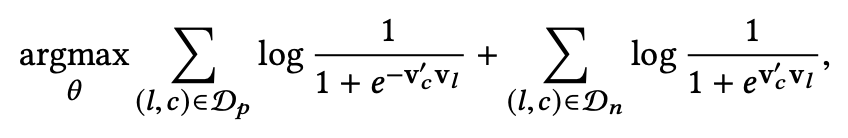
给大家出个脑筋急转弯:为啥 Airbnb objective 的正样本项前面是负号,原始的 word2vec objective 反而是负样本项前面是负号,是 Airbnb 搞错了吗?
在原始 word2vec embedding 的基础上,针对其业务特点,Airbnb 的工程师希望能够把 booking 的信息引入 embedding。这样直观上可以使 Airbnb 的搜索列表和 similar item 列表中更倾向于推荐之前 booking 成功 session 中的listing。
从这个 motivation 出发,Airbnb 把 click session 分成两类,最终产生 booking 行为的叫 booked session,没有的称做 exploratory session。
因为每个 booked session 只有最后一个 listing 是 booked listing,所以为了把这个 booking 行为引入 objective,不管这个 booked listing 在不在 word2vec 的滑动窗口中,我们都会假设这个 booked listing 与滑动窗口的中心 listing 相关,也就相当于引入了一个 global context 到 objective 中,因此,objective 变成了下面的样子:
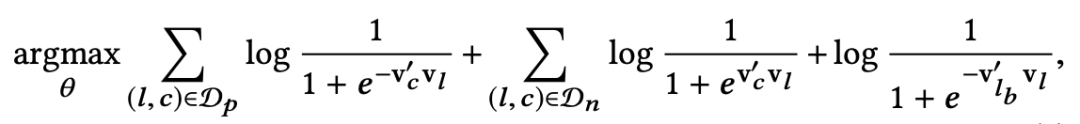
其中最后一项的 lb 就是代表着 booked listing,因为 booking 是一个正样本行为,这一项前也是有负号的。
需要注意的是最后一项前是没有 sigma 符号的,前面的 sigma 符号是因为滑动窗口中的中心 listing 与所有滑动窗口中的其他 listing 都相关,最后一项没有 sigma 符号直观理解是因为 booked listing 只有一个,所以 central listing 只与这一个 listing 有关。
但这里 objective 的形式我仍然是有疑问的,因为这个 objective 写成这种形式应该仅代表了一个滑动窗口中的 objective,并不是整体求解的 objective。如果是整体的 objective,理应是下面的形式:
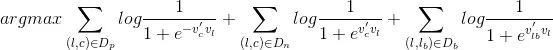
其中 Db 代表了所有 booked session 中所有滑动窗口中 central listing 和 booked listing 的 pair 集合。
不知道大家有没有疑问,我们可以在这块多进行讨论。
下面这一项就比较容易理解了,为了更好的发现同一市场(marketplace)内部 listing 的差异性,Airbnb 加入了另一组 negative sample,就是在 central listing 同一市场的 listing 集合中进行随机抽样,获得一组新的 negative samples。
同理,我们可以用跟之前 negative sample 同样的形式加入到 objective 中。
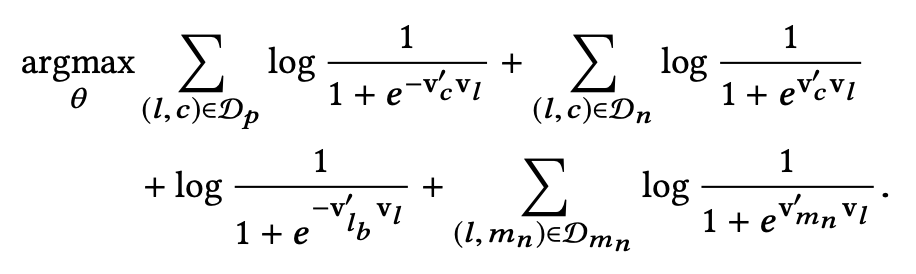
其中 Dmn 就是新的同一地区的 negative samples 的集合。
至此,lisitng embedding 的 objective 就定义完成了,embedding 的训练过程就是 word2vec negative sampling 模型的标准训练过程,这里不再详述。
除此之外,文章多介绍了一下 cold start 的问题。简言之,如果有 new listing 缺失 embedding vector,就找附近的 3 个同样类型、相似价格的 listing embedding 进行平均得到,不失为一个实用的工程经验。
为了对 embedding 的效果进行检验,Airbnb 还实现了一个 tool,我们简单贴一个相似 embedding listing 的结果。
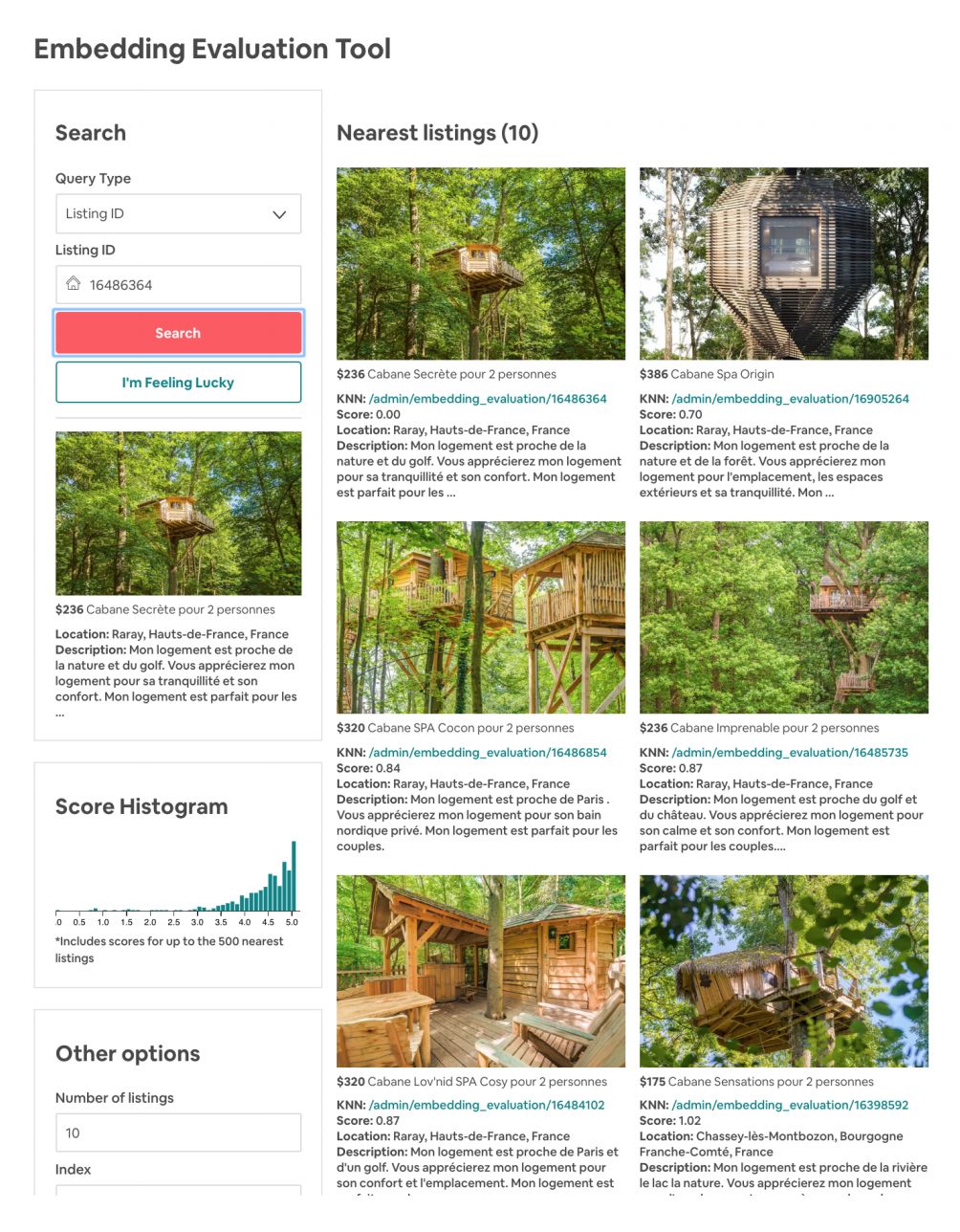
▲ Airbnb Similar Listing
从中可以看到,embedding 不仅 encode 了 price,listing-type 等信息,甚至连 listing 的风格信息都能抓住,说明即使我们不利用图片信息,也能从用户的 click session 中挖掘出相似风格的 listing。
至此我们介绍完了 Airbnb 利用 click session 信息对 listing 进行 embedding 的方法。写到这里笔者基本要断气了,下一篇我们再接着介绍利用 booking session 进行 user-type 和 listing-type embedding 的方法,以及 Airbnb 如何把这些 embedding feature 整合到最终的 search ranking model 中的方法。
最后给大家三个问题以供讨论:
1. 为什么 Airbnb objective 中正负样本的正负号正好跟 word2vec objective 的正负号相反?
2. Airbnb 加入 booked listing 作为 global context,为什么在 objective 中不加 sigma 加和符号?
3. 这里我们其实只得到了 listing 的 embedding,如果是你,你会怎样在 real time search ranking 过程中使用得到的 listing embedding?
参考资料
[1] https://astro.temple.edu/~tua95067/Mihajlo_RecSys2017.pptx
[2] https://zhuanlan.zhihu.com/p/53194407
[3] https://arxiv.org/pdf/1402.3722.pdf
[4] https://github.com/wzhe06/Reco-papers

点击以下标题查看更多往期内容:

让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢? 答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 访问作者知乎专栏
相关内容

Airbnb https://zh.airbnb.com/?af=83334047 成立于 2008 年 8 月,总部位于加利福尼亚州旧金山市。Airbnb 是一个值得信赖的社区型市场,在这里人们可以通过网站、手机或平板电脑发布、发掘和预订世界各地的独特房源。无论是想在公寓里住一个晚上,或在城堡里呆一个星期,又或在别墅住上一个月,都能以任何价位享受到 Airbnb 在全球 191 个国家的 34,000 多个城市为你带来的独一无二的住宿体验。



