不一样的论文解读:2018 KDD best paper「Embeddings at Airbnb」

AI 科技评论按:本文作者吴海波,该文首发于知乎,AI 科技评论获其授权转载。
Airbnb 的 Real-time Personalization using Embeddings for Search Ranking at Airbnb 一文拿了今年 KDD ADS Track 的最佳论文,和 16 年 Google 的 W&D 类似,并不 fancy,但非常 practicable,值得一读。可喜的是,据我所知,国内一线团队的实践水平并不比论文中描述的差,而且就是 W&D,国内也有团队在论文没有出来之前就做出了类似的结果,可见在推荐这样的场景,大家在一个水平线上。希望未来国内的公司,也发一些真正实用的 paper,不一定非要去发听起来 fancy 的。
自从 Word2vec 出来后,迅速应用到各个领域中,夸张一点描述,万物皆可 embedding。在 NLP 中,一个困难是如何描述词,传统有 one-hot、n-gram 等各种方式,但它们很难表达词与词之间的语义关系,简单来讲,即词之间的距离远近关系。我们把每个词的 Embedding 向量理解成它在这个词表空间的位置,即位置远近能描述哪些词相关,哪些词不相关。
对于互联网场景,比如电商、新闻,同样的,我们很难找到一个合适表达让计算机理解这些实体的含义。传统的方式一般是给实体打标签,比如新闻中的娱乐、体育、八卦等等。且不说构建一个高质量标签体系的成本,就其实际效果来讲,只能算是乏善可陈。类似 NLP,完全可以将商品本身或新闻本身当做一个需要 embedding 的实体。当我们应用 embedding 方案时,一般要面对下面几个问题:
1.希望 Embedding 表达什么,即选择哪一种方式构建语料
2.如何让 Embedding 向量学到东西
3.如何评估向量的效果
4.线上如何使用
下面我们结合论文的观点来回答上面问题,水平有限,如有错误,欢迎指出。
希望 Embedding 表达什么
前面我们提了 Embedding 向量最终能表达实体在某个空间里面的距离关系,但并没有讲这个空间是什么。在 NLP 领域,这个问题不需要回答,就是语义空间,由现存的各式各样的文本语料组成。在其他场景中,以电商举例,我们会直接对商品 ID 做 Embedding,其训练的语料来自于用户的行为日志,故这个空间是用户的兴趣点组成。行为日志的类型不同,表达的兴趣也不同,比如点击行为、购买行为,表达的用户兴趣不同。故商品 Embedding 向量最终的作用,是不同商品在用户兴趣空间中的位置表达。
很多同学花很多时间在尝试各种 word2vec 的变种,其实不如花时间在语料构建的细节上。首先,语料要多,论文中提到他们用了 800 million search clicks sessions,在我们尝试 Embedding 的实践中,语料至少要过了亿级别才会发挥作用。其次,session 的定义很重要。word2vec 在计算词向量时和它 context 关系非常大,用户行为日志不像文本语料,存在标点符合、段落等标识去区分词的上下文。
举个例子,假设我们用用户的点击行为当做语料,当我们拿到一个用户的历史点击行为时,比如是 list(商品 A,商品 B,商品 C,商品 D),很有可能商品 B 是用户搜索了连衣裙后点的最后一个商品,而商品 C 是用户搜索了手机后点击的商品,如果我们不做区分,模型会认为 B 和 C 处以一个上下文。
具体的 session 定义要根据自身的业务诉求来,不存在标准答案,比如上面的例子,如果你要做用户跨兴趣点的变换表达,也是可以的,论文中给出了 airbnb 的规则:
A new session is started whenever there is a time gap of more than 30 minutes between two consecutive user clicks.
值得一提的是,论文中用点击行为代表短期兴趣和 booking 行为代表长期兴趣,分别构建 Embedding 向量。关于长短期兴趣,业界讨论很多,我的理解是长期兴趣更稳定,但直接用单个用户行为太稀疏了,无法直接训练,一般会先对用户做聚类再训练。
如何让 Embedding 向量学到东西
模型细节
一般情况下,我们直接用 Word2vec,效果就挺好。论文作者根据 Airbnb 的业务特点,做了点改造,主要集中在目标函数的细节上,比较出彩。先来看一张图:
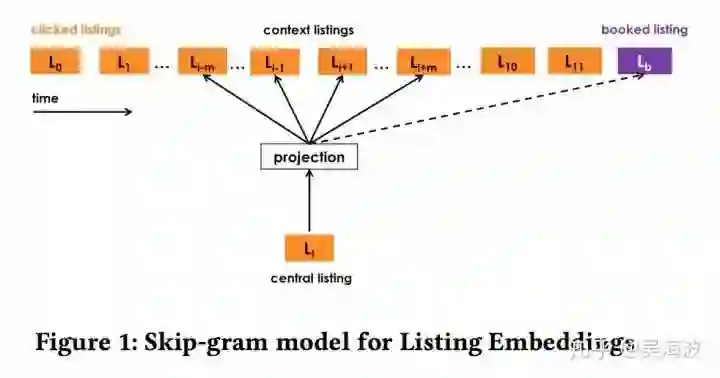
主要 idea 是增加一个 global context,普通的 word2vec 在训练过程中,词的 context 是随着窗口滑动而变化,这个 global context 是不变的,原文描述如下:
Both are useful from the standpoint of capturing contextual similarity, however booked sessions can be used to adapt the optimization such that at each step we predict not only the neighboring clicked listings but the eventually booked listing as well. This adaptation can be achieved by adding booked listing as global context, such that it will always be predicted no matter if it is within the context window or not.
再看下它的公式,更容易理解:
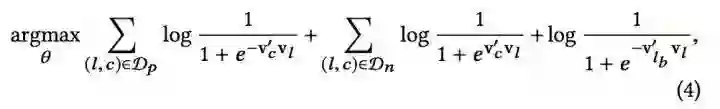
注意到公式的最后一项和前面两项的区别,在累加符号的下面,没有变 D 限制。我的理解是,word2vec 的算法毕竟是非监督的,而 Airbnb 的业务最终是希望用户 Booking,加入一个约束,能够将学到的 Embedding 向量更好的和业务目标靠近。后面还有一个公式,思路是类似的,不再赘述。
这个思路也可以理解成另一种简单的多目标融合策略,另一篇阿里的论文也值得一读,提出了完整空间多任务模型(Entire Space Multi-Task Model,ESMM)来解决。
数据稀疏是核心困难
Word2vec 的算法并不神奇,还是依赖实体出现的频次,巧妇难为无米之炊,如果实体本身在语料中出现很少,也很好学到好的表达。曾经和阿里的同学聊过一次 Embedding 上线效果分析,认为其效果来源于中部商品的表达,并不是大家理解的长尾商品。头部商品由于数据量丰富,类似 i2i 的算法也能学的不错,而尾部由于数据太稀疏,一般也学不好,所以 embedding 技术要想拿到不错的收益,必须存在一批中部的商品。
论文中也提到,他们会对 entity 做个频次过滤,过滤条件在 5-10 occurrences。有意思的是,以前和头条的同学聊过这件事情,他们那边也是类似这样的频次,我们这边会大一点。目前没有做的很细致,还未深究这个值的变化对效果的影响,如果有这方面经验的同学,欢迎指出。
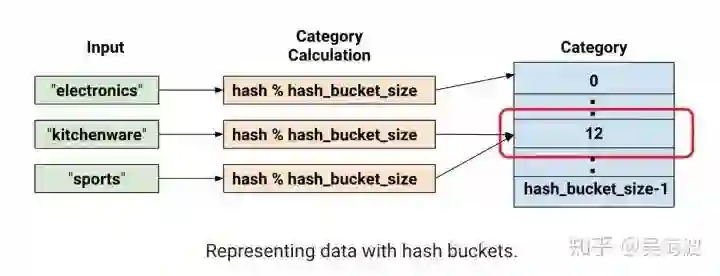
另一个方法,也是非常常见,即对稀疏的 id 做个聚类处理,论文提了一个规则,但和 Airbnb 的业务耦合太深了,其他业务很难直接应用,但可以借鉴思想。阿里以前提过一种 sixhot 编码,来缓解这个问题,不知道效果如何。也可以直接 hash,个人觉得这个会有损,但 tensorflow 的官网教程上,feature columns 部分关于 Hashed Column 有一段话说是无损的:
At this point, you might rightfully think: "This is crazy!" After all, we are forcing the different input values to a smaller set of categories. This means that two probably unrelated inputs will be mapped to the same category, and consequently mean the same thing to the neural network. The following figure illustrates this dilemma, showing that kitchenware and sports both get assigned to category (hash bucket) 12:
As with many counterintuitive phenomena in machine learning, it turns out that hashing often works well in practice. That's because hash categories provide the model with some separation. The model can use additional features to further separate kitchenware from sports.
离线如何评估效果
向量评估的方式,主要用一些聚类、高维可视化 tnse 之类的方法,论文中描述的思路和我的另一篇文章 Embedding向量召回在蘑菇街的实践(https://zhuanlan.zhihu.com/p/35491904)比较像。当 Airbnb 的工具做的比较好,直接实现了个系统来帮助评估。
值得一提的是,论文还提出一种评估方法,用 embedding 向量做排序,去和真实的用户反馈数据比较,直接引用 airbnb 知乎官方账号描述:
更具体地说,假设我们获得了最近点击的房源和需要排序的房源候选列表,其中包括用户最终预订的房源;通过计算点击房源和候选房源在嵌入空间的余弦相似度,我们可以对候选房源进行排序,并观察最终被预订的房源在排序中的位置。
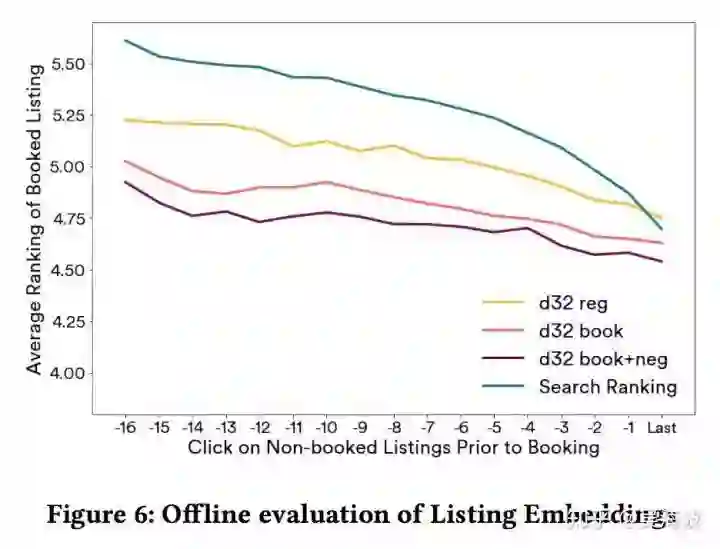
上图可以看出,d32 book+neg 的效果最好。
线上如何用
论文中反复提到的实时个性化并不难,只要支持一个用户实时行为采集的系统,就有很多种方案去实现实时个性化,最简单就是将用户最近的点击序列中的实体 Embedding 向量做加权平均,再和候选集中的实体做 cosine 距离计算,用于排序。线上使用的细节比较多,论文中比较出彩的点有两个:
多实体 embedding 向量空间一致性问题
这是一个很容易被忽视的问题,当需要多个实体 embedding 时,要在意是否在一个空间,否则计算距离会变得很奇怪。airbnb 在构建 long-term 兴趣时,对用户和 list 做了聚类,原文如此描述:
To learn user_type and listinд_type embeddings in the same vector space we incorporate the user_type into the booking sessions.
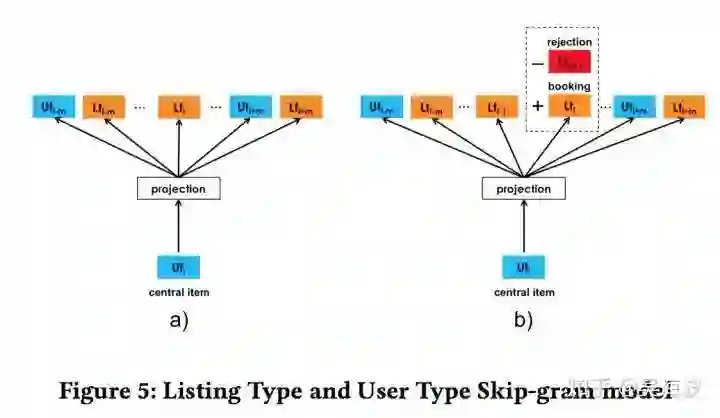
即直接将二者放在一个语料里面训练,保证在一个空间。如此,计算的 cosine 距离具有实际的意义。
Negative 反馈
无论是点击行为还是成交行为,都是用户的 positive 反馈,需要用户付出较大的成本,而另一种隐式的负反馈,我们很少用到(主要是噪音太强)。当前主流的个性化被人诟病最多的就是相似内容扎堆。给用户推相似内容,已经是被广泛验证有效的策略,但我们无法及时有效的感知到用户的兴趣是否已经发生变化,导致损坏了用户体验。因此,负反馈是一个很好的思路,airbnb 给出了 skipped listing_ids 的策略。
论文地址:
https://www.kdd.org/kdd2018/accepted-papers/view/real-time-personalization-using-embeddings-for-search-ranking-at-airbnb

相关内容

Airbnb https://zh.airbnb.com/?af=83334047 成立于 2008 年 8 月,总部位于加利福尼亚州旧金山市。Airbnb 是一个值得信赖的社区型市场,在这里人们可以通过网站、手机或平板电脑发布、发掘和预订世界各地的独特房源。无论是想在公寓里住一个晚上,或在城堡里呆一个星期,又或在别墅住上一个月,都能以任何价位享受到 Airbnb 在全球 191 个国家的 34,000 多个城市为你带来的独一无二的住宿体验。




