一天造出10亿个淘宝首页,阿里工程师如何实现?
阿里妹导读:双十一手淘首页个性化场景是推荐生态链路中最大的场景之一,在手淘APP承载了整体页面的流量第一入口,对用户流量的整体承接、分发、调控,以及用户兴趣的深度探索与发现上起着至关重要的作用。
双11手淘首页的几个重要推荐场景截图如下:
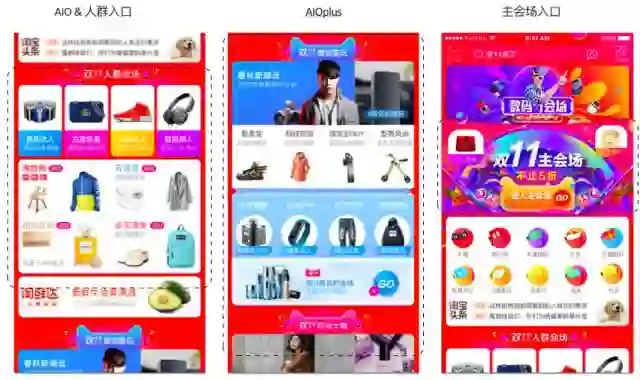
如上图所示,左一场景为AIO综合会场,包括AIO日常场景(淘抢购、有好货、清单等)、双11人群会场及行业会场;中间为AIOplus场景卡片综合会场,包括5张会场卡片,每张卡片融入了行业主分会场、标签会场,该业务涉及到20多个日常业务以及标签、行业会场的分发;右三为主会场入口所见所得,用两个素材轮播的方式给双11主会场进行引流。双十一当天整体点击UV引流效果方面,首页给各会场还是取得了很好的分发效果,数据达到数千万UV以上。
与此同时,今年双十一在推荐的去重打散及探索发现上做了很多深度的优化,过去更多的是在相似性推荐的单一数据目标上进行优化,今年在match及rank技术上采用了更多多阶游走及探索发现的embedding技术,力争在ctr效果有一定保证的情况下,加大对用户体验比如多样性、搭配潜在兴趣、深度用户偏好等方面的推荐。
举个简单例子,之前的推荐系统在捕捉到用户对茶杯这一商品感兴趣后,很可能会推出更多的相似茶杯,新的推荐系统在多阶召回技术的基础上通过对用户兴趣进行深度学习的挖掘,会按一定的概率推荐茶叶、茶具等"弱相似"但满足用户搭配潜在兴趣的商品。
究竟阿里如何使用AI构建淘宝首页?今天一起来揭秘。
一. 业务技术简介
首页个性化在算法技术上主要涉及Graph Embedding召回模型、DeepCross&ResNet实时网络排序模型,并在搜索工程Porsche&Blink、Rank Service、Basic Engine等系统的基础上结合业务应用的需求沉淀了Graph Embedding召回框架及XTensorflow排序模型平台供推荐其他场景使用,提升效果均达到两位数以上。
二. 首页个性化推荐框架(包括MATCH召回和RANK排序两部分)
1.万物皆向量--Graph Embedding深度召回框架
在推荐系统的发展历程中,面临了两个核心问题,用户的长尾覆盖度以及新商品的冷启动,这两个维度的数据扩展性瓶颈一直以来对广大推荐算法工程师都是不小的挑战。而我们基于Graph Embedding的理论知识提出的相关创新框架在召回阶段利用用户的序列化点击行为构建全网行为graph,并结合深度速随机游走技术对用户行为进行"虚拟采样"拟合出多阶(一般5以上)的潜在兴趣信息,扩大用户的长尾兴趣宝贝召回,并同时利用side information-based的深度网络进行知识泛化学习,在一定程度上解决了用户覆盖、新商品面临的冷启动问题,同时虚拟样本的采样技术结合深度模型的泛化学习等在用户对商品的探索发现上加大的扩大了召回量,提升了多样性及发现度。
Graph Embedding是一种将复杂网络投影到低维空间的机器学习算法,典型的做法是将网络中的节点做向量化表达,使节点间的向量相似度接近原始节点间在网络结构、近邻关系、meta信息等多维度上的相似性。淘宝个性化推荐场景所面对的数以十亿计的用户、商品、交互数据和各类属性构成了一个规模庞大的异构网络,如果能将网络中的各类信息统一建模在同一个维度空间,用向量的方式进行表达,它的简洁和灵活性会有巨大的应用空间,诸如扩展I2I计算、解决商品冷启动、作为中间结果输出到上层高级模型。据我们所知,业界尚未有,对如此大规模复杂网络进行embedding建模的成熟应用。
本篇主要介绍我们近期在这个方向上所做的一些探索:针对推荐场景,在Graph Embedding基础上,提出了新的S³ Graph Embedding Model对上亿级别的商品进行embedding建模,并将embedding结果应用在商品Item to Item计算中,作为一种全新的match召回方式在手淘首图个性化场景进行应用。从线上BTS结果来看我们改进的Graph Embedding I2I得到不错的效果提升,在覆盖长尾用户以及新宝贝的冷启动上有效扩展了match召回候选。
1.1、Graph Embedding-DeepWalk算法
Graph Embedding是近期热门的一个课题,14年KDD的《DeepWalk: Online Learning of Social Representations》开启了这个方向的热潮,文中借鉴了深度学习在语言模型中的应用,以全新的方式学习网络节点的潜在向量表示,在社会化网络多标签网络分类任务中取得了很好的效果。
DeepWalk是一个two-stage算法:
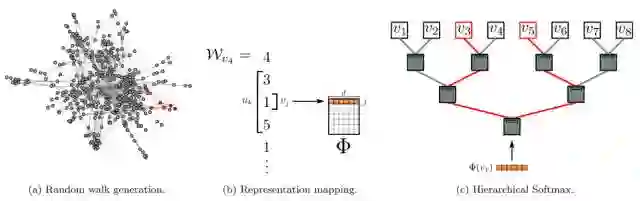
①构建同构网络,从网络中的每个节点开始分别进行Random Walk 采样,得到局部相关联的训练数据; ②对采样数据进行SkipGram训练,将离散的网络节点表示成向量化,最大化节点共现,使用Hierarchical Softmax来做超大规模分类的分类器;
DeepWalk框架:

SkipGram训练:
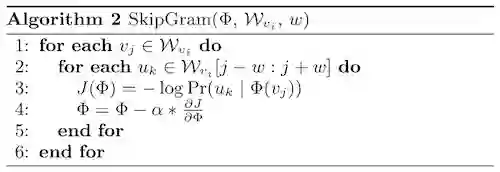
首先从网络中采样训练数据,每一个训练数据是由局部相邻的节点组成的序列,DeepWalk将这组序列看成语言模型中的一个短句或短语,将短句中的每个词转换成隐式表达,同时最大化给定短句某个中心词时,出现上下文单词的概率,具体可以表示为下面这个公式:

其中v_i是中心词(对应于网络中的target node),v_(i-w),···,v_(i+w)是上下文单词(对应于网络中的N阶近邻的node)。在独立分布的假设下,可以简化为:
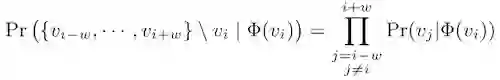
转自:阿里技术
完整内容请点击“阅读原文”





