【论文笔记】注意力机制的协同过滤模型 Attentive Collaborative Filtering(ACF)
导读
随着科技的发展,多媒体内容(图片、视频等内容)成为当今的网络信息的主要内容。为了在高度动态的环境中为用户筛选大量的多媒体内容。我们需要在网络多媒体内容中引入推荐系统,特别是基于协同过滤的系统,本文主要介绍一种加入了注意力机制的协同过滤模型 Attentive Collaborative Filtering(ACF)——旨在解决多媒体推荐中的项目与组件级隐式反馈问题。

符号及名词解释
-
item: 图片与视频 -
component : 图片的一块区域或者视频的一帧. -
item-level implicitness: 用户对于item的喜好是未知的(即使是喜欢,但喜欢程度未知) -
Component-Level implicitness:对于item的不同的component的喜好是未知的(视频的播放记录并不能说明用户喜欢这个视频的全部)。 -
多媒体中的隐式反馈(implicit feedback): 对照片的点赞、浏览的视频、下载的音乐等。 -
R: 表示 user_item交互矩阵(R∈R ^ { M * N},M和N分别表示用户和项目的数量。 ) -
R(i): 表示与用户i交互的所有项目集合 -
U = [u_1,...,u_i]表示用户潜在向量 -
V = [v_1,...,v_l]表示项目潜在向量 -
x_{lm}: 输入,表示项目l集合中第m个组件的特征 -
丨x_{l*}丨: 表示项目集合的长度 -
p_l: 表示辅助项目潜在向量,被用来基于用户交互的项目集上表示用户 -
~x_l: 表示内容特征,由Component级别的注意力模块求得 -
α(i,l): 项目级注意力模块权重,表示用户i在项目l中的偏好。 -
β(i,l,m): Component级注意力模块权重,表示用户i在项目l的第m个组成部分(component)的偏好程度
Bayesian Personalized Ranking( BPR )
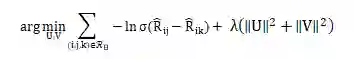
-
σ是sigmoid 函数 -
λ是正则化参数 -
^R_{ij}为 user_item交互矩阵,表示为:
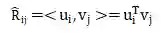
框架
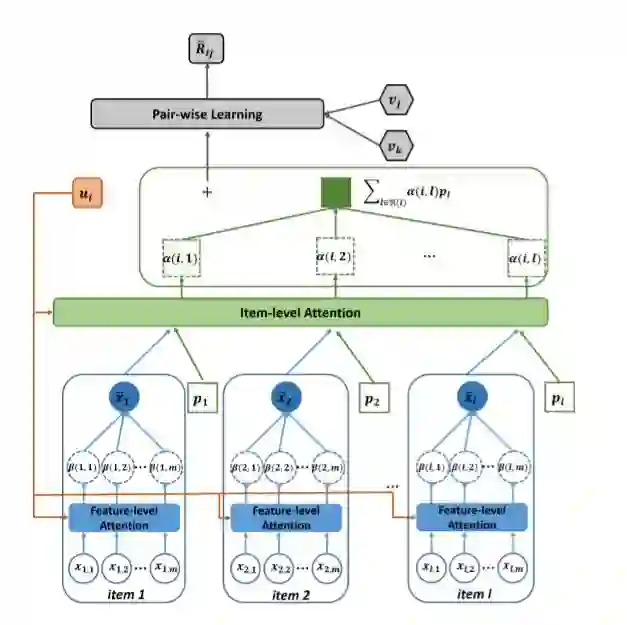
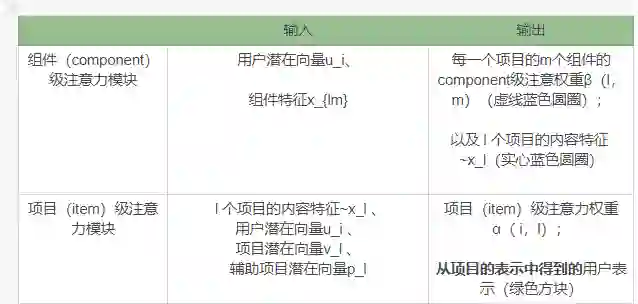
Component-Level Attention
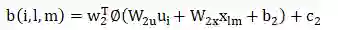
-
矩阵W_{2 *}和偏置b_2是第一层神经网络的参数; -
矢量w_2和偏置c_2是第二层参数; -
ϕ( )是RELU函数
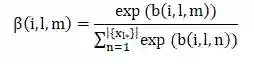
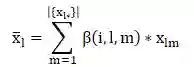
Item-Level Attention
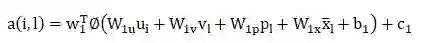
-
矩阵W-{1 *}和偏置b_1是第一层参数; -
矢量w_1和偏置c_1是第二层参数; -
ϕ( )是RELU函数
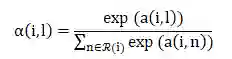
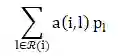
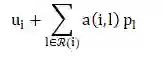
目标函数
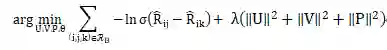
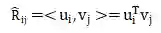
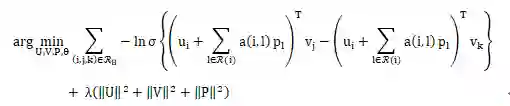

数据

特征提取
-
图片: 文中使用 ResNet152 架构中的res5 层提取得到图片的组件特征(x_{l*})。 例如: 对于每个图像,7×7×2048特征图可以被视为图像中49个不同区域的2048-D的49个特征向量。
-
视频: 对于每个视频,组件被认为是视频的一帧,使用ResNet-152中pool5层的输出作为每帧的特征向量。
参数设置
-
batch size: [256,512] -
潜在特征维度(latent feature dimension) :[32,64,128],在不指定维度时,只显示D=128的结果 -
学习率: [0.001,0.005,0.01,0.05,0.1] -
正则值: [0.00001,0.0001,0.001,0.01,0.1,0] -
K=100
评估方法
-
HR: 评价推荐的前 K个 items 中,有多少是能够命中用户实际偏好的。 该指标是评价召回率的(值越大越好),计算公式为:

-
NDCG:
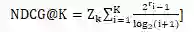
-
若top-K中第i个位置的项目在测试集中,r_i为1,否则·为0 -
Z_k为IDCG的计算公式,Z_k表示为:
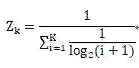
实验结果
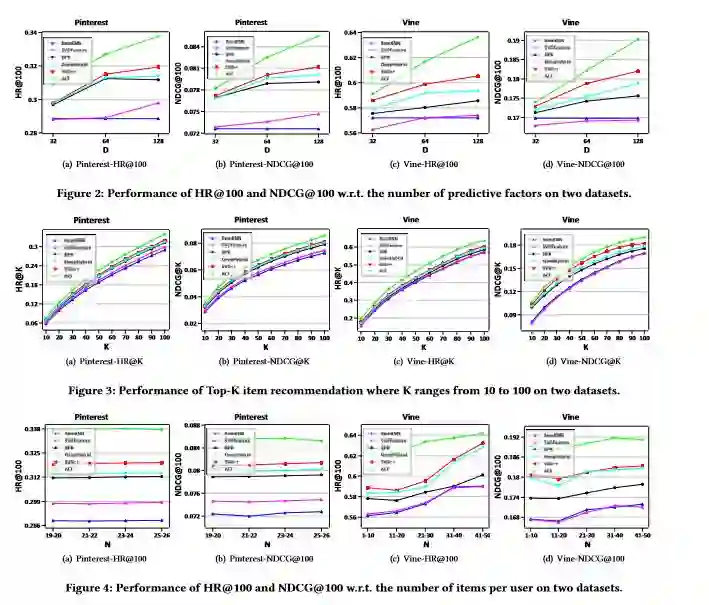
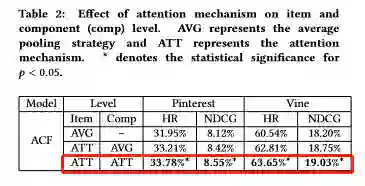
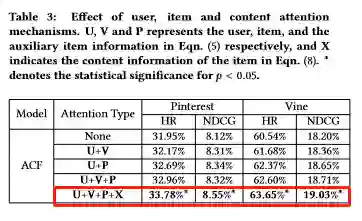
-END-
专 · 知
专知,专业可信的人工智能知识分发,让认知协作更快更好!欢迎登录www.zhuanzhi.ai,注册登录专知,获取更多AI知识资料!
欢迎微信扫一扫加入专知人工智能知识星球群,获取最新AI专业干货知识教程视频资料和与专家交流咨询!

请加专知小助手微信(扫一扫如下二维码添加),加入专知人工智能主题群,咨询技术商务合作~

专知《深度学习:算法到实战》课程全部完成!560+位同学在学习,现在报名,限时优惠!网易云课堂人工智能畅销榜首位!

点击“阅读原文”,了解报名专知《深度学习:算法到实战》课程
登录查看更多
相关内容

协同过滤(英语:Collaborative Filtering),简单来说是利用某兴趣相投、拥有共同经验之群体的喜好来推荐用户感兴趣的信息,个人透过合作的机制给予信息相当程度的回应(如评分)并记录下来以达到过滤的目的进而帮助别人筛选信息,回应不一定局限于特别感兴趣的,特别不感兴趣信息的纪录也相当重要。协同过滤又可分为评比(rating)或者群体过滤(social filtering)。其后成为电子商务当中很重要的一环,即根据某顾客以往的购买行为以及从具有相似购买行为的顾客群的购买行为去推荐这个顾客其“可能喜欢的品项”,也就是借由社群的喜好提供个人化的信息、商品等的推荐服务。除了推荐之外,近年来也发展出数学运算让系统自动计算喜好的强弱进而去芜存菁使得过滤的内容更有依据,也许不是百分之百完全准确,但由于加入了强弱的评比让这个概念的应用更为广泛,除了电子商务之外尚有信息检索领域、网络个人影音柜、个人书架等的应用等。
专知会员服务
32+阅读 · 2020年3月1日
Arxiv
5+阅读 · 2018年10月18日




相关VIP内容
专知会员服务
32+阅读 · 2020年3月1日
相关资讯