博客 | 梯度下降优化算法概述

本文首发于「美图数据技术团队」微信公众号,作者为吴艺
平时我们说的训练神经网络就是最小化损失函数的过程,损失函数的值衡量了模型在给定数据集下的表现(拟合)能力。
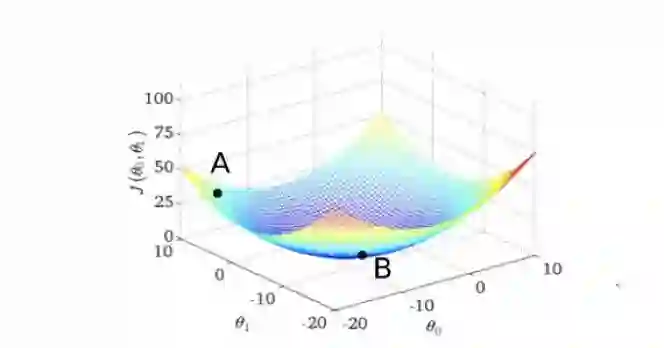
图 1
损失函数 J 如图 1 所示,B 点为函数最低点,设 A 点为初始值,那么优化器的作用就是指引初始值 A 点走向最低点 B 点,那么如何让这个过程执行的更加迅速呢?
梯度下降了解一下!
位于三维空间里的任意一个点都可以找到与之相切的平面,在高维的情况下也能找到超平面与其相切。那么在相切平面上的任意一个点都有多种方向,但只有一个方向能使该函数值上升最快,这个方向我们称之为梯度方向,而这个梯度方向的反方向就是函数值下降最快的方向,这就是梯度下降的过程。
基于以上概念我们进一步了解批量梯度更新 BGD,顾名思义,它就是一次性把所有样本同时计算之后得到梯度值,然后更新参数。这种方法十分简便,它对凸函数可以收敛到全局最优值,对于非凸函数则收敛到局部最优值。与此同时它缺点显而易见:在大数据量下内存占用巨大、计算时间久,并且无法进行在线更新。
面对 BGD 的瓶颈 SGD 应运而生,它每次只更新一个样本,相对比于 BGD ,它的收敛速度更快并且可以在线更新,有机会跳出局部最优。但 SGD 无法利用矩阵操作加速计算过程,考虑到上述两种方法的优缺点,就有了小批量梯度下降算法(MBGD),每次只选取固定小批量数据进行梯度更新。
而基于梯度更新也意味着面临一些挑战:
选择恰当的初始学习率很困难,学习率太大会妨碍收敛,导致损失函数在最小值附近振荡甚至偏离最小值;
非凸的损失函数优化过程存在大量的局部最优解或鞍点;
参数更新采用相同的学习率。
针对上述挑战,接下来为大家列举一些优化算法。
如果我们把梯度下降法当作小球从山坡到山谷的一个过程,那么在小球滚动时是带有一定的初速度,在下落过程,小球积累的动能越来越大,小球的速度也会越滚越大,更快的奔向谷底,受此启发就有了动量法 Momentum。
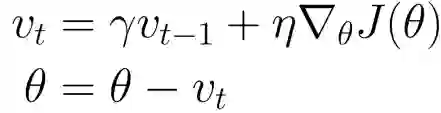
如上公式所示,动量法在当前梯度值的基础上再加上一次的梯度值与衰减率 𝛾 的乘积,这样可以不断累积上一次的梯度值。其中衰减率 𝛾 一般小于等于 0.9。加上动量项的 SGD 算法在更新模型参数时,对于当前梯度方向与上一次梯度方向相同的参数,则会加大更新力度;而对于当前梯度方向与上一次梯度方向不同的参数,则会进行消减,即在当前梯度方向的更新减慢了。因此,相较于 SGD,动量法可以收敛得更快,并且减少震荡。
在动量法中,小球下滚过程如果遇到上坡则会减小速度,那么更好的做法应该是遇到上坡之前就减慢速度。这就是 NAG 的大致思想,相较于动量法,NAG在计算参数的梯度时,在损失函数中减去了动量项,这种方式相当于预估了下一次参数所在的位置。公式如下:
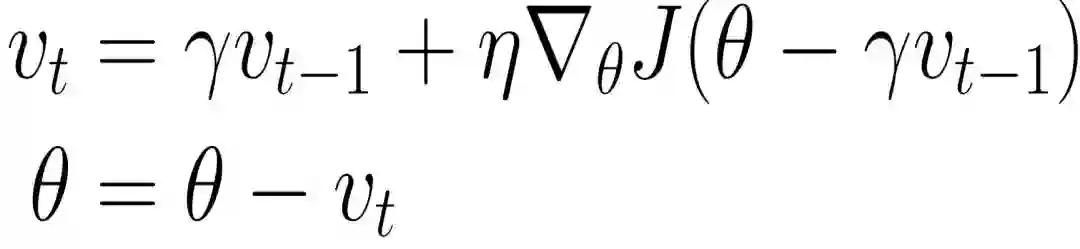
如图 2 所示,蓝色部分是标准的动量法更新过程,首先它会计算当前梯度,接着是累积梯度的大跳跃。而 NAG 则先来一个大跳跃(图中褐色向量),然后在跳跃后的地方计算梯度(下图红色向量)进行修正得到真正的梯度下降方向,即下图中的绿色向量。这样可能会避免产生振荡的情形,如应用于 RNN。
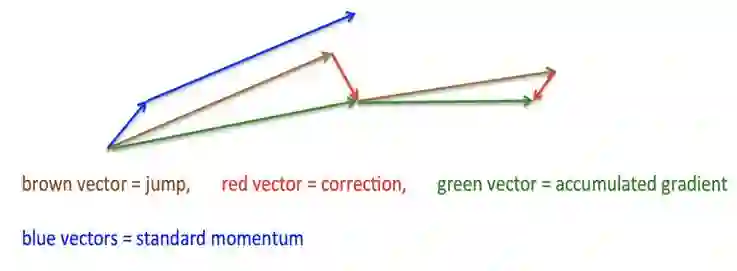
图 2
那能否根据参数的重要性自适应学习率呢?Adagrad 的提出思想是:在学习的过程中自动调整学习率。对于出现频率低的参数使用较大的学习率,出现频率高的参数使用较小的学习率。Adagrad 公式如下:
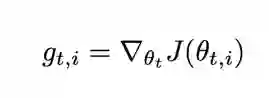
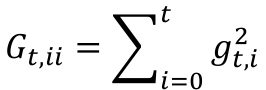
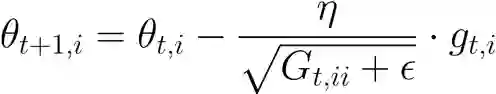
令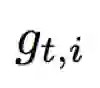
Adagrad 在数据分布稀疏的场景能更好利用稀疏梯度的信息,相比 SGD 算法能更有效地收敛。而它的缺点也十分明显,随着时间的增加,它的分母项越来越大,最终导致学习率收缩到太小无法进行有效更新。
Adagrad 的在日常利用率较高,同时也存在着很多「坑」希望大家尽量避免。以 TensorFlow 为例,θ 是防被除零的项,但 TensorFlow 只提供了累积梯度平方和的初始值,并且默认为 0.1。如果我们设置的较小时,会导致初始学习率偏大。实际使用中,可以调整此参数可能有意外收获。
Adadelta 是 Adagrad 的一种改进算法,更新过程中参照了牛顿法。
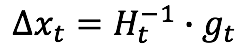
首先了解一下牛顿法(二阶优化方法),它利用 Hessian 矩阵的逆矩阵替代人工设置的学习率,在梯度下降的时候可以完美的找出下降方向,不会陷入局部最小值。
但是它的缺点十分明显,求逆矩阵的时间复杂度近似 O(n3),计算代价太高,不适合大数据。
上文指出 Adagrad 随着时间增加导致学习率不断变小导致过早收敛,Adadelta 采用梯度平方的指数移动平均数来调节学习率的变化:
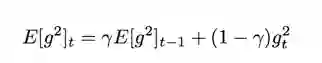
但论文中认为这个参数的更新没有遵循参数的单元假设,于是作者第二次尝试采用梯度平方的指数移动平均数来调整得到了:
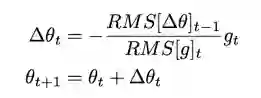
Adagrad 最大的变化是没有学习率的设置,但是到训练后期进入局部最小值雷区之后就会反复在局部最小值附近抖动。
RMSprop 是 AdaDelta 的一个特例,它由 Geoff Hinton 在公开课中提出,采用梯度平方的指数移动平均数来调整,当参数更新较大时会对它进行「惩罚」,它的公式如下:
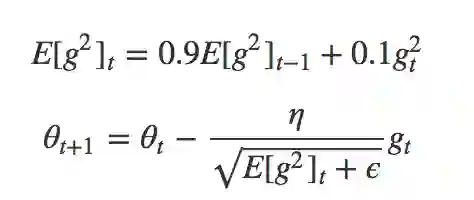
RMSprop 相对 Adagrad 梯度下降得较慢,被广泛应用在 CNN 领域。RMSprop 在 Inception v4 内取衰减因子 𝛽=0.9,参数 ε = 1.0 。
Adam 算法可以看作是 RMSprop 和动量法的结合体:
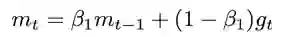
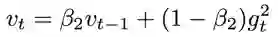
其中,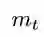
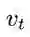
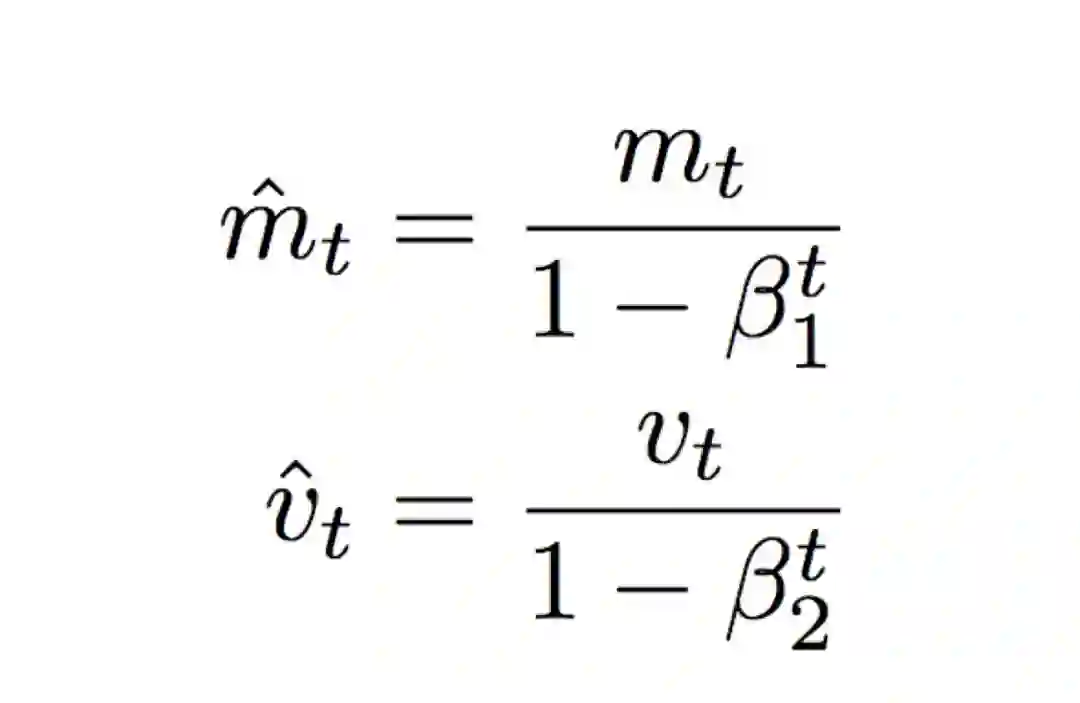
最后利用偏差修正后的
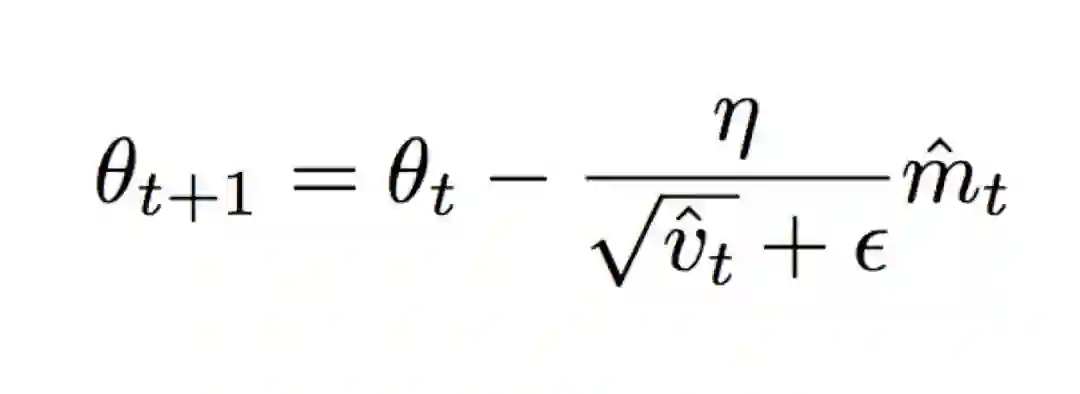
Adam 即 Adaptive Moment Estimation(自适应矩估计),类比于动量法的过程也就是有偏一阶矩估计过程,RMSprop 则对应于有偏二阶矩估计。在日常使用中,往往采用默认学习率 0.001 就可以取得不错的结果。
Adam 计算效率高,适用于稀疏数据&大规模数据场景,更新的步长能够被限制在合理的范围内,并且参数的更新不受梯度的伸缩变换影响。但它可能导致不收敛,或者收敛局部最优点。
由于 Adam 可能导致不收敛,或者收敛局部最优点,因此谷歌在 ICLR 2018 提出了 AMSGrad,该论文中提到这样一个问题:
对于 SGD 和 AdaGrad 可以保证学习率总是衰减的, 而基于滑动平均的方法则未必。实际上,以 Adam 为代表的自适应算法存在两个主要问题:
可能不收敛
可能收敛于局部最优点
RMSprop 会对最近增加的值提出比较大的更新,随着步数梯的增加慢慢消散它的作用;Adagrad 以梯度的平方进行累积,所以说基于滑动平均的方法不一定能够保证走势衰减。那么怎么确保学习率得到衰减?

AMSGrad 在二阶局部更新过程中通过取当前值与上一次的值的最大值用于计算∆𝑥,确保学习率的衰减。
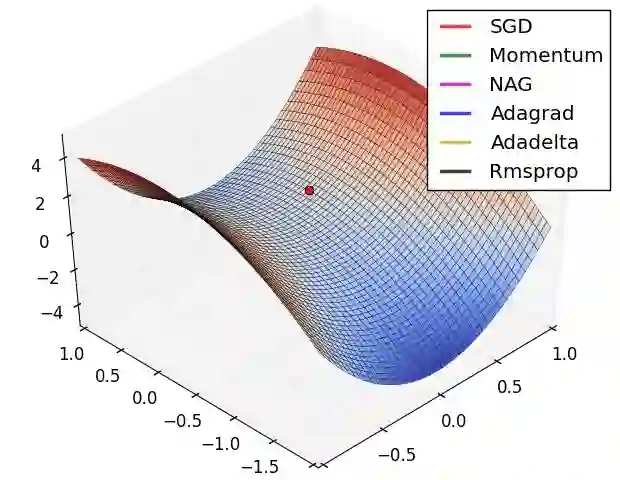
图 3
以上就是现有的主流梯度下降优化算法,总结一下以上方法,如图 3 所示,SDG 的值在鞍点中无法逃离;动量法会在梯度值为0时添加动能之后跳过该点;而 Adadelta 虽然没有学习率但在收敛过程非常快。
最后我们思考一个问题:怎么用现有的优化算法达到 state-of-art?
抛砖引玉,期待你们的更优答案:
1.SGD + Momentum
被大量用在CNN 、NLP 问题上
2.Adam + SGD
Adam加速收敛过程,可能陷入到局部最小值或无法收敛,此时用小学习率 SGD 帮助 adam 跳出局部最小值。





