肖之屏
1
,
宋卫平
2
,许皓彦
3
,任致澄
1
,
孙怡舟
1
本文被收录于KDD’20 Applied Data Science Track,并入选口头报告(Top5%)。
https://arxiv.org/abs/2006.01321
https://github.com/PatriciaXiao/TIMME (从推特官方
接口获取的20000个点的社交关系图,于2019年3月整理完毕)
论文简介视频:https://web.cs.ucla.edu/~patricia.xiao/projects/timme/KDD2020_TIMME.mp4
摘要
:
社交网络上的意识形态分类任务有很广阔的应用场景,也面临着一些挑战。本文从推特获取了数据,并拟用图嵌入模型解决此问题。主流的图嵌入模型研究仅关注规模小而稀疏,并且标签丰富的数据集,比如学术网络数据。而在真实应用场景中,存在规模更大且连接稠密,但是标签稀疏的数据,比如社交网络数据。这种大而稠密的数据使得主流嵌入模型效率很低,并且非常容易产生过拟合现象。另外,真实数据具有不完全性和异质性的特点,给图嵌入模型带来极大的挑战。能够解决此类问题的模型,理论上可以推广到任意的真实社交网络数据。本文提出了一种多任务多关系的嵌入模型,利用多种关系类型作为补充来处理规模大而标签稀疏的图数据,进一步提出了可以使得本模型能在特征缺失的情况下使用不完整的特征进行学习的方法。针对规模大而关系异质的问题,本文首先采用多关系的图卷积网络对特征进行编码;同时为了解决缺失特征的问题,当特征不完整时,将缺失部分的特征视作可训练的参数。然后采用多任务解码器,让多个任务互相协助,从而解决标签稀疏的问题。作者采集整理了真实的推特数据并且进行了意识形态分类,实验表明T
IMME
模型优于其他最先进的模型。
本文的代码和数据都已经公布,欢迎读者推广应用于其他真实社交网络数据的用户分类问题。
意识形态的分析是一个至关重要的课题。问卷调查等传统的方法十分耗时耗力,故难以形成规模并得到及时的结果。
电子信息时代,社交网络的普及,使得快速并且大量地采集普通人的意见成为可能,例如推特就是非常出色的意见采集来源。绝大部分美国政客都会在推特上开设并验证自己的官方账号,如果人们知道政客的党派,就可以给相关相关账号贴上意识形态(保守派或者自由派)的标签。
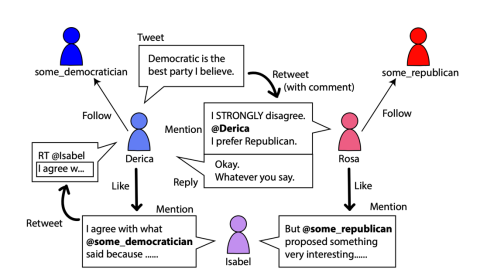
图
1
是
Twitter上不同关系类型的一个例子,其中德里凯森是自由派(左),罗莎是保守派(右),伊莎贝尔没有明显的派别倾向。
本文将用户视为节点,用户间的互动关系,例如图1中的关注、转发、提到、回复、喜欢等互动视为边,将意识形态分析视作实体分类(e
ntity classification
)问题。看起来这是一种经典的图数据,似乎可用图嵌入模型进行节点的分类,从而完成意识形态分析这个任务。
但是,推特用户间存在多种互动关系,是一种异构信息网络,因而有别于现有的绝大多数图数据。另外,推特数据的标签非常稀少,代表用户间互动关系的连边非常稠密。而且因为真实的推特数据集存在非常严重的数据缺失问题,例如,很多用户账号会被注销或被锁住,导致无法获取这些用户数据。这些特征给人们带来了特殊的挑战,迫切需要设计专门针对此类问题的模型。
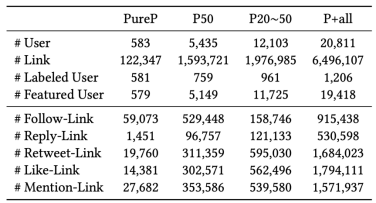
本文将作者收集并整理的推特数据集和代码一起公开了出来,统计信息如图2所示,希望能够对后续的研究者们起到一定帮助作用。本文数据集的一些棘手的特征,譬如特征的缺失和标签的极端稀疏,正是普遍存在于绝大多数真实社交网络数据上的客观挑战。
(1) 数据集的节点由政治家以及他们的部分存在关注或者被关注关系的一阶邻居构成,边是这些政治家之间存在的关系。
(2) 根据对节点不同的筛选标准,本文构建了4个不同大小的数据集。
(3) 关于数据的收集和整理,详见论文附录部分,本文的数据可以从
https://github.com/PatriciaXiao/TIMME/tree/master/data
直接获取。
(1) T
IMME
的e
ncoder
和d
ecoder
部分都同时考虑了多种关系以及这些关系之间的互相影响。
(2) T
IMME
使用了多任务学习的框架,引入链路预测(l
ink prediction
)任务,从而极大缓解了单纯依靠节点标签所要面临的监督信息不足的问题。
(3) 当有一部分节点的特征(f
eature
)无法获取,从而输入特征部分缺失的时候,T
IMME
可以灵活地将缺失部分的特征视作可学习的参数。因为参数变多,这部分有一些特殊处理,在论文中有所阐述,读者也可以参考代码实现细节。
(4) 实验中,作者发现模型并不需要目前较好质量的特征(由基于文本的G
loVe
平均值构成),所以本文的实验结果全部采用的是独热(o
ne-hot
)向量作为输入特征。
(5) 实验表明,
TIMME
比现存的最好模型都更加适合处理推特上的意识形态分析问题。
(6) 理论上,T
IMME
并不局限于处理意识形态分析问题。它可以用来处理标签极其稀疏的、关系类型多样的图模型中的实体分类问题。而且随着节点数增加,T
IMME
的时间复杂度是线性增长的。
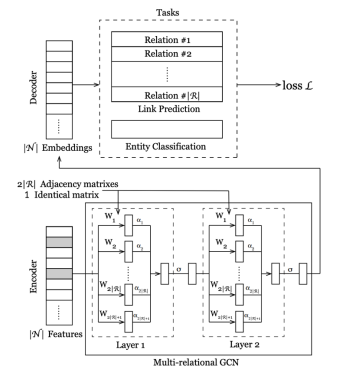
三、模型概览
T
IMME
模型如图
3所示
,模型由
encoder
和d
ecoder
组成。e
ncoder
由两层多关系卷积层构成。灰色块代表缺失的特征,本文将缺失特征视为可学习参数,或者采用
独热编码
。而d
ecoder
主要有两种不同的结构。其中,第一种模型结构T
IMME
基于R个链路预测任务和1个实体分类任务互相独立的前提假设而提出;第二种结构T
IMME-hierarchical
假定R个链路预测任务相互独立,但是实体分类任务可以利用链路预测任务的学习结果间接完成。第二种结构的好处在于它可以获得每种关系类型对于实体分类任务的重要性。换言之,T
IMME-hierarchical
可以揭示用户间的不同互动方式对其意识形态影响。
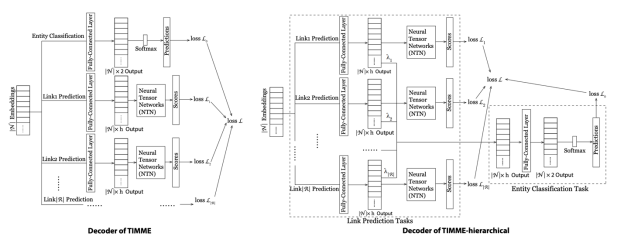
图4. 多任务框架的TIMME和TIMME- hierarchy两种类型的解码器
四、实验分析
T
IMME
模型在链路预测和实体分类任务上的表现胜过了所有b
aseline
模型。而且T
IMME
不需要很精准的调参。
有相当多的推特用户在个人账号
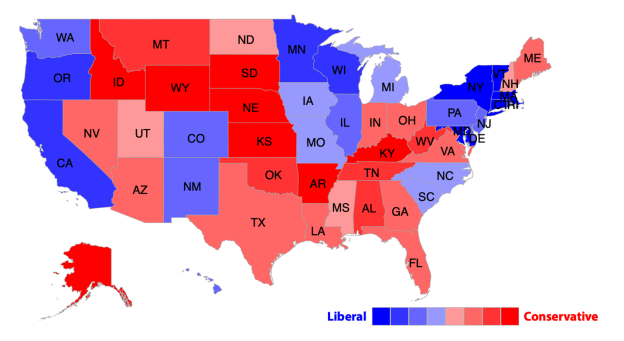
的信息页提供了自己所在的州,甚至是郡县市的信息,本文把这部分的用户信息加以整理,结合模型的预测结果,进行一个粗略的意识形态分布预测,如图
5
所示。
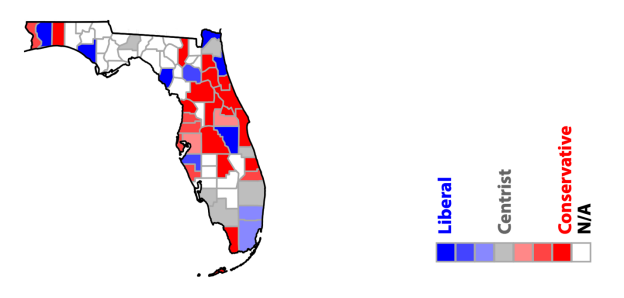
一些摇摆州(也就是在民主党和共和党之间倾向不明显,意识形态比较暧昧)的郡县级(郡县——c
ounty
,是美国的选区单位,一般比市大)预测结果也很有参考价值。其中,弗洛里达洲就是其中一个比较典型的摇摆州。
·
推特上的激进派(民主党)的存在感比保守派(共和党)强很多,如果完全根据社交网络数据进行预测,保守派的势力可能会被低估。
·
对于意识形态的预测问题而言,最可靠的关系类型往往是关注(f
ollow
)关系。
·
转发(r
etweet
)和提及(m
ention
)关系的存在使得喜欢(l
ike
)存在的可能性变高。
·
在此问题中,边的关系已经十分可靠,文本信息并非十分必要。
https://arxiv.org/abs/2006.01321
https://github.com/PatriciaXiao/TIMME
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
![]()
专知,专业可信的人工智能知识分发,让认知协作更快更好!欢迎注册登录专知www.zhuanzhi.ai,获取5000+AI主题干货知识资料!
欢迎微信扫一扫加入专知人工智能知识星球群,获取最新AI专业干货知识教程资料和与专家交流咨询!
点击“阅读原文”,了解使用专知,查看获取5000+AI主题知识资源