端到端对话模型新突破!Facebook发布大规模个性化对话数据库

更多干货内容请关注微信公众号“AI 前线”(ID:ai-front)
基于神经网络的端到端对话系统,在多种情况下都取得了突出的效果,例如使用双向 LSTM 或记忆网络直接在对话数据库上进行训练的模型。这种方法最主要的优势之一是吗,基于大量的数据源,模型可以在不需要其他专业知识的情况下,学习涵盖各种领域的对话。然而,在短时对话的情景下,这种模型的对话衔接性会出现明显的缺陷。这是由于它们缺乏一致性的性格特征,并且没有使用主动的调优策略。
为了解决这一问题,Facebook AI Research 的研究人员使用名为 PERSONA-CHAT 的数据库进行训练,该论文(https://arxiv.org/abs/1801.07243) 发表于 NIPS2018。PERSON-CHAT 数据库包含超过 16 万条对话,与传统对话数据库不同的是,改数据库赋予每个对象一种实例化的人格,这将有助于提高模型在对话过程中的一致性。论文中提到,将一个端到端的系统限制在某种给定的人格环境下,可以有效的提高聊天 机器人的对话一致性。这成为了训练端到端的个性化聊天机器人的敲门砖。然而,PERSONA-CHAT 数据库是一个人工数据集,它是由基于 Mechanical Turk 的系统生成的。因此,无论是对话内容还是人物角色的数量都不能涵盖真实的用户 - 机器人式的交互场景,该数据集仅包含了超过 1000 个不同的人物角色。
针对 PERSONA-CHAT 存在的缺陷,Fackbook 的研究人员建立了一个基于人物对话的大规模数据库。经过简单的预处理,研究人员使用从 REDDIT(一个大型社交新闻站点) 的收集到的对话进行整理,得到了超过 500 万种人格的超过 7 亿条对话。研究人员在这个数据集上进行训练,与在 PERSONA-CHAT 上训练的同结构模型相比,取得了更好的效果。此外,在该数据库上进行预训练后的模型 PERSONA-CHAT 数据库上也取得了目前领先的结果。
我们的目标是在多样化的人物角色中学习一种基于人物的回复。从这点出发,我们使用源自 REDDIT 的数据建立了以下形式的数据库:
角色:["I like sport","I work a lot"]
语境:"I love running."
回复:“Me too! But only on weekends.”
“角色”是一系列可以表示聊天机器人角色特征的语句,“语境”是指需要对其作出应答的句子,“回复”是需要作出的回答。这便是该数据库的基本形式,建立一个这样的数据库通常需要以下这些步骤:
数据预处理:这一步的主要工作是将原始的语句进行标记化,经过处理,研究人员获得了超过 25 万个常用的 token。
角色提取:通过收集同一个用户的评论,并使用既定的规则进行筛选,可以得到不同性格和背景的“角色”,以及“角色”所对应的“语境”与“回复”。具体的规则在论文的 3.2 部分有详细说明,感兴趣的读者可自行阅读。上面的示例中的 persona 便是这一部分期望得到的结果,但有的时候,“回复”并不一定跟“角色“”有明显的对应关系,这是因为同一个用户可能会发表矛盾的言论。
数据集创建:将“语境”和“回复”进行组合,便得到一组样例。与“回复”相对应的人物角色可由第二步中的方法进行提取。随后将数据库随机划分为训练集、验证集和测试集。验证集和测试集保含超过 5 万组样例。仅适用训练集提取人物角色:测试集的“回复”不能被明确的包含于某个特定“角色”。
这篇论文使用语言检索 (next utterance retrieval) 的方法建立对话系统,语言检索的方法是指通过在一组候选语句中选择一个最佳语句做为对话的回复,而不是通过生成的方法得到回复。
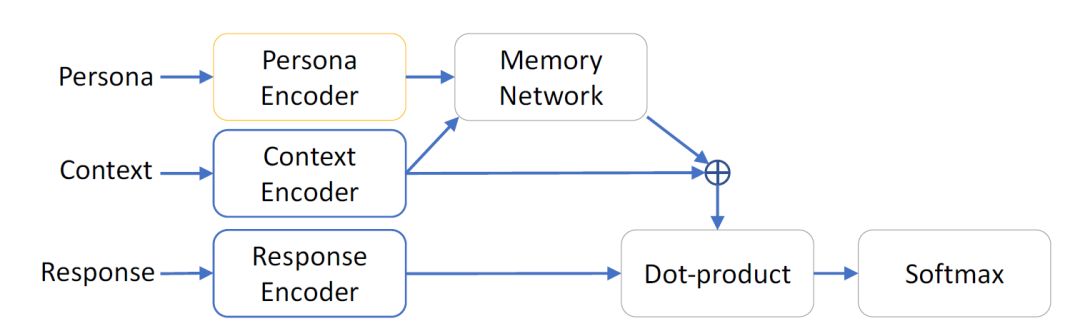
图 1:Persona-based network architecture
该模型的框架如图 1 所示,论文使用了两个分离的模块对人物和语境进行编码,然后使用 1-hop 记忆网络和残差学习的方法对编码结果进行组合得到一种联合表示。参考 PERSONA-CHAT 这篇论文,本文的作者使用了与其类似的方法也对候选的回复进行了编码,并计算了其与上述联合表示的点积。预期的回复应当是使得该点积最大化的候选语句。
训练过程使用 softmax 分类器对点积的效果进行约束并最大化正确回复的对数似然比。在训练过程中,对于某个样例,还使用了其他样例的回复作为负样本进行训练以提高模型的泛化能力。
语境和回复编码器使用了相同的网络结构与词嵌入,但使用不同的权重。本文的作者使用了以下三种不同的编码器结构作为语境和回复编码器的结构:
Bag-of-words:使用两个线性映射对输入语句进行词嵌入 (word embedding),然后对一句话中所有的编码表示进行求和并除以 sqrt(n),其中 n 是这句话的长度(译者注:可以理解为一种归一化处理)。
LSTM:使用两层双向 LSTM 网络,将最后一个隐层的输出当作编码后的语句。
Transformer:该结构是由 Vaswani 等人于 2017 年提出的一种端到端的记忆网络。基于自注意力机制,在语言检索任务 (next utterance retrieval) 上取得了领先的效果。本文仅使用了该网络的编码器部分,然后进行归一化得到固定大小的表示。
针对每个人物角色,人物角色编码器都会分别编码。它使用和语境编码器相同的词嵌入方法。然后对这句话中所有的编码表示求和。由于对于每个人物角色,都需要不同的编码器进行训练,因此本文的作者专门选择了更简单的编码器结构作为人物角色编码器。这是由于在一个 mini-batch 中,人物角色编码器的个数比其他编码器个数大一个数量级。并且,大多数的人物角色数据都是一些短句,因此作者使用了 bag-of-words 表示直接作为其编码表示。
针对上述的编码器,本文作者使用了 Adamax 对网络进行优化,其中学习率为 8e-4,mini-batch 的大小为 512。同时,本文使用了 FastText 词向量进行初始化,并在训练过程中对其进行了优化。其他具体的训练参数可阅读英文原文。
在 reddit 任务上的结果,本文使用了不同的结构进行了实验,结果如下表所示:
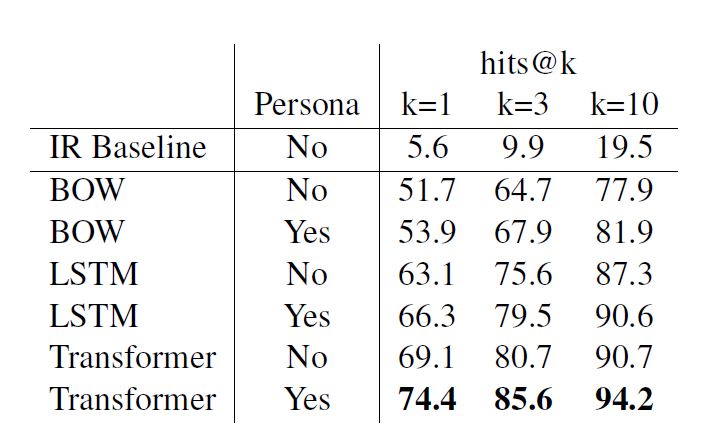
可以看出对于三种不同的编码器结构,增加人物角色信息都可以有效的提高检索精度。图 2 是经过训练后模型的部分结果示例,可以看出聊天机器人系统给出的回答基本符合它的个性化人物角色属性。

图 2:最好模型的预测结果。
所有的情景中人物角色由一个单句组成,回复被限制在为包含 10 个 token 的短句,它是从 100 万个从训练集中随机选择的候选句中检索到的。
本文比较了使用 PERSONA-CHAT 和 REDDIT 两种数据库进行迁移学习的效果,实验结果如下表所示:
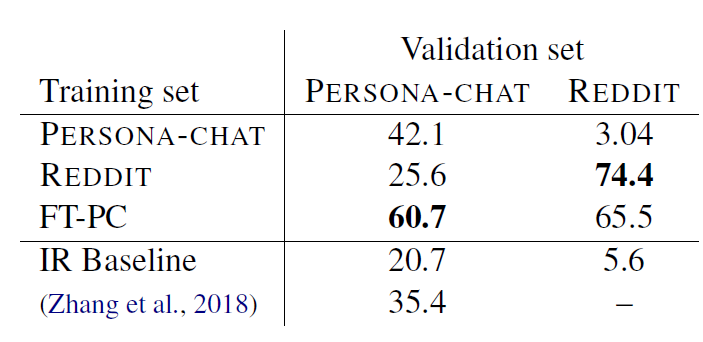
可以看出在 POERSONA-CHAT 数据库上进行训练的模型直接在 REDDIT 数据库上的验证效果很差,而在 REDDIT 数据库上训练的模型在 PERSONA-CHAT 数据集上可以表现出不错的效果。表中的 FT-PC 意为:在 REDDIT 数据库上进行训练并在 PERSONA-CHAT 进行微调。可以看出使用 REDDIT 预训练后的模型迁移到 PERSONA-CHAT 数据库上的效果远优于在 PERSONA-CHAT 上直接训练的效果。
英文论文原文:
https://arxiv.org/pdf/1809.01984.pdf

如果你喜欢这篇文章,或希望看到更多类似优质报道,记得给我留言和点赞哦!



