【ICML2020】用于强化学习的对比无监督表示嵌入
论文标题:CURL: Contrastive Unsupervised Representations for ReinforcementLearning(CURL:用于强化学习的对比无监督表示)
论文下载:https://www.zhuanzhi.ai/paper/6fb5994c1f98b326b45fb83ce319f0b9
代码链接:https://github.com/MishaLaskin/curl
摘要:
我们提出CURL:用于强化学习的对比无监督表示法。CURL使用表示学习从原始像素中提取高级特征,并在提取的特征上执行off-policy控制。在DeepMind控制套件和Atari游戏中,CURL在复杂任务中的表现优于之前基于像素的方法,无论是基于模型的还是无模型的,在100K环境和交互步骤的基准测试中,分别获得1.9倍和1.6倍的性能提升。在DeepMind控制套件中,CURL是第一个与使用基于状态特征的方法的采样效率和性能接近的基于图像的算法。
1.1 总体网络架构
从缓冲区采样一批转换后的观察数据,观察数据被扩充两次以形成query观察值和key观察值,然后分别用query编码器和key编码器对它们进行编码。query被传递给RL算法,而query-key对被传递给表示学习目标。在梯度更新步骤中,只有query编码器被更新,key编码器权重是query权重的moving average (EMA)。如下图所示:
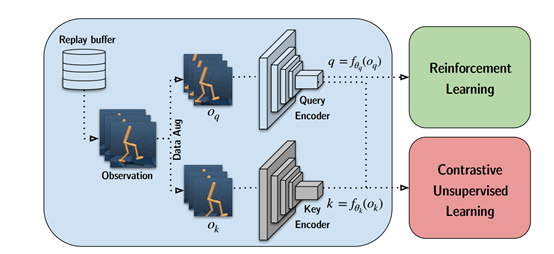
1.2 总体思路
Contrastive Unsupervised Representations for Reinforcement Learning (CURL) 结合实例表示学习和强化学习,CURL通过确保嵌入的数据扩充版本


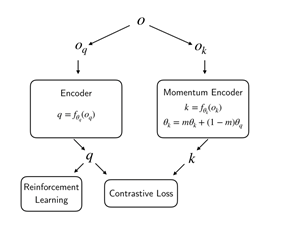
CURL的一个关键组件是使用对比无监督学习来学习高维数据的丰富表示。通俗来讲就是在正常强化学习的信号基础上,同时加上表示学习的信号。对于一个observation(一般是四帧图像输入),对其做数据增广。同一个样本上做数据增广得到的样本作为正样本,不同数据上做数据增广得到的样本作为负样本。然后使用相应的contrastive loss作为损失函数。即下公式:

其中,q表示anchor,


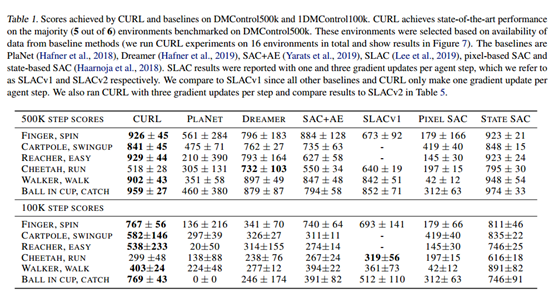
在DMControl (DeepMind Control Suite)各个任务分别的性能。
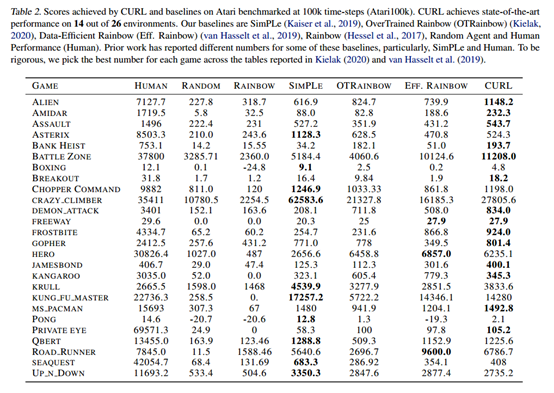
在Atari上的结果。

参考链接:
矿大人工智能社团
https://mp.weixin.qq.com/s/Na0mNHJb3wQaHb6Kj1iZfg
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“CURL” 可以获取《ICML2020-用于强化学习的对比无监督表示嵌入》专知下载链接索引





