学界 | DeepMind提出对比预测编码,通过预测未来学习高级表征
选自arXiv
作者:Aaron van den Oord、Yazhe Li、Oriol Vinyals
机器之心编译
参与:Nurhachu Null、张倩
本文提出了一种通用的无监督学习方法——对比预测编码,从高维数据中提取有用的表征。该方法的核心是通过使用强大的自回归模型预测潜在空间的未来,以学习高级表征。论文证明,该方法能够学习有用的表征,在 3D 环境中的语音、图像、文本和强化学习四个不同的领域表现出优异的性能。
1. 引言
在端到端的潮流下使用分层可微分模型从有标签的数据中学习高级表征是人工智能目前最大的成功之一。这些技术使得人工设计的特征很大程度上都显得多余了,并且也提升了好几个实际应用中的当前最佳技术水平 [1,2,3]。但是,该领域仍存在很多挑战,例如数据的有效性、鲁棒性以及泛化能力。
提升表征学习不太需要专门用于解决单个监督任务的特征。例如,在预训练一个模型用于图像分类时,所产生的特征能够很好地迁移到其他图像分类域中,但是缺少与颜色或者计数能力相关的信息,这些信息与分类无关,但是与图像描述等任务相关 [4]。类似地,对转录人类语音有用的特征可能不太适用于说话人身份验证或者音乐流派预测。所以,无监督学习是实现鲁棒和通用表征学习的重要跳板。
尽管无监督学习非常重要,但是它还没有取得与有监督学习类似的重大突破:从原始数据中对高级表征进行建模还是很难得一见。此外,理想的表征是什么,以及在没有额外的监督或者没有某个特定的数据模态下的监督时,是否有可能学到这种表征,这些并不总是非常清晰。
无监督学习中的一个常见策略就是预测未来的、缺失的或者上下文中的信息。这种预测编码 [5,6] 的思想是用于数据压缩的最古老的信号处理技术之一。在神经科学中,预测编码理论认为大脑在不同的抽象水平预测观察 [7,8]。无监督学习领域的最新研究已经成功地利用这种思想通过预测临近词来学习词表征 [9]。对图像而言,从灰度值或者图像块的相对位置来预测颜色也被证明是有用的 [10,11]。我们假设这些方法是有效果的,部分原因是我们从中预测相关值的上下文经常是有条件地依赖于相同的高级别潜在信息。通过将此作为一种预测问题,我们自动地推理这些表征学习感兴趣的特征。
在这篇论文中,我们提出了以下内容:首先,我们将高维数据压缩到更加紧密的潜在嵌入空间,这个空间中条件预测更容易建模。接下来,我们在这个潜在空间中使用强大的自回归模型来做多步未来预测。最后,对损失函数,我们依靠噪声对比估计 [12],这是与自然语言模型中用于学习词嵌入类似的方式,需要整个模型以端到端的形式进行训练。我们将最终的模型(对比预测编码,CPC)用在了很多不同的数据模态中,包括图像、语音、自然语言和强化学习,结果表明同样的机制在每一个领域中都学到了有趣的高级表征,而且优于其他方法。
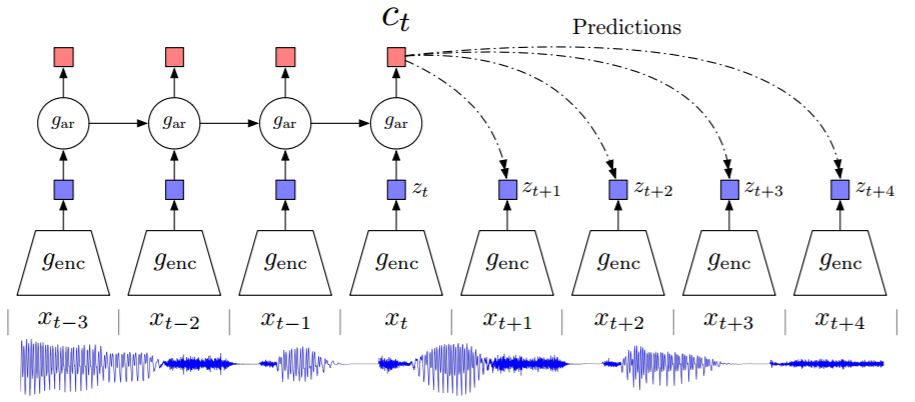
图 1: 论文提出的表征学习方法——对比预测编码(CPC)概览。尽管此图仅仅展示了使用音频作为输入的情况,但是我们对图像、文本以及强化学习都做了相同的实验设置。
3. 实验
3.1 音频
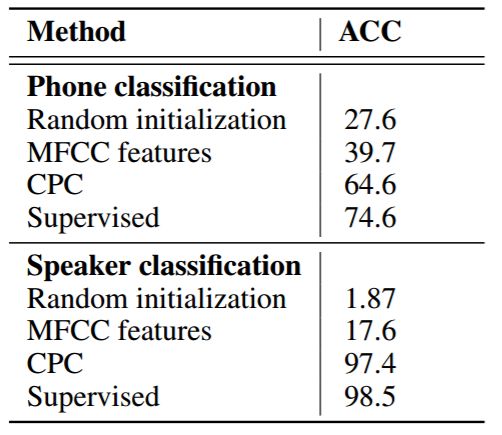
表 1: LibriSpeech 数据集上的音素分类和说话人分类结果。音素分类共有 41 个可能的类别,说话人分类共有 251 个可能的类别。所有的模型都使用相同的结构和相同的音频输入大小。
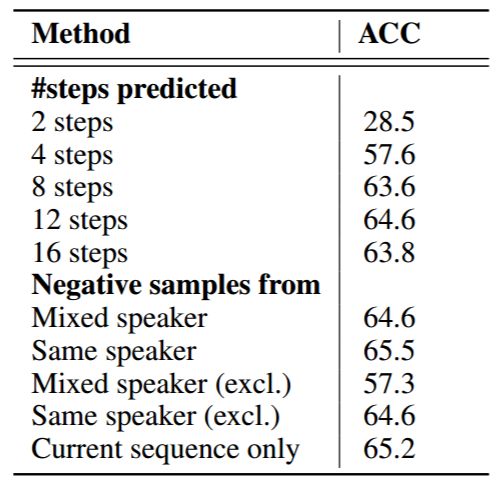
表 2: LibriSpeech 数据集中音素分类的 ablation 实验。论文的 3.1 部分会有更多细节。
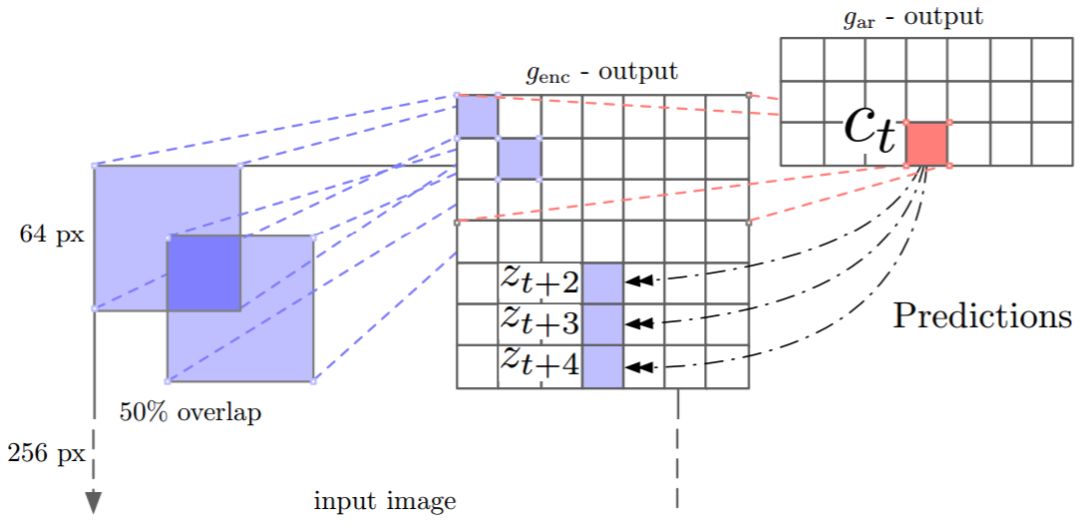
图 4:图像对比预测编码的可视化(这是图 1 的二维适应)
3.2 视觉
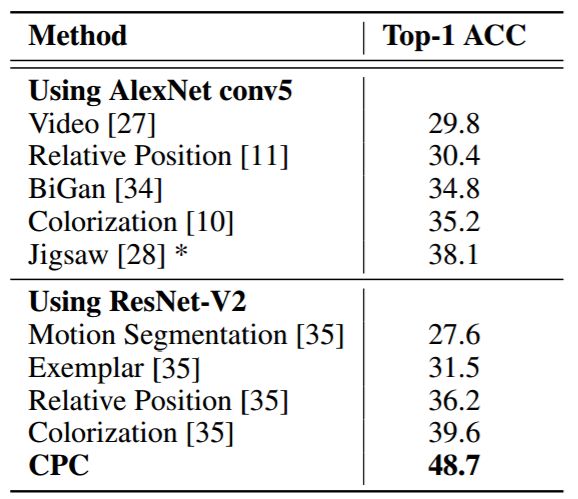
表 3: ImageNet 无监督分类的 top-1 结果。由于架构差异,Jigsaw 无法与其他 AlexNet 结果直接比较。
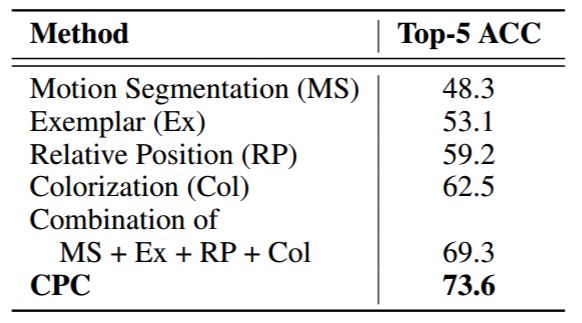
表 4: ImageNet 无监督分类的 top-5 结果。之前使用 MS、Ex、RP、Col 得到的结果来源于 [35],是这项任务上的最佳报告结果。
3.3 自然语言
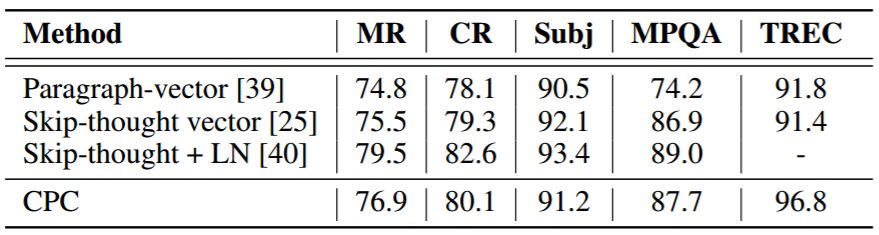
表 5: 5 个常见 NLP 测试基准上的分类准确率。我们遵循与 skip-thought vector 一样的迁移学习设置 [25],使用 BookCorpus 数据集作为迁移源。[39] 是学习句子级别表征的一种无监督方法。[25] 是一种可选择的无监督学习方法。[40] 是使用层正则化迭代一百万次训练得到的 skip-thought 模型。
3.4 强化学习
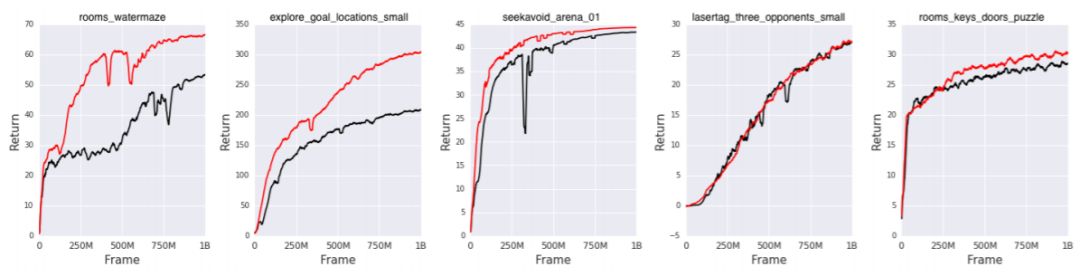
图 6: [49] 中使用的 DeepMind 实验室中 5 个任务上的强化学习结果。黑色:分批 A2C 基准,红色:辅助对比损失
论文:Representation Learning with Contrastive Predictive Coding

论文链接:https://arxiv.org/pdf/1807.03748.pdf
摘要:虽然监督学习在许多应用中都取得了很大进展,但无监督学习并没有得到如此广泛的应用,它仍然是人工智能的一项重要而富有挑战性的工作。本文提出了一种通用的无监督学习方法,从高维数据中提取有用的表征,我们称之为对比预测编码。论文所述模型的关键思想是通过使用强大的自回归模型预测潜在空间的未来,以学习这些表征。我们使用一种概率对比损失,这种概率对比损失诱导潜在空间捕获最有助于预测未来样本的信息。采用负采样也使模型易于处理。虽然之前的大多数研究都集中在评估特定模态的表征上,但是我们证明,我们的方法能够学习有用的表征,在 3D 环境中的语音、图像、文本和强化学习四个不同的领域表现出优异的性能。

本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com


