点击上方“计算机视觉life”,选择“星标”
快速获得最新干货
本文转载自AI科技评论
![]()
现在只需要一个AI算法,你也可以拥有这件“AI隐身衣”。
视频“擦除”,这个AI就够了
在视频后期处理中,经常会遇到一项难搞的需求:如何把一个人/物从视频中完美剔除?虽然Ps技术已经很普及,但也很难处理视频问题。
而现在,只需要一个名为光流边缘引导(Flow-edge Guided)的AI修复算法,这项耗时又费力的工作分分钟就可以搞定。
![]()
背景也被高度还原,看不出一点痕迹,比如下图女孩消失后,秋千依然还在。
![]()
另外,它也能处理更复杂的场景和物体,比如还有漂浮在海上的帆船,正在跨越栏杆的赛马选手。
![]()
如此完美的视频处理效果,也让网友惊呼:现实版《真相捕捉》,视频可能再也不是可靠的证据。
![]()
研究人员表明,这款AI算法在视频物体移除、去水印和画面扩展方面均达到了目前的最佳SOTA。而且它还刚刚还被ECCV 2020顶会收录。
![]()
ECCV全称欧洲计算机视觉国际会议(European Conference on Computer Vision),是计算机视觉三大会议之一,每两年举办一次,论文录取率仅为27%。
这项“隐身”AI修复技术,主要采用的是光流边缘引导修复算法。
与现有方法相比,该算法能够更精准的识别目标物体的运动边界。
现有算法主要通过相邻帧的局部流连接传播色彩,这种方式不能保证所有视频在删除目标物体后,其背景都能恢复原貌,因此,很容易留下伪影。
![]()
该算法通过引入非局部流连接(Non-local Flow Connections)解决了这个问题,并使得视频内容能够在运动边界上传播。
通过在DAVIS数据集上的验证,其可视化和定量结果都表明,该算法具有更好的性能。
具体来说,它主要是通过以下几个方面的改进实现了最终的效果:
-
光流边缘(Flow edges):补全分段光滑流。(图1b)
-
非局部流(Non-local flow):连接不能通过传递流(transitive flow)到达的区域。(图1C)
-
无缝融合(Seamless blending):通过在梯度域中执行融合操作避免结果中的可见接缝(图1d)。
-
内存效率(Memory efficiency),处理4K分辨率的视频,其他方法由于GPU内存需求过大而无法实现。
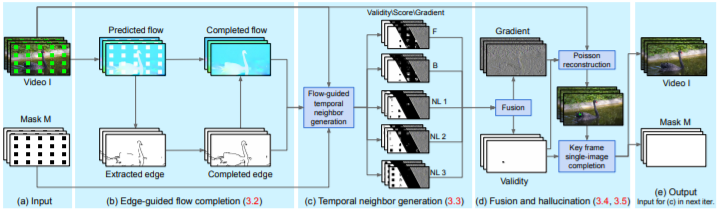
以下是实现过程的完整架构图,图1a部分是模型的输入源,由彩色视频和二进制的掩码视频两部分构成其中,被遮罩的像素称为缺失区域,代表需要合成的部分。
计算相邻帧之间的正向和反向流以及一组非相邻帧,并补全这些流场中的缺失区域。(缺失区域的值往往为零,白色)
![]()
由于边缘通常是流映射中最显著的特征,因此首先完成边缘的提取,然后,再以补全之后的边缘为导向,逐步完成分段平滑流。
(2) 时间传播(Temporal propagation)
接下来,沿着流的轨迹为每个丢失像素传播一组候选像素。从链接前向和后向的流向量得到两个候选点,直到到达一个已知像素。
这一过程利用的是非局部流向量:通过检查三个时间间隔的帧来获得另外三个候选帧,对于每个候选者,估计一个置信分数以及一个二进制有效性指标。
![]()
如图,绿色区域代表缺失部分,黄色、橙色和棕色线分别代表第一个非局部帧、当前帧和第三个非局部帧的扫描线。
通过跟踪流动轨迹(黑色虚线)达到缺失区域的边缘,可以获得蓝色像素的局部候选对象。但由于人腿部运动形成的流动障碍,无法获取红色像素的候选对象。
在这里研究人员借助于连接到时间距离帧的非局部流,获得了红色像素的额外非局部邻域,并还原了腿部覆盖的真实背景。
使用置信加权平均值(A Confidence-weighted Average)将每个缺失像素的候选像素与有效候选像素进行融合(至少一个)。这一过程在梯度域内进行,以避免可见的彩色接缝(图2d)。
如果在此过程之后仍有缺失的像素,且无法通过时间传播来填充,将采用一个关键帧,使用单个图像完成技术来填充它。
最后将整个过程不断迭代输入,并将结果传播到视频的其余部分,以便在下一次迭代中加强时间一致性。
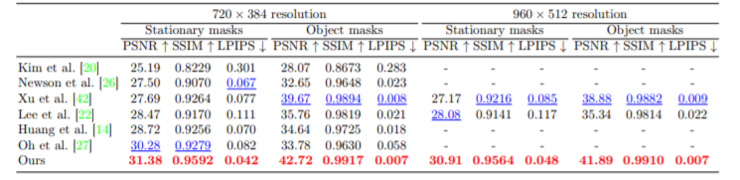
论文中,研究人员利用DAVIS数据集,与其他六种现有方法进行了比较,并进一步评估了PSNR,SSIM和LPIPS三项指标。
由于内存限制,并不是所有的方法都能处理960×512的分辨率,所以将其缩小到了720×384,并报告了两种分辨率的数值。结果显示,在这三个指标上,本次研究算法性能表现最佳(红色加粗数据)。
![]()
另外,在光流补全方面,与最新进的Diffusion和徐瑞(商汤)的算法相比,该方法也能更好地呈现锐利且平滑的运动边界。
![]()
此外,在修复任务(前三列)和对象移除任务(后三列)方面,也有视觉上也有更好的体现。
![]()
这篇论文由四位研究人员合力完成,包括弗吉尼亚大学的Chen Gao和Jia-Bin Huang,以及Facebook的Ayush Saraf和Johannes Kopf。其中,Chen Gao是本篇论文的一作。
![]()
Chen Gao是弗吉尼亚大学的一名在读博士,专攻计算摄影和计算机视觉领域,研究重点是图像/视频操作和场景理解。在此之前,曾就读于密歇根大学和俄勒冈州立大学。
2019年夏季,Johannes Kopf博士的帮助下,Chen Gao成为了Facebook Seattle的一名研究实习生,并且与其团队成员合作完成了这篇论文,此外,他还是Google的研究实习生,与Shi Yichang Chang和Lai Wei-Sheng Li都有过深度合作。
项目主页:http://chengao.vision/FGVC/
项目论文:http://chengao.vision/FGVC/files/FGVC.pdf
视频专辑:最新计算机视觉应用/论文/开源
专辑:计算机视觉方向简介
专辑:视觉SLAM入门
专辑:最新SLAM/三维视觉论文/开源
专辑:三维视觉/SLAM公开课
专辑:深度相机原理及应用
专辑:手机双摄头技术解析与应用
专辑:相机标定
专辑:全景相机
从0到1学习SLAM,戳↓
视觉SLAM图文+视频+答疑+学习路线全规划!
![]()
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~
投稿、合作也欢迎联系:simiter@126.com
![]()
扫描关注视频号,看最新技术落地及开源方案视频秀 ↓
![]()