加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~
来源:机器之心@微信公众号
作者:张浩天等
参与:魔王
用各种修图技术 P 掉图片里的指定内容往往很难不着痕迹,抹掉视频里的流动内容就更难了。但近日,Adobe 提出了一种基于 Deep Image Prior 的新型视频修图算法,可以同时修复缺失图像和移动(光流)信息,增强视频的时间和空间连贯性,使得去掉某些内容之后的视频依然自然、流畅,毫无修图痕迹。而且,该方法无需外部数据库,仅通过视频内部学习即可实现。
论文链接:
https://arxiv.org/abs/1909.07957v1
Adobe 的研究人员将 DIP 从静止图像扩展到视频领域,在此过程中他们做出了以下两大重要贡献:
研究者证明,利用每个视频的外观数据可以获得视觉合理的修复结果,同时还能处理长期连贯性这一难题。
研究贡献
该研究受 Deep Image Prior 的启发,提出一种基于内部学习的视频修复方法。
DIP 最惊人的结果是:
自然图像的「知识」可以通过卷积神经网络(CNN)进行编码,即 CNN 网络架构,而非实际的滤波器权重。
CNN 的平移不变性使得 DIP 能够利用图像中视觉图案的内部循环(internal recurrence),该方式与基于图像块的经典方法 [19] 类似,但表达性更强。
此外,DIP 无需外部数据集,因而其遭遇指数级数据问题的概率较小。
研究者尝试将 DIP 方法扩展至视频修复领域,作为从外部数据集学习先验知识的替代方法。
该研究的核心贡献是:
提出了首个基于内部学习的视频修复框架。
该研究证明,基于视频内数据训练的逐帧生成式 CNN 也有可能输出高质量的视频修复结果。
研究者研究了不同内部学习策略对解决视频修复时间连贯性问题的效果,开发出基于联合图像和光流预测的训练策略,该策略可以感知到视频连贯性。
这一方法不仅使网络捕捉到短期运动连贯性,还能将该信息传播到不同帧,从而高效解决长期连贯性问题。
研究表明,该方法可以实现当前最优的视频修复结果。
作为基于网络的框架,该方法可以纳入 CNN 学得的自然图像先验,以避免基于图像块方法中常出现的变形现象(见下图 1)。
相比于基于帧的基线方法(第 2 行),Adobe 提出的内部学习视频修复框架的修复结果连贯性更强,即使是对于多个帧中看不到的内容(橙色框)。作为基于网络的合成框架,Adobe 提出的方法可以利用自然图像先验避免变形,而这在基于图像块的方法(如 [16],第 3 行)中经常出现(红色框)。
从 DIP 到基于内部学习的视频修复方法,经历了什么?
将 DIP 扩展至视频领域的一项重要挑战是确保时间连贯性:内容不应该出现视觉伪影,相邻帧之间应该展现出平滑的运动(光流)。这对视频修复而言难度尤其高,因为像素具备时间对应性才能生成缺失内容,而这种对应也可实现内容的时间流畅度。
Adobe 通过同时合成外观和运动打破了这个循环,它通过编码器-解码器网络生成内容,该网络不仅在视觉领域利用 DIP,同时也在运动方面利用了 DIP。这就可以同时解决外观修复和光流修复问题,保持二者之间的一致性。研究证明,同时预测外观和运动信息不仅能够提升空间-时间连贯性,还能更好地在较大空洞区域传播结构信息,从而提升视觉合理性。
基于内部学习的视频修复方法
其中 T 表示视频中的帧数,M_i 表示每个帧 I_i 中已知区域的二元掩码(1 表示已知区域,0 表示未知区域),⊙ 表示逐元素乘积。令 I_i ^* 表示 I_i 的期望版本,其中的掩码区域已被合适内容填充。即视频修复的目标是基于 V bar 修复得到
研究者使用内部学习方法实现视频修复。
这一通用方法是:
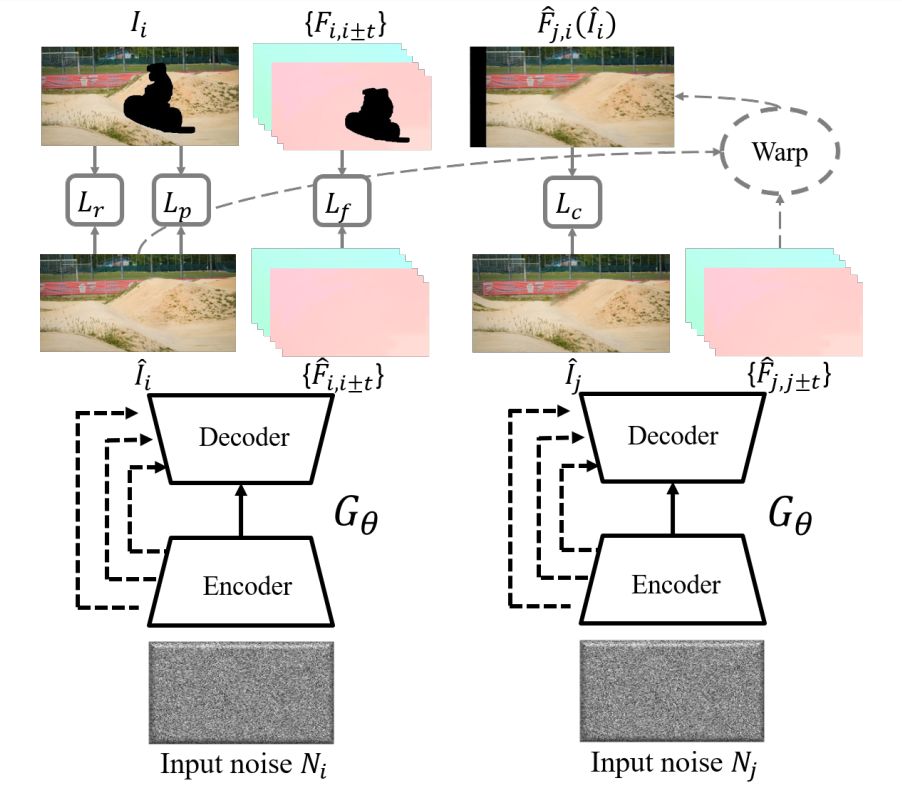
利用 V bar 作为训练数据,基于对应的噪声图 N_i 学习得到生成神经网络 G_θ,然后生成每一个目标帧 I_i ^*。
![]()
给出每个独立帧的输入随机噪声 N_i,生成网络 G_θ可同时预测帧 I_i hat 和光流
![]() 。G_θ 仅基于输入视频训练,不使用任何外部数据,并优化图像生成损失 L_r、感知损失 L_p、光流生成损失 L_f 和连贯性损失 L_c。
。G_θ 仅基于输入视频训练,不使用任何外部数据,并优化图像生成损失 L_r、感知损失 L_p、光流生成损失 L_f 和连贯性损失 L_c。
实验
研究者在之前研究所用的大量现实世界视频上对新方法进行了评估。
为了促进量化评估,研究者创建了额外的数据集,该数据集中每个视频都有前景掩码和真值背景帧。
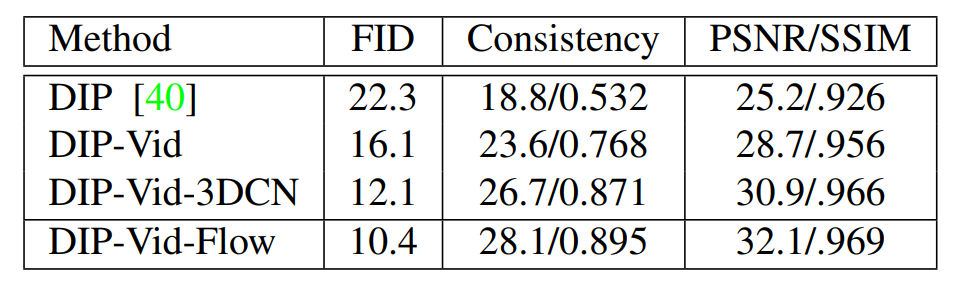
研究者首先对比了不同内部学习方法的视频修复质量。
具体而言,他们对比了其提出的最终方法 DIP-Vid-Flow,以及以下基线方法:
DIP:该基线方法直接将 DIP 框架逐帧应用于视频领域。
DIP-Vid:Adobe 提出的框架,不过该基线方法仅使用图像生成损失训练。
DIP-Vid-3DCN:除了直接使用 DIP 框架(具备纯 2D 卷积),研究者还修改了 DIP,使其使用 3D 卷积,并应用了图像生成损失。
下表 1 展示了不同方法的结果。
从所有指标上来看,针对整个视频的方法明显优于逐帧的 DIP 方法。
![]()
下图 4 是一些视觉示例。
DIP 通常从已知区域借取文本来填充空洞区域,以至于很多示例中出现结构不连贯现象。
![]()
图 4:不同内部学习框架的结果对比。逐帧的 DIP 方法倾向于从已知区域中借取纹理,生成不连贯的结构。
针对整个视频进行优化(DIP-Vid 和 DIP-Vid-3DCN)可以提升视觉质量,同时还能捕捉到时间连贯性(第 3、4 行的蓝色框)。
Adobe 提出的连贯性损失(DIP-Vid-Flow)提升了长期时间连贯性。
下图 5 展示了不同视频修复方法在两个视频序列上的时间连贯性。
![]()
图 5:时间连贯性对比。研究者将来自所有视频帧的固定行像素堆叠起来(黄线)。Adobe 提出的完整模型(DIP-Vid-Flow)具备最流畅的时间变换。
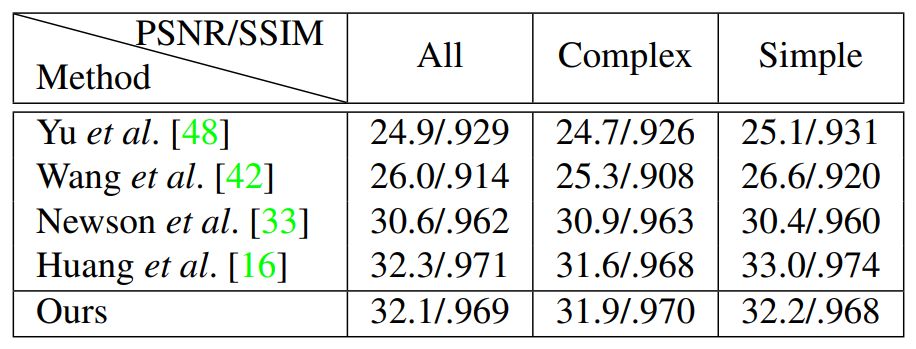
研究者对比了新方法和其他当前最优视频修复方法的性能,包括根据 Yu 等人提出的图像修复方法得到的视频修复结果、在视频修复数据上训练得到的 Vid2Vid 模型,以及分别来自 Newson 等人和 Huang 等人的两个当前最优视频修复方法。
下表 2 展示了这些方法在研究者提出的 Composed 数据集上的量化评估结果,度量指标为 PSNR 和 SSIM:
![]()
![]()
图 6:不同方法在 [16] 提供的视频(第 1 行)、[8] 提供的视频(第 2 行)和 Adobe 提出的 Composed 数据集(第 3 行)上的视频修复结果。相比于基于图像块的方法,Adobe 提出方法的生成结果更不容易出现变形。
-End-
CV细分方向交流群
添加极市小助手微信(ID : cv-mart),备注:研究方向-姓名-学校/公司-城市(如:目标检测-小极-北大-深圳),即可申请加入目标检测、目标跟踪、人脸、工业检测、医学影像、三维&SLAM、图像分割等极市技术交流群,更有每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流,一起来让思想之光照的更远吧~
![]()
△长按添加极市小助手
![]()
△长按关注极市平台
觉得有用麻烦给个在看啦~ ![]()



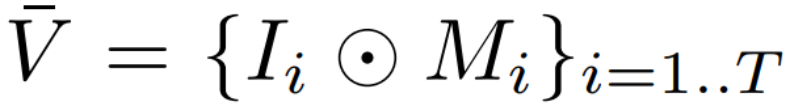
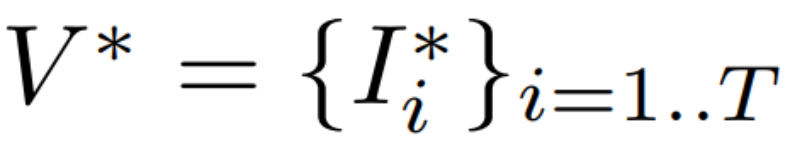
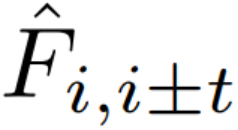 。G_θ 仅基于输入视频训练,不使用任何外部数据,并优化图像生成损失 L_r、感知损失 L_p、光流生成损失 L_f 和连贯性损失 L_c。
。G_θ 仅基于输入视频训练,不使用任何外部数据,并优化图像生成损失 L_r、感知损失 L_p、光流生成损失 L_f 和连贯性损失 L_c。