【今日Nature】DeepMind成功使用"深度强化学习"技术完美控制"核聚变反应堆"!
深度强化学习实验室
DeepMind在蛋白质折叠问题上实现巨大突破后,目标又转向核聚变了。
最近,它开发出了世界上第一个深度强化学习AI——可以在模拟环境和真正的核聚变装置(托卡马克)中实现对等离子体的自主控制。
陌生名词不要急,后面马上解释。
这比传统的计算机控制要更高效且精准,成果登上今天的Nature。

作为强化学习最具有挑战性的一个应用,这一成果也对加速可控核聚变有很大意义。
用强化学习控制核聚变反应
核聚变是未来最有潜力的清洁能源:只靠一个原子核就能产生巨大能量,除了相对少量的放射性废物(可在一个世纪内分解),不会产生任何温室气体。
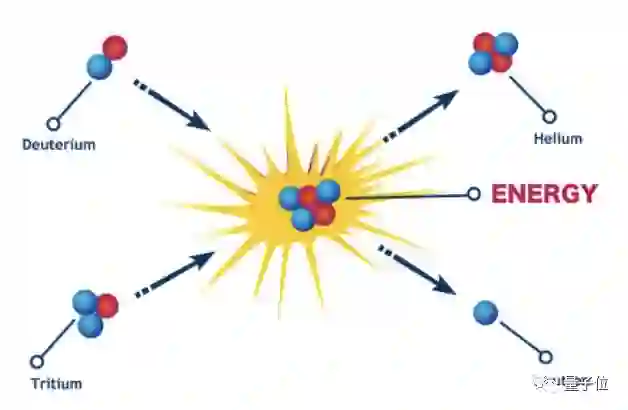
但要在地球上实现这一反应无比困难,需要制造一个极端高温和高压的条件,在其中创建一个由裸原子核组成的“等离子体”。
磁约束聚变装置——托卡马克(tokamak),是最有希望的一个实现方法。
它是一个环形反应堆,可以在超过1亿摄氏度的环境下把氢加热(superheat)成等离子体的状态。

△ 托卡马克内部图
由于等离子体温度太高,任何材料都无法容纳,要通过强大的磁场将它悬浮在托卡马克内部。
在操作磁线圈时必须非常仔细,因为一旦碰壁,就可能导致容器损坏,并减缓聚变反应。
而一个托卡马克装共有19个磁线圈,一秒需要调整线圈及其电压数千次。
传统的装置中,每个线圈配备单独的控制器。
每当研究人员想要改变等离子体的结构,尝试不同的形状以产生更高的能量时,就需要大量的工程和设计工作。
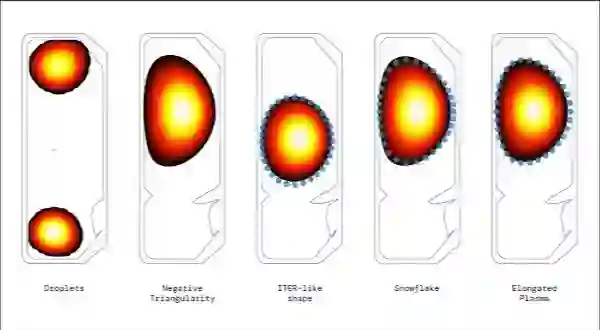
DeepMind这个强化学习系统则可以一次控制全部19个线圈,并精确操纵等离子体自主呈现各种形状,呈现产生科学家们一直在探索的更高能量的新配置:
比如下图中第二个“负三角”以及第四个“雪花”(这个形状可以通过将废能量分散到托卡马克壁上的不同接触点来降低冷却成本)。
以及第一个“droplets”,这也是第一次在托卡马克内同时稳定两个等离子体。
这个AI系统由DeepMind和瑞士洛桑联邦理工学院等离子体中心的物理学家共同完成。
瑞士中心的一位成员表示:“这里面有的形状已经逼近装置的极限,很可能对系统造成损坏,如果不是AI给的信心,我们可能不会冒这个险。”
这个AI是在模拟器中通过反复试验来训练的。
在核聚变研究中,模拟器非常有必要,因为目前运行的反应堆一次只能维持等离子体最多几秒钟,之后需要时间来重置。

不过一个问题是:该模拟器并没有准确捕获真实托卡马克中存在的所有变量,能迁移到真正的托卡马克上吗?
对此,DeepMind研究员表示,通过用随机数表示足够训练出一个灵活的AI。
另一个问题是:为了保持对托卡马克内部等离子体的控制,控制算法必须能够做出极快的决定,在短短几秒钟内对磁场进行调整。但许多人工智能系统在如此高速的环境下需要很长时间才能做出预测。
为此,该团队先训练了一个大型神经网络,它可以对磁场的变化如何塑造等离子体进行长程预测(longer-term prediction)。
然后用这个网络来训练一个远小得多的系统,学习执行第一个网络所推荐的决策的最佳方法。
这个较小的网络能与托卡马克控制系统直接交互,在不到50微秒(50百万分之一秒)的时间内做出决定。
最后,作者表示,虽然这个成果意义非凡,但只是朝着人类实现可控核聚变迈出了一小步。
比如实现一秒钟的实时运行需要模拟托卡马克数小时的时间,而它的条件每天都可能发生变化,算法还需各方面改进。
此外,还要看现在这个系统能否转移到更大的托卡马克装置中。
聚变能源何时实现商用还很难说,但DeepMind断言,人工智能可以加速这一过程。
不知道它能否再次像AlphaFold一样,在核聚变领域实现惊艳全世界的新成果。
拭目以待。
(也有一些网友在担心,要是控制核聚变的AI哪天想不开……)
论文地址:
https://www.nature.com/articles/s41586-021-04301-9
[1]https://venturebeat.com/2022/02/16/deepmind-applies-ai-to-controlling-nuclear-fusion-reactors/
本文转载自量子位公众号:
https://mp.weixin.qq.com/s?__biz=MzIzNjc1NzUzMw==&mid=2247612668&idx=4&sn=f22fd36a952a616fe9e162fddcdbb8d1&chksm=e8d18f8edfa60698d90ad83908fc4b875cd957ae17fd1f98b661456b73030d80d99897a2a927&mpshare=1&scene=1&srcid=0217N8VvR5ZbbLcGeOZy8uqP&sharer_sharetime=1645075464183&sharer_shareid=37d162eb8a1c29c81242c7fe00b99a76&exportkey=ATWS24ZBExfqqm9XeZc8K3Y%3D&acctmode=0&pass_ticket=EycUQrT0GlyHyxUfD6lcuWWmd588PcaK4NKnX7oOWA2yrgqGgRFn%2FkAz6eocVrc4&wx_header=0#rd



