赛尔讲坛第16期|微软研究院首席研究员楼建光博士讲座


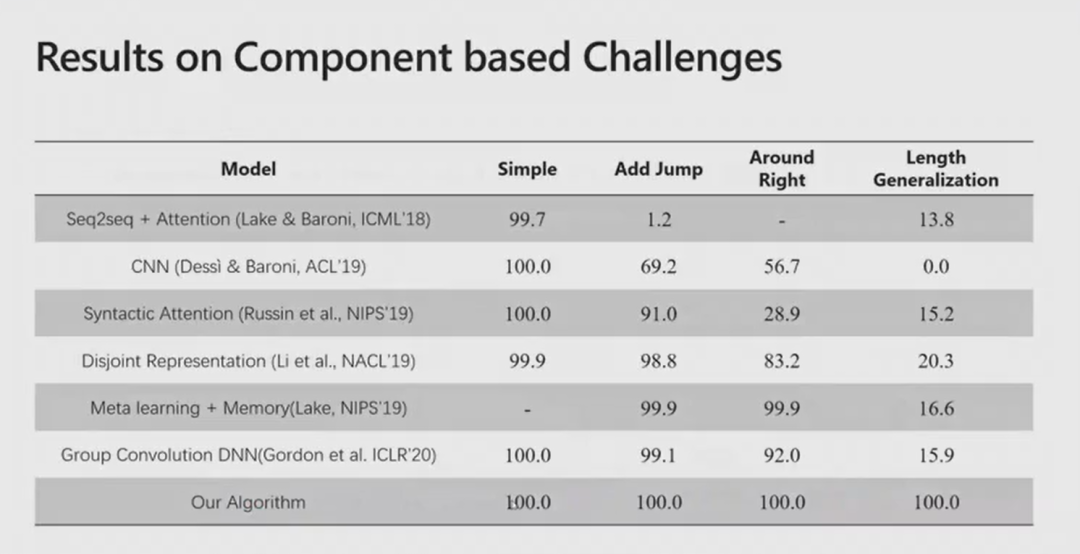

讲座过后,我中心老师同学向楼建光博士请教了组合泛化对已有机器学习泛化能力的拓展、组合泛化是否能够由机器学习规则以及组合泛化在实际应用场景的应用,楼建光博士对这些问题都给予了耐心细致的解答,大家都受益匪浅。
讲者简介:
楼建光博士,现为微软研究院首席研究员。多年来主要从事机器学习和人工智能技术在商业智能(Business Intelligence)数据分析、大规模在线软件系统分析(Software Analytics)等方面的研究与应用工作。研究兴趣包括交互式数据分析机器人、自动数据理解、程序自动生成、大规模在系统智能诊断与运维等方面。多项成果在微软公司的大规模在线系统实践中得到广泛应用。部分工作发表在人工智能、自然语言处理、计算机软件、系统及数据挖掘相关的知名国际会议。
本期责任编辑:刘 铭
理解语言,认知社会
以中文技术,助民族复兴
登录查看更多
相关内容

专知会员服务
65+阅读 · 2019年12月14日
Arxiv
0+阅读 · 2022年4月18日
Arxiv
0+阅读 · 2022年4月17日
Arxiv
0+阅读 · 2022年4月17日
Arxiv
12+阅读 · 2020年12月14日



相关VIP内容
专知会员服务
65+阅读 · 2019年12月14日
相关资讯
相关论文
Arxiv
0+阅读 · 2022年4月18日
Arxiv
0+阅读 · 2022年4月17日
Arxiv
0+阅读 · 2022年4月17日
Arxiv
12+阅读 · 2020年12月14日