【CVPR2020】ORG-TRL:基于物体关系图和教师推荐学习的视频描述

导语
人工智能可以成为我们的专属视频解说员吗?
“看图说话”是小学作文必备技能,而“视频描述”,可谓升级版的“看图说话”,即让计算机对视频生成一段描述。任务看似简单,难度却不容小觑!与“图片”中单一的静态空间信息不同,“视频”同时结合了空间信息、时序信息以及语言信息。“视频描述”不仅要求充分提取视频中关键的视觉信息,还需构建从视觉到语言的映射关系。
为了更好地识别视频中的关系信息且达成更生动的描述效果,自动化所视频内容安全团队构建了全新的视频描述系统,让我们跟随下面的文章一探究竟吧!

视频描述任务作为一种结合视觉与语言的高层任务,近年来得到研究者的广泛关注。该任务的关键包括如何充分提取视频中关键的视觉信息和如何构建从视觉到语言的映射关系。自动化所视频内容安全团队张子琦、史雅雅博士等人针对当前视频描述任务中,视觉层面缺少物体之间的交互关系,以及语言层面缺乏与内容相关单词的充分训练等问题,提出了基于物体关系图和教师推荐学习的视频描述系统。图1为该系统的框架图,该系统利用图卷积神经网络获取视频中物体间的相互关联,同时利用知识蒸馏的方法将外部语言模型的知识传授给视频描述模型。
团队所提出的模型和训练策略,能够充分挖掘物体之间的关联,有效吸纳外部语言模型的语言学知识。在三个大型视频描述数据集(MSVD、MSR-VTT和VATEX)上均验证了该系统的有效性。相关成果被CVPR 2020录用。
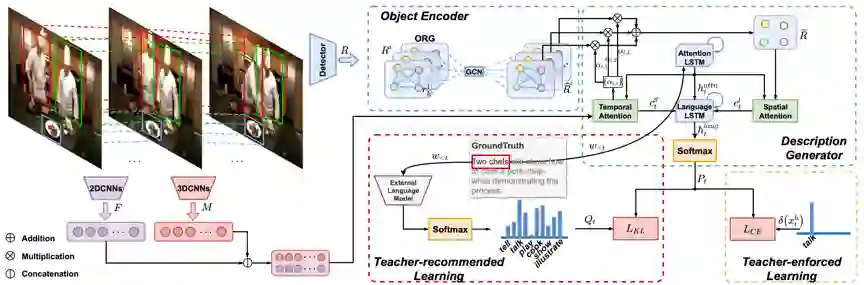
图1:ORG-TRL系统框架图
模型与训练策略介绍
物体关系图(ORG)模型利用图卷积神经网络构建起物体之间的关系图网络,通过关系推理过程以丰富视频的视觉表征。具体来说,研究团队提出了两种物体关系图结构(如图2所示):
局部关系图(P-ORG)构建单帧物体的关系,帧与帧之间没有连接;
全局关系图(C-ORG)将整个视频中的物体进行关联,从而能够获得长时的物体间依赖关系。
此外,团队提出的相关节点更新方法,消除了对于大部分与描述无关的物体所带来的噪声干扰问题。
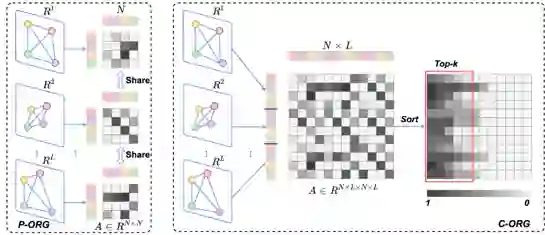
图2: 局部和全局物体关系图
教师推荐学习(TRL)训练策略通过知识蒸馏方法,将外部语言模型的语言学知识传递给描述模型。TRL在原有teacher-enforced learning的训练过程的基础上,配合在大型语料库上预训练的语言模型生成的软目标(如图3所示)进行teacher-recommended learning,在每一步的训练中同时学到了数十倍的知识,很好地缓解了由于文本长尾问题所带来的内容相关词汇训练不足的问题。
此外,外部语言模型仅参与到训练阶段,不会给系统测试及实际应用增加负担。

图3:由外部语言模型生成的建议词汇,作为训练的软目标




